溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
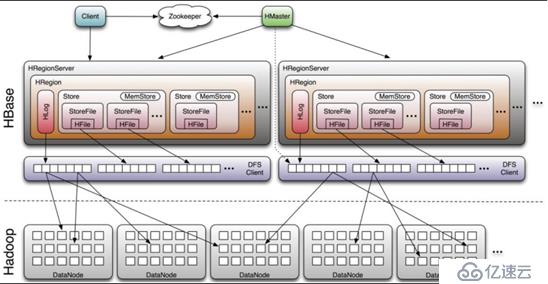
這是舊版本的hbase的架構圖,一個regionserver中只有一個Hlog。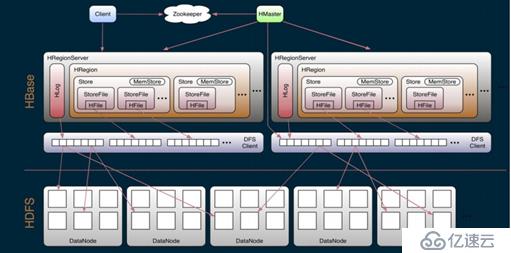
這一張是新版本的圖,每一個regionserver中可以有30個Hlog。
老版本和新版本的變動:
- 0.96版本以前,一個regionserver只有一個HLog,并且管理元數據有.meta. -root-兩個元數據表。
- 0.98版本以后,一個regionserver可以有多個Hlog,并且管理元數據,只有.meta.表。
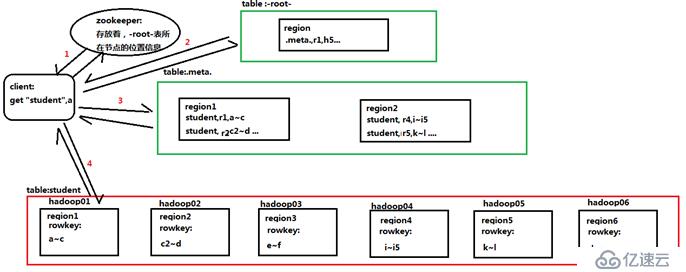
- .MEAT.:記錄了用戶所有表拆分出來的region映射信息(各個region的rowkey范圍,以及存在的節點),.MEAT.可以有多個region。對應的用戶表中切分出來的每一個region就對應.META.表中的一個記錄
- -ROOT-:記錄了.META.表的 Region 信息,-ROOT-只有一個 Region,無論如何不會分裂,同樣的.META.表切分出來的一個region就是- ROO-表中的一個記錄。
- Client訪問用戶表前需要首先訪問zookeeper,找到對應的-ROOT-表的region所在位置,然后訪問-ROOT-表,找到.meta.表的訪問位置,然后找到.meta.表,最后通過.meta.表找到用戶數據的位置去訪問,中間需要多次網絡操作,并且client 端會做 cache 緩存(即如果下一次查找的記錄在上一次已經查詢了,可以不進行以上操作,直接在緩存中得到)
- zookeeper為HBASE提供failover機制,選主master,避免單點故障,其實HBASE中的master,宕機一段時間對集群影響不大,因為master,及時master宕機,HBASE集群仍然可以做:查看,上傳操作,但是不能創建和修改表。但是master宕機很長時間是不行的,因為master需要做負載。
- 存儲所有Region 的尋址入口:-ROOT-表在哪臺服務器上。-ROOT-這張表的位置信息
- 實時監控regionserver的狀態,將regionserver的上線和下線信息實時通知給master
- 存儲HBASE的schema(包括有哪些 Table,每個 Table 有哪些 Column Family);默認情況下: /hbase/table:是zookeeper中存儲HBASE中表名的目錄
- 為regionserver分配region(并且做負載均衡)
- 發現失效的 RegionServer 并重新分配其上的 Region(即,如果有相應的RegionServer宕機的時候,master會將其宕機節點上的region,復制到其他節點上),高容錯。
- HDFS 上的垃圾文件(HBase)回收
- 處理HBASE的schema(表的創建、刪除、修改、列簇的增加…)
- RegionServer 維護 Master 分配給它的 Region,處理對這些 Region 的 IO 請求(即對表中數據的增、刪、改)
- 負責和底層的文件系統hdfs交互,存儲數據到hdfs
- 負責 Store 中的 HFile 的合并工作
- RegionServer 負責 Split 在運行過程中變得過大的 Region,負責 Compact (切分)操作 
切分原則:
第一次:128*(1*1)
第二次:128*(3*3)
第三次:128*(5*5) 直到計算的結果>10G的時候,以后就按照10G切分

上圖是一個regionserver的存儲
- Table中的所有行按照rowkey進行字典排序,然后根據rowkey范圍,切分出不同的region
- Region的默認大小為10G,每個表一開始只有一個 HRegion,隨著數據不斷插入 表,HRegion 不斷增大,當增大到一個閥值的時候,HRegion 就會等分會兩個新的 HRegion。 當表中的行不斷增多,就會有越來越多的 HRegion
- Region是Hbase 中分布式存儲和負載均衡的最小單元。同一個region中的數據一定是存儲在同一個節點上的,但是region切分后,可以存儲的不同的節點
- Region雖然是負載的最小單元,但是不是物理存儲的最小單元。實際上,region由一個或者多個store組成,每一個store,存儲的是region中的一個列簇中的所有數據。每個 Strore 又由一個 MemStore 和 0 至多個 StoreFile 組成

一個region由多個store組成,每一個store包含一個列簇的所有數據,一個region由多個store組成,每一個store包含一個列簇的所有數據。
原理:在寫入數據的時候,現將數據寫入到Memstore,當 Memstore 中的數據量達到某個閾值,regionserver啟動flushcache 進程寫入 Storefile,每次寫入形成單獨一個 HFile。(即,當達到閾值的時候,首先會將存儲在Memstore中的數據寫入磁盤,形式為hfile,當磁盤中有多個Hfile的時候,又會進行合并,合并成一個storefile)。
StoreFile 以 HFile 格式保存在 HDFS 上,請看下圖 HFile 的數據組織格式:
其中:首先 HFile 文件是不定長的,長度固定的只有其中的兩塊:Trailer 和 FileInfo。
- Trailer:有指針,指向其他數據塊的起始點
- FileInfo:記錄本文件的元數據信息
- Data:存儲的是表中的數據
- Meta:保存用戶自定義的 kv 對
- Data Index:data的索引,每條索引的 key 是被索引的 block 的第一條記錄的 key
- Meta Index:Meta的索引,記錄著Meta數據的起始位置
- Data中的magic:用于校驗,判斷是否有數據損壞
其中,除了trailer和fileinfo兩個定長的數據以外,其他的數據都可以進行壓縮。
data中的K-V鍵值的介紹:
兩個固定長度的數值,分別表示key的長度和value的長度。緊接著是key,開始是固定長度的數值,表示rowkey的長度,緊接著是rowkey,然后是固定長度的數值,緊接著是列簇名(最好是16),接著是 Qualifier(列名),然后是兩個固定長度的數值,表示 TimeStamp 和 KeyType(Put/Delete)。Value 部分沒有這么復雜的結構,就是純粹的二進制數據了。
WAL 意為 Write ahead log,用于做災難恢復的,HLog 記錄數據的所有變更,一旦數據修改,就可以從 Log 中 進行恢復。
災難恢復的解釋:開始的時候region的數據時存儲在內存中的metestore,此時還沒有達到閾值,數據仍在內存中,沒有持久化到磁盤,如果此時機器突然宕機,儲存在內存的數據,會丟失,此時需要hlog進行數據的恢復。但是hlog只會保存,在沒有同步到磁盤中的那部分操作的日志,已同步到磁盤的數據,那部分的日志,會被存放到oldWAL目錄下,10分鐘后刪除。
HLog 的文件結構:
- HLog Sequence File 的 Key 是 HLogKey 對象,HLogKey 中記錄了寫入數據的歸屬信息,除 了 table 和 region 名字外,同時還包括 sequence number 和 timestamp,timestamp 是”寫入 時間”,sequence number 的起始值為 0,或者是最近一次存入文件系統中 sequence number。
- HLog Sequece File 的 Value 是 HBase 的 KeyValue 對象,即對應 HFile 中的 KeyValue
介紹 :讀寫是在regionserver上發生,每個 RegionSever 為一定數量的 Region 服務,如果client要對某一行數據做讀寫的時候,我們該訪問哪一個regionserver?,可以使用尋址的方式解決。
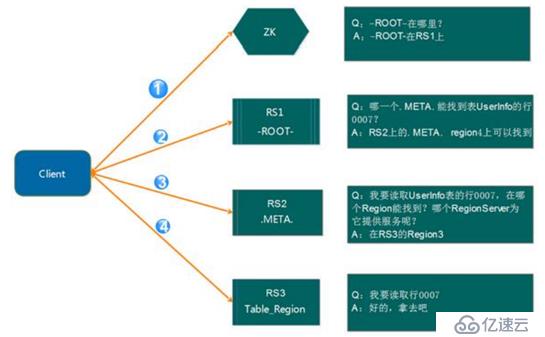
解釋:
- client請求zookeeper獲得-root-所在的regionserver地址
- client請求-root-所在的regionserver,獲取取.META.表的地址。client 會將-ROOT-的相關 信息 cache 下來,以便下一次快速訪問
- client請求.META.表的regionserver,獲取訪問數據所在的regionserver的地址(仍然有緩存)
- client請求訪問數據所在的regionserver,獲取相應的數據
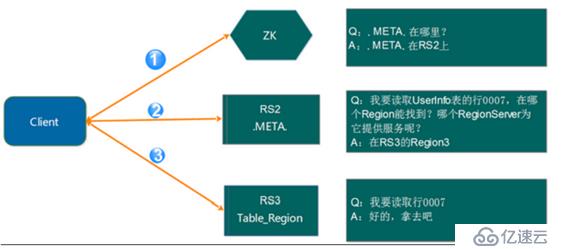
- Client 請求 ZooKeeper 獲取.META.所在的 RegionServer 的地址
- Client 請求.META.所在的 RegionServer 獲取訪問數據所在的 RegionServer 地址,Client 會將.META.的相關信息 cache 下來,以便下一次快速訪問
- Client 請求數據所在的 RegionServer,獲取所需要的數據
- 客戶端通過zookeeper以及-root-表和.mate.表找到目標數據所在的regionserver(尋址)
- 聯系regionserve查詢目標數據
- Region先在memstore中查找,命中則返回
- 如果memstore找不到,則在storefile中掃描 , 為了能快速的判斷要查詢的數據在不在這個 StoreFile 中,應用了 BloomFilter(布隆過濾)
- Client先根據rowkey找到對應的region所在的regionserver(尋址)
- Client向regionserver提交請求
- Regionserver找到目標region
- Regionserver檢查數據是否與 Schema 一致
- 如果客戶端沒有指定版本,則獲取當前系統時間作為數據版本
- 將更新寫入Hlog
- 將數據寫入memstore
- 判斷memstore的是否需要flush為storefile
注意:
- 數據在更新時首先寫入 HLog(WAL Log),再寫入內存(MemStore)中,MemStore 中的數據是排序的
- Storefile是只讀的,一旦創建就不能在修改,因此HBASE的更新/修改其實是不斷追加的操作,根據版本的保留策略,會將舊的數據刪除
任何時刻,一個region只能分配一個regionserver。Master記錄了當前有哪些可用的regionserver。以及當前哪些region分配給了哪些regionserver,哪些region還沒有分配。當需要分配新的region的時候,master就給一個有可用空間的regionserver發送裝載region的請求。把這個region分配個這個regionserver。
Master 使用 zookeeper 來跟蹤 RegionServer 狀態。當某個 RegionServer 啟動時,會首先在 ZooKeeper 上的 server 目錄下建立代表自己的 znode。由于 Master 訂閱了ZooKeeper server 目錄上的變 更消息,當 server 目錄下的文件出現新增或刪除操作時,Master 可以得到來自 ZooKeeper 的實時通知。因此一旦 RegionServer 上線,Master 能馬上得到消息
當 RegionServer 下線時,它和 zookeeper 的會話斷開,ZooKeeper 而自動釋放代表這臺 server 的文件上的獨占鎖。Master 就可以確定,regionserver和zookeeper之間無法通行了,regionserver可能宕機了。
- 從zookeeper上獲取唯一代表Active Master 的鎖,用來阻止其它 Master 成為 Master
- 掃描zookeeper上的server的節點,獲得當前可用的regionserver節點列表。
- 和每一個regionserver通信,獲得當前分配的region和regionserver的對應關系。
- 掃描.META. Region 的集合,計算得到當前還未分配的region,將他們放入待分配region列表。
由于master只維護表和region的元數據,而不參與數據IO的過程,master下線僅導致所有的元數據的修改被凍結(無法創建表,無法修改表的schema,無法進行region的負載均衡),表的數據讀寫還可以正常進行。因此master可以短暫的下線。從上線過程可以看到,Master 保存的信息全是可以冗余信息(都可以從系統其它地方 收集到或者計算出來)
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





