溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何理解網站處理數據交換時的序列化和反序列化”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
#摘要
序列化和反序列化幾乎是工程師們每天都要面對的事情,但是要精確掌握這兩個概念并不容易:一方面,它們往往作為框架的一部分出現而湮沒在框架之中;另一方面,它們會以其他更容易理解的概念出現,例如加密、持久化。然而,序列化和反序列化的選型卻是系統設計或重構一個重要的環節,在分布式、大數據量系統設計里面更為顯著。恰當的序列化協議不僅可以提高系統的通用性、強健性、安全性、優化系統性能,而且會讓系統更加易于調試、便于擴展。本文從多個角度去分析和講解“序列化和反序列化”,并對比了當前流行的幾種序列化協議,期望對讀者做序列化選型有所幫助。
簡介
文章作者服務于美團推薦與個性化組,該組致力于為美團用戶提供每天billion級別的高質量個性化推薦以及排序服務。從Terabyte級別的用戶行為數據,到Gigabyte級別的Deal/Poi數據;從對實時性要求毫秒以內的用戶實時地理位置數據,到定期后臺job數據,推薦與重排序系統需要多種類型的數據服務。推薦與重排序系統客戶包括各種內部服務、美團客戶端、美團網站。為了提供高質量的數據服務,為了實現與上下游各系統進行良好的對接,序列化和反序列化的選型往往是我們做系統設計的一個重要考慮因素。
本文內容按如下方式組織:
第一部分給出了序列化和反序列化的定義,以及其在通訊協議中所處的位置。
第二部分從使用者的角度探討了序列化協議的一些特性。
第三部分描述在具體的實施過程中典型的序列化組件,并與數據庫組建進行了類比。
第四部分分別講解了目前常見的幾種序列化協議的特性,應用場景,并對相關組件進行舉例。
最后一部分,基于各種協議的特性,以及相關benchmark數據,給出了作者的技術選型建議。
#一、定義以及相關概念
互聯網的產生帶來了機器間通訊的需求,而互聯通訊的雙方需要采用約定的協議,序列化和反序列化屬于通訊協議的一部分。通訊協議往往采用分層模型,不同模型每層的功能定義以及顆粒度不同,例如:TCP/IP協議是一個四層協議,而OSI模型卻是七層協議模型。在OSI七層協議模型中展現層(Presentation Layer)的主要功能是把應用層的對象轉換成一段連續的二進制串,或者反過來,把二進制串轉換成應用層的對象--這兩個功能就是序列化和反序列化。一般而言,TCP/IP協議的應用層對應與OSI七層協議模型的應用層,展示層和會話層,所以序列化協議屬于TCP/IP協議應用層的一部分。本文對序列化協議的講解主要基于OSI七層協議模型。
序列化: 將數據結構或對象轉換成二進制串的過程
反序列化:將在序列化過程中所生成的二進制串轉換成數據結構或者對象的過程
數據結構、對象與二進制串
不同的計算機語言中,數據結構,對象以及二進制串的表示方式并不相同。
數據結構和對象:對于類似Java這種完全面向對象的語言,工程師所操作的一切都是對象(Object),來自于類的實例化。在Java語言中最接近數據結構的概念,就是POJO(Plain Old Java Object)或者Javabean--那些只有setter/getter方法的類。而在C++這種半面向對象的語言中,數據結構和struct對應,對象和class對應。
二進制串:序列化所生成的二進制串指的是存儲在內存中的一塊數據。C++語言具有內存操作符,所以二進制串的概念容易理解,例如,C++語言的字符串可以直接被傳輸層使用,因為其本質上就是以'\0'結尾的存儲在內存中的二進制串。在Java語言里面,二進制串的概念容易和String混淆。實際上String 是Java的一等公民,是一種特殊對象(Object)。對于跨語言間的通訊,序列化后的數據當然不能是某種語言的特殊數據類型。二進制串在Java里面所指的是byte[],byte是Java的8中原生數據類型之一(Primitive data types)。
#二、序列化協議特性
每種序列化協議都有優點和缺點,它們在設計之初有自己獨特的應用場景。在系統設計的過程中,需要考慮序列化需求的方方面面,綜合對比各種序列化協議的特性,最終給出一個折衷的方案。
通用性
通用性有兩個層面的意義:
第一、技術層面,序列化協議是否支持跨平臺、跨語言。如果不支持,在技術層面上的通用性就大大降低了。
第二、流行程度,序列化和反序列化需要多方參與,很少人使用的協議往往意味著昂貴的學習成本;另一方面,流行度低的協議,往往缺乏穩定而成熟的跨語言、跨平臺的公共包。
強健性/魯棒性
以下兩個方面的原因會導致協議不夠強健:
第一、成熟度不夠,一個協議從制定到實施,到最后成熟往往是一個漫長的階段。協議的強健性依賴于大量而全面的測試,對于致力于提供高質量服務的系統,采用處于測試階段的序列化協議會帶來很高的風險。
第二、語言/平臺的不公平性。為了支持跨語言、跨平臺的功能,序列化協議的制定者需要做大量的工作;但是,當所支持的語言或者平臺之間存在難以調和的特性的時候,協議制定者需要做一個艱難的決定--支持更多人使用的語言/平臺,亦或支持更多的語言/平臺而放棄某個特性。當協議的制定者決定為某種語言或平臺提供更多支持的時候,對于使用者而言,協議的強健性就被犧牲了。
可調試性/可讀性
序列化和反序列化的數據正確性和業務正確性的調試往往需要很長的時間,良好的調試機制會大大提高開發效率。序列化后的二進制串往往不具備人眼可讀性,為了驗證序列化結果的正確性,寫入方不得同時撰寫反序列化程序,或提供一個查詢平臺--這比較費時;另一方面,如果讀取方未能成功實現反序列化,這將給問題查找帶來了很大的挑戰--難以定位是由于自身的反序列化程序的bug所導致還是由于寫入方序列化后的錯誤數據所導致。對于跨公司間的調試,由于以下原因,問題會顯得更嚴重:
第一、支持不到位,跨公司調試在問題出現后可能得不到及時的支持,這大大延長了調試周期。
第二、訪問限制,調試階段的查詢平臺未必對外公開,這增加了讀取方的驗證難度。
如果序列化后的數據人眼可讀,這將大大提高調試效率, XML和JSON就具有人眼可讀的優點。
性能
性能包括兩個方面,時間復雜度和空間復雜度:
第一、空間開銷(Verbosity), 序列化需要在原有的數據上加上描述字段,以為反序列化解析之用。如果序列化過程引入的額外開銷過高,可能會導致過大的網絡,磁盤等各方面的壓力。對于海量分布式存儲系統,數據量往往以TB為單位,巨大的的額外空間開銷意味著高昂的成本。
第二、時間開銷(Complexity),復雜的序列化協議會導致較長的解析時間,這可能會使得序列化和反序列化階段成為整個系統的瓶頸。
可擴展性/兼容性
移動互聯時代,業務系統需求的更新周期變得更快,新的需求不斷涌現,而老的系統還是需要繼續維護。如果序列化協議具有良好的可擴展性,支持自動增加新的業務字段,而不影響老的服務,這將大大提供系統的靈活度。
安全性/訪問限制
在序列化選型的過程中,安全性的考慮往往發生在跨局域網訪問的場景。當通訊發生在公司之間或者跨機房的時候,出于安全的考慮,對于跨局域網的訪問往往被限制為基于HTTP/HTTPS的80和443端口。如果使用的序列化協議沒有兼容而成熟的HTTP傳輸層框架支持,可能會導致以下三種結果之一:
第一、因為訪問限制而降低服務可用性。
第二、被迫重新實現安全協議而導致實施成本大大提高。
第三、開放更多的防火墻端口和協議訪問,而犧牲安全性。
#三、序列化和反序列化的組件
典型的序列化和反序列化過程往往需要如下組件:
IDL(Interface description language)文件:參與通訊的各方需要對通訊的內容需要做相關的約定(Specifications)。為了建立一個與語言和平臺無關的約定,這個約定需要采用與具體開發語言、平臺無關的語言來進行描述。這種語言被稱為接口描述語言(IDL),采用IDL撰寫的協議約定稱之為IDL文件。
IDL Compiler:IDL文件中約定的內容為了在各語言和平臺可見,需要有一個編譯器,將IDL文件轉換成各語言對應的動態庫。
Stub/Skeleton Lib:負責序列化和反序列化的工作代碼。Stub是一段部署在分布式系統客戶端的代碼,一方面接收應用層的參數,并對其序列化后通過底層協議棧發送到服務端,另一方面接收服務端序列化后的結果數據,反序列化后交給客戶端應用層;Skeleton部署在服務端,其功能與Stub相反,從傳輸層接收序列化參數,反序列化后交給服務端應用層,并將應用層的執行結果序列化后最終傳送給客戶端Stub。
Client/Server:指的是應用層程序代碼,他們面對的是IDL所生存的特定語言的class或struct。
底層協議棧和互聯網:序列化之后的數據通過底層的傳輸層、網絡層、鏈路層以及物理層協議轉換成數字信號在互聯網中傳遞。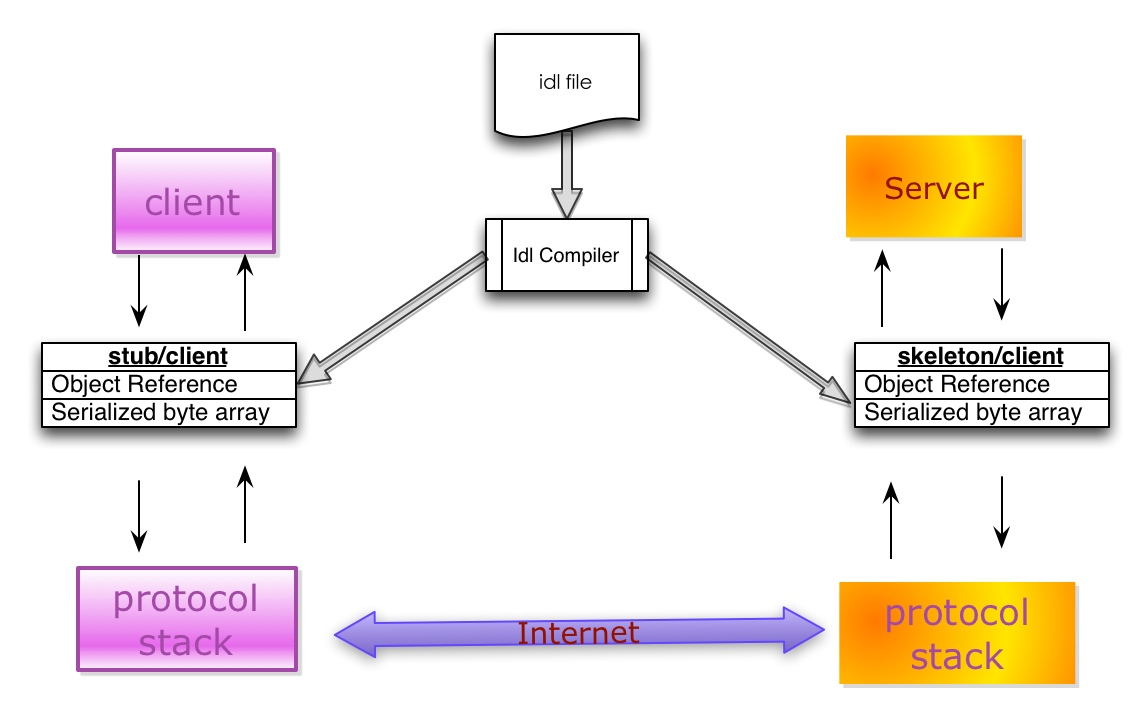
序列化組件與數據庫訪問組件的對比
數據庫訪問對于很多工程師來說相對熟悉,所用到的組件也相對容易理解。下表類比了序列化過程中用到的部分組件和數據庫訪問組件的對應關系,以便于大家更好的把握序列化相關組件的概念。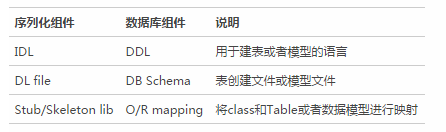
#四、幾種常見的序列化和反序列化協議
互聯網早期的序列化協議主要有COM和CORBA。
COM主要用于Windows平臺,并沒有真正實現跨平臺,另外COM的序列化的原理利用了編譯器中虛表,使得其學習成本巨大(想一下這個場景, 工程師需要是簡單的序列化協議,但卻要先掌握語言編譯器)。由于序列化的數據與編譯器緊耦合,擴展屬性非常麻煩。
CORBA是早期比較好的實現了跨平臺,跨語言的序列化協議。COBRA的主要問題是參與方過多帶來的版本過多,版本之間兼容性較差,以及使用復雜晦澀。這些政治經濟,技術實現以及早期設計不成熟的問題,最終導致COBRA的漸漸消亡。J2SE 1.3之后的版本提供了基于CORBA協議的RMI-IIOP技術,這使得Java開發者可以采用純粹的Java語言進行CORBA的開發。
這里主要介紹和對比幾種當下比較流行的序列化協議,包括XML、JSON、Protobuf、Thrift和Avro。
一個例子
如前所述,序列化和反序列化的出現往往晦澀而隱蔽,與其他概念之間往往相互包容。為了更好了讓大家理解序列化和反序列化的相關概念在每種協議里面的具體實現,我們將一個例子穿插在各種序列化協議講解中。在該例子中,我們希望將一個用戶信息在多個系統里面進行傳遞;在應用層,如果采用Java語言,所面對的類對象如下所示:
Java Code復制內容到剪貼板
class Address
{
private String city;
private String postcode;
private String street;
}
public class UserInfo
{
private Integer userid;
private String name;
private List<Address> address;
}
XML&SOAP
XML是一種常用的序列化和反序列化協議,具有跨機器,跨語言等優點。 XML歷史悠久,其1.0版本早在1998年就形成標準,并被廣泛使用至今。XML的最初產生目標是對互聯網文檔(Document)進行標記,所以它的設計理念中就包含了對于人和機器都具備可讀性。 但是,當這種標記文檔的設計被用來序列化對象的時候,就顯得冗長而復雜(Verbose and Complex)。 XML本質上是一種描述語言,并且具有自我描述(Self-describing)的屬性,所以XML自身就被用于XML序列化的IDL。 標準的XML描述格式有兩種:DTD(Document Type Definition)和XSD(XML Schema Definition)。作為一種人眼可讀(Human-readable)的描述語言,XML被廣泛使用在配置文件中,例如O/R mapping、 Spring Bean Configuration File 等。
SOAP(Simple Object Access protocol) 是一種被廣泛應用的,基于XML為序列化和反序列化協議的結構化消息傳遞協議。SOAP在互聯網影響如此大,以至于我們給基于SOAP的解決方案一個特定的名稱--Web service。SOAP雖然可以支持多種傳輸層協議,不過SOAP最常見的使用方式還是XML+HTTP。SOAP協議的主要接口描述語言(IDL)是WSDL(Web Service Description Language)。SOAP具有安全、可擴展、跨語言、跨平臺并支持多種傳輸層協議。如果不考慮跨平臺和跨語言的需求,XML的在某些語言里面具有非常簡單易用的序列化使用方法,無需IDL文件和第三方編譯器, 例如Java+XStream。
自我描述與遞歸
SOAP是一種采用XML進行序列化和反序列化的協議,它的IDL是WSDL. 而WSDL的描述文件是XSD,而XSD自身是一種XML文件。 這里產生了一種有趣的在數學上稱之為“遞歸”的問題,這種現象往往發生在一些具有自我屬性(Self-description)的事物上。
IDL文件舉例
采用WSDL描述上述用戶基本信息的例子如下:
代碼如下:
<xsd:complexType name='Address'>
<xsd:attribute name='city' type='xsd:string' />
<xsd:attribute name='postcode' type='xsd:string' />
<xsd:attribute name='street' type='xsd:string' />
</xsd:complexType>
<xsd:complexType name='UserInfo'>
<xsd:sequence>
<xsd:element name='address' type='tns:Address'/>
<xsd:element name='address1' type='tns:Address'/>
</xsd:sequence>
<xsd:attribute name='userid' type='xsd:int' />
<xsd:attribute name='name' type='xsd:string' />
</xsd:complexType>
典型應用場景和非應用場景
SOAP協議具有廣泛的群眾基礎,基于HTTP的傳輸協議使得其在穿越防火墻時具有良好安全特性,XML所具有的人眼可讀(Human-readable)特性使得其具有出眾的可調試性,互聯網帶寬的日益劇增也大大彌補了其空間開銷大(Verbose)的缺點。對于在公司之間傳輸數據量相對小或者實時性要求相對低(例如秒級別)的服務是一個好的選擇。
由于XML的額外空間開銷大,序列化之后的數據量劇增,對于數據量巨大序列持久化應用常景,這意味著巨大的內存和磁盤開銷,不太適合XML。另外,XML的序列化和反序列化的空間和時間開銷都比較大,對于對性能要求在ms級別的服務,不推薦使用。WSDL雖然具備了描述對象的能力,SOAP的S代表的也是simple,但是SOAP的使用絕對不簡單。對于習慣于面向對象編程的用戶,WSDL文件不直觀。
JSON(Javascript Object Notation)
JSON起源于弱類型語言Javascript, 它的產生來自于一種稱之為"Associative array"的概念,其本質是就是采用"Attribute-value"的方式來描述對象。實際上在Javascript和PHP等弱類型語言中,類的描述方式就是Associative array。JSON的如下優點,使得它快速成為最廣泛使用的序列化協議之一:
1、這種Associative array格式非常符合工程師對對象的理解。
2、它保持了XML的人眼可讀(Human-readable)的優點。
3、相對于XML而言,序列化后的數據更加簡潔。 來自于的以下鏈接的研究表明:XML所產生序列化之后文件的大小接近JSON的兩倍。http://www.codeproject.com/Articles/604720/JSON-vs-XML-Some-hard-numbers-about-verbosity
4、它具備Javascript的先天性支持,所以被廣泛應用于Web browser的應用常景中,是Ajax的事實標準協議。
5、與XML相比,其協議比較簡單,解析速度比較快。
6、松散的Associative array使得其具有良好的可擴展性和兼容性。
IDL悖論
JSON實在是太簡單了,或者說太像各種語言里面的類了,所以采用JSON進行序列化不需要IDL。這實在是太神奇了,存在一種天然的序列化協議,自身就實現了跨語言和跨平臺。然而事實沒有那么神奇,之所以產生這種假象,來自于兩個原因:
第一、Associative array在弱類型語言里面就是類的概念,在PHP和Javascript里面Associative array就是其class的實際實現方式,所以在這些弱類型語言里面,JSON得到了非常良好的支持。
第二、IDL的目的是撰寫IDL文件,而IDL文件被IDL Compiler編譯后能夠產生一些代碼(Stub/Skeleton),而這些代碼是真正負責相應的序列化和反序列化工作的組件。 但是由于Associative array和一般語言里面的class太像了,他們之間形成了一一對應關系,這就使得我們可以采用一套標準的代碼進行相應的轉化。對于自身支持Associative array的弱類型語言,語言自身就具備操作JSON序列化后的數據的能力;對于Java這強類型語言,可以采用反射的方式統一解決,例如Google提供的Gson。
典型應用場景和非應用場景
JSON在很多應用場景中可以替代XML,更簡潔并且解析速度更快。典型應用場景包括:
1、公司之間傳輸數據量相對小,實時性要求相對低(例如秒級別)的服務。
2、基于Web browser的Ajax請求。
3、由于JSON具有非常強的前后兼容性,對于接口經常發生變化,并對可調式性要求高的場景,例如Mobile app與服務端的通訊。
4、由于JSON的典型應用場景是JSON+HTTP,適合跨防火墻訪問。
總的來說,采用JSON進行序列化的額外空間開銷比較大,對于大數據量服務或持久化,這意味著巨大的內存和磁盤開銷,這種場景不適合。沒有統一可用的IDL降低了對參與方的約束,實際操作中往往只能采用文檔方式來進行約定,這可能會給調試帶來一些不便,延長開發周期。 由于JSON在一些語言中的序列化和反序列化需要采用反射機制,所以在性能要求為ms級別,不建議使用。
IDL文件舉例
以下是UserInfo序列化之后的一個例子:
代碼如下:
{"userid":1,"name":"messi","address":[{"city":"北京","postcode":"1000000","street":"wangjingdonglu"}]}
Thrift
Thrift是Facebook開源提供的一個高性能,輕量級RPC服務框架,其產生正是為了滿足當前大數據量、分布式、跨語言、跨平臺數據通訊的需求。 但是,Thrift并不僅僅是序列化協議,而是一個RPC框架。相對于JSON和XML而言,Thrift在空間開銷和解析性能上有了比較大的提升,對于對性能要求比較高的分布式系統,它是一個優秀的RPC解決方案;但是由于Thrift的序列化被嵌入到Thrift框架里面,Thrift框架本身并沒有透出序列化和反序列化接口,這導致其很難和其他傳輸層協議共同使用(例如HTTP)。
典型應用場景和非應用場景
對于需求為高性能,分布式的RPC服務,Thrift是一個優秀的解決方案。它支持眾多語言和豐富的數據類型,并對于數據字段的增刪具有較強的兼容性。所以非常適用于作為公司內部的面向服務構建(SOA)的標準RPC框架。
不過Thrift的文檔相對比較缺乏,目前使用的群眾基礎相對較少。另外由于其Server是基于自身的Socket服務,所以在跨防火墻訪問時,安全是一個顧慮,所以在公司間進行通訊時需要謹慎。 另外Thrift序列化之后的數據是Binary數組,不具有可讀性,調試代碼時相對困難。最后,由于Thrift的序列化和框架緊耦合,無法支持向持久層直接讀寫數據,所以不適合做數據持久化序列化協議。
IDL文件舉例
代碼如下:
struct Address
{
1: required string city;
2: optional string postcode;
3: optional string street;
}
struct UserInfo
{
1: required string userid;
2: required i32 name;
3: optional list<Address> address;
}
Protobuf
Protobuf具備了優秀的序列化協議的所需的眾多典型特征:
1、標準的IDL和IDL編譯器,這使得其對工程師非常友好。
2、序列化數據非常簡潔,緊湊,與XML相比,其序列化之后的數據量約為1/3到1/10。
3、解析速度非常快,比對應的XML快約20-100倍。
4、提供了非常友好的動態庫,使用非常簡介,反序列化只需要一行代碼。
Protobuf是一個純粹的展示層協議,可以和各種傳輸層協議一起使用;Protobuf的文檔也非常完善。 但是由于Protobuf產生于Google,所以目前其僅僅支持Java、C++、Python三種語言。另外Protobuf支持的數據類型相對較少,不支持常量類型。由于其設計的理念是純粹的展現層協議(Presentation Layer),目前并沒有一個專門支持Protobuf的RPC框架。
典型應用場景和非應用場景
Protobuf具有廣泛的用戶基礎,空間開銷小以及高解析性能是其亮點,非常適合于公司內部的對性能要求高的RPC調用。由于Protobuf提供了標準的IDL以及對應的編譯器,其IDL文件是參與各方的非常強的業務約束,另外,Protobuf與傳輸層無關,采用HTTP具有良好的跨防火墻的訪問屬性,所以Protobuf也適用于公司間對性能要求比較高的場景。由于其解析性能高,序列化后數據量相對少,非常適合應用層對象的持久化場景。
它的主要問題在于其所支持的語言相對較少,另外由于沒有綁定的標準底層傳輸層協議,在公司間進行傳輸層協議的調試工作相對麻煩。
IDL文件舉例
代碼如下:
message Address
{
required string city=1;
optional string postcode=2;
optional string street=3;
}
message UserInfo
{
required string userid=1;
required string name=2;
repeated Address address=3;
}
Avro
Avro的產生解決了JSON的冗長和沒有IDL的問題,Avro屬于Apache Hadoop的一個子項目。 Avro提供兩種序列化格式:JSON格式或者Binary格式。Binary格式在空間開銷和解析性能方面可以和Protobuf媲美,JSON格式方便測試階段的調試。 Avro支持的數據類型非常豐富,包括C++語言里面的union類型。Avro支持JSON格式的IDL和類似于Thrift和Protobuf的IDL(實驗階段),這兩者之間可以互轉。Schema可以在傳輸數據的同時發送,加上JSON的自我描述屬性,這使得Avro非常適合動態類型語言。 Avro在做文件持久化的時候,一般會和Schema一起存儲,所以Avro序列化文件自身具有自我描述屬性,所以非常適合于做Hive、Pig和MapReduce的持久化數據格式。對于不同版本的Schema,在進行RPC調用的時候,服務端和客戶端可以在握手階段對Schema進行互相確認,大大提高了最終的數據解析速度。
典型應用場景和非應用場景
Avro解析性能高并且序列化之后的數據非常簡潔,比較適合于高性能的序列化服務。
由于Avro目前非JSON格式的IDL處于實驗階段,而JSON格式的IDL對于習慣于靜態類型語言的工程師來說不直觀。
IDL文件舉例
代碼如下:
protocol Userservice {
record Address {
string city;
string postcode;
string street;
}
record UserInfo {
string name;
int userid;
array<Address> address = [];
}
}
所對應的JSON Schema格式如下:
JavaScript Code復制內容到剪貼板
{
"protocol" : "Userservice",
"namespace" : "org.apache.avro.ipc.specific",
"version" : "1.0.5",
"types" : [ {
"type" : "record",
"name" : "Address",
"fields" : [ {
"name" : "city",
"type" : "string"
}, {
"name" : "postcode",
"type" : "string"
}, {
"name" : "street",
"type" : "string"
} ]
}, {
"type" : "record",
"name" : "UserInfo",
"fields" : [ {
"name" : "name",
"type" : "string"
}, {
"name" : "userid",
"type" : "int"
}, {
"name" : "address",
"type" : {
"type" : "array",
"items" : "Address"
},
"default" : [ ]
} ]
} ],
"messages" : { }
}
#五、Benchmark以及選型建議
##Benchmark
以下數據來自https://code.google.com/p/thrift-protobuf-compare/wiki/Benchmarking
解析性能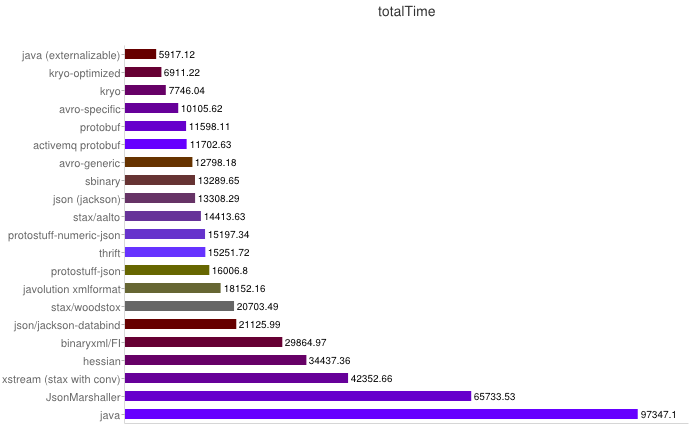
序列化之空間開銷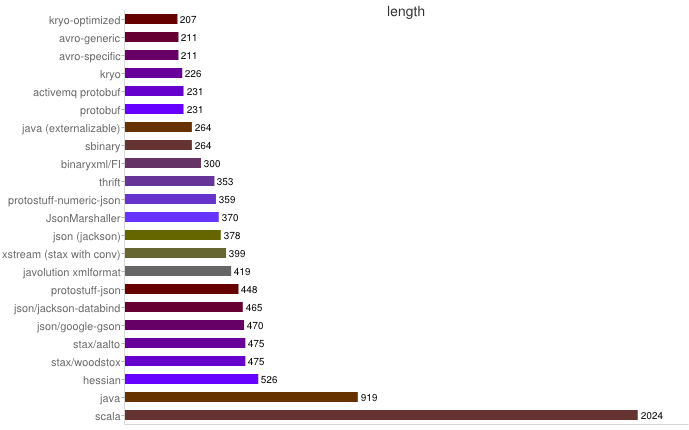
從上圖可得出如下結論:
1、XML序列化(Xstream)無論在性能和簡潔性上比較差。
2、Thrift與Protobuf相比在時空開銷方面都有一定的劣勢。
3、Protobuf和Avro在兩方面表現都非常優越。
選型建議
以上描述的五種序列化和反序列化協議都各自具有相應的特點,適用于不同的場景:
1、對于公司間的系統調用,如果性能要求在100ms以上的服務,基于XML的SOAP協議是一個值得考慮的方案。
2、基于Web browser的Ajax,以及Mobile app與服務端之間的通訊,JSON協議是首選。對于性能要求不太高,或者以動態類型語言為主,或者傳輸數據載荷很小的的運用場景,JSON也是非常不錯的選擇。
3、對于調試環境比較惡劣的場景,采用JSON或XML能夠極大的提高調試效率,降低系統開發成本。
4、當對性能和簡潔性有極高要求的場景,Protobuf,Thrift,Avro之間具有一定的競爭關系。
5、對于T級別的數據的持久化應用場景,Protobuf和Avro是首要選擇。如果持久化后的數據存儲在Hadoop子項目里,Avro會是更好的選擇。
6、由于Avro的設計理念偏向于動態類型語言,對于動態語言為主的應用場景,Avro是更好的選擇。
7、對于持久層非Hadoop項目,以靜態類型語言為主的應用場景,Protobuf會更符合靜態類型語言工程師的開發習慣。
8、如果需要提供一個完整的RPC解決方案,Thrift是一個好的選擇。
9、如果序列化之后需要支持不同的傳輸層協議,或者需要跨防火墻訪問的高性能場景,Protobuf可以優先考慮。
“如何理解網站處理數據交換時的序列化和反序列化”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





