溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關如何理解 SQL及Thrift,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
1
Hive SQL &Spark SQL
這是一個復雜的歷史,基本上是一個“忒修斯船”(Ship of Theseus)的故事。最開始的時候,Spark SQL的代碼幾乎全部都是Hive的照搬,隨著時間的推移,Hive的代碼被逐漸替換,直到幾乎沒有原始的Hive代碼保留。
參考:https://en.wikipedia.org/wiki/Ship_of_Theseus
Spark最開始打包的是Shark和SharkServer(Spark和Hive的結合體)。那個時候,這個結合體包含了大量的Hive代碼。SharkServer就是Hive,它解析HiveQL,在Hive中進行優化,讀取Hadoop的輸入格式,到最后Shark甚至在Spark引擎上運行Hadoop風格的MapReduce任務。這一點在當時來說其實很酷的,因為它提供了一種無需進行任何編程就能使用Spark的方式,HQL做到了。不幸的是,MapReduce和Hive并不能完全融入Spark生態系統,2014年7月,社區宣布Shark的開發在Spark1.0的時終止,因為Spark開始轉向更多Spark原生的SQL表達式。同時社區將重心轉向原生的Spark SQL的開發,并且對已有的Hive用戶提供過渡方案Hive on Spark來進行將Hive作業遷移到Spark引擎執行。
參考:https://github.com/amplab/shark/wiki/Shark-User-Guidehttps://databricks.com/blog/2014/07/01/shark-spark-sql-hive-on-spark-and-the-future-of-sql-on-spark.html
Spark引入SchemaRDDs,Dataframes和DataSets來表示分布式數據集。有了這些,一個名為Catalyst的全新Spark原生優化引擎引入到Spark,它是一個Tree Manipulation Framework,為從GraphFrames到Structured Streaming的所有查詢優化提供依據。Catalyst的出現意味著開始丟棄MapReduce風格的作業執行,而是可以構建和運行Spark優化的執行計劃。此外,Spark發布了一個新的API,它允許我們構建名為“DataSources”的Spark-Aware接口。DataSources的靈活性結束了Spark對Hadoop輸入格式的依賴(盡管它們仍受支持)。DataSource可以直接訪問Spark生成的查詢計劃,并執行謂詞下推和其他優化。
Hive Parser開始被Spark Parser替代,Spark SQL仍然支持HQL,但語法已經大大擴展。Spark SQL現在可以運行所有TPC-DS查詢,以及一系列Spark特定的擴展。(在開發過程中有一段時間你必須在HiveContext和SqlContext之間進行選擇,兩者都有不同的解析器,但我們不再討論它了。今天所有請求都以SparkSession開頭)。現在Spark幾乎沒有剩下Hive代碼。雖然Sql Thrift Server仍然構建在HiveServer2代碼上,但幾乎所有的內部實現都是完全Spark原生的。
2
Spark Thrift Server介紹
Thrift Server是Spark提供的一種JDBC/ODBC訪問Spark SQL的服務,它是基于Hive1.2.1的HiveServer2實現的,只是底層的SQL執行改為了Spark,同時是使用spark submit啟動的服務。同時通過Spark Thrift JDBC/ODBC接口也可以較為方便的直接訪問同一個Hadoop集群中的Hive表,通過配置Thrift服務指向連接到Hive的metastore服務即可。
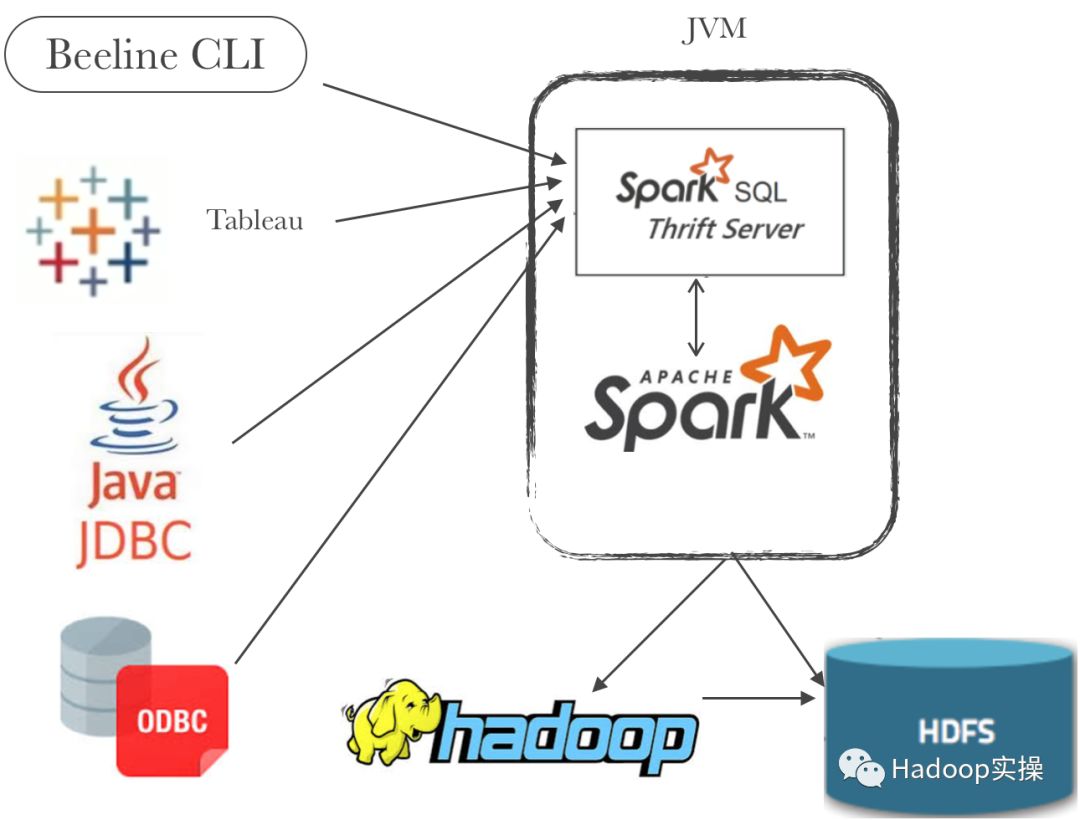
參考:http://spark.apache.org/docs/latest/sql-distributed-sql-engine.html#running-the-thrift-jdbcodbc-server

3
Spark Thrift的缺陷
1.不支持用戶模擬,即Thrift Server并不能以提交查詢的用戶取代啟動Thrift Server的用戶來執行查詢語句,具體對應到Hive的hive.server2.enable.doAs參數不支持。參考:
https://issues.apache.org/jira/browse/SPARK-5159https://issues.apache.org/jira/browse/SPARK-11248https://issues.apache.org/jira/browse/SPARK-21918
2.因為上述第一點不支持用戶模擬,導致任何查詢都是同一個用戶,所有沒辦法控制Spark SQL的權限。
3.單點問題,所有Spark SQL查詢都走唯一一個Spark Thrift節點上的同一個Spark Driver,任何故障都會導致這個唯一的Spark Thrift節點上的所有作業失敗,從而需要重啟Spark Thrift Server。
4.并發差,上述第三點原因,因為所有的查詢都要通過一個Spark Driver,導致這個Driver是瓶頸,于是限制了Spark SQL作業的并發度。
因為以上限制,主要是安全性上的(即上面描述的第一和第二點),所以CDH的企業版在打包Spark的時候將Spark Thrift服務并沒有打包。如果用戶要在CDH中使用Spark Thrift服務,則需要自己打包或單獨添加這個服務,但Cloudera官方并不會提供支持服務。可以參考如下jira:
https://issues.cloudera.org/browse/DISTRO-817
關于Spark Thrift的缺陷,也可以參考網易的描述:

所以網易才自己做了一個Thrift服務取名Kyuubi,Fayson在后面的文章中會用到,參考:
http://blog.itpub.net/31077337/viewspace-2212906/
4
Spark Thrift在現有CDH5中的使用
從CDH5.10到最新的CDH5.16.1,都支持同時安裝Spark1.6以及最新的Spark2.x,Spark2具體包含從Spark2.0到最新的Spark2.4都可以安裝到CDH5中。具體可以參考Cloudera官網的說明:
https://www.cloudera.com/documentation/spark2/latest/topics/spark2_requirements.html#cdh_versions

在CDH5中通過自己單獨安裝的方式運行Thrift服務現在已經調通并在使用的是如下版本組合:
1.在CDH5中安裝Spark1.6的Thrift服務,參考《0079-如何在CDH中啟用Spark Thrift》
2.在CDH5中安裝Spark2.1的Thrift服務,參考《0280-如何在Kerberos環境下的CDH集群部署Spark2.1的Thrift及spark-sql客戶端》

從Spark2.2開始到最新的Spark2.4,因為變化較大,不能夠采用上述兩種辦法直接替換jar包的方式實現,更多的依賴問題導致需要重新編譯或者修改更多的東西才能在CDH5中使用最新的Spark2.4的Thrift。
看完上述內容,你們對如何理解 SQL及Thrift有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





