溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Kafka的底層原理,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
Apache Kafka 是一個分布式發布-訂閱消息系統。是大數據領域消息隊列中唯一的王者。最初由 linkedin 公司使用 scala 語言開發,在2010年貢獻給了Apache基金會并成為頂級開源項目。至今已有十余年,仍然是大數據領域不可或缺的并且是越來越重要的一個組件。
Kafka 適合離線和在線消息,消息保留在磁盤上,并在集群內復制以防止數據丟失。kafka構建在zookeeper同步服務之上。它與 Flink 和 Spark 有非常好的集成,應用于實時流式數據分析。
Kafka特點:
可靠性:具有副本及容錯機制。
可擴展性:kafka無需停機即可擴展節點及節點上線。
持久性:數據存儲到磁盤上,持久性保存。
性能:kafka具有高吞吐量。達到TB級的數據,也有非常穩定的性能。
速度快:順序寫入和零拷貝技術使得kafka延遲控制在毫秒級。
先看下 Kafka 系統的架構
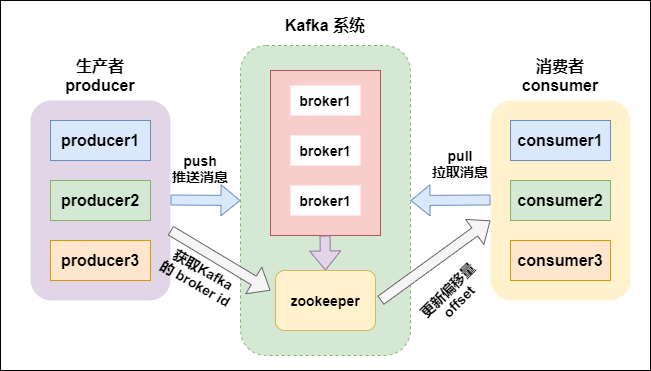
Kafka 架構
kafka支持消息持久化,消費端是主動拉取數據,消費狀態和訂閱關系由客戶端負責維護,消息消費完后,不會立即刪除,會保留歷史消息。因此支持多訂閱時,消息只會存儲一份就可以。
broker:kafka集群中包含一個或者多個服務實例(節點),這種服務實例被稱為broker(一個broker就是一個節點/一個服務器);
topic:每條發布到kafka集群的消息都屬于某個類別,這個類別就叫做topic;
partition:partition是一個物理上的概念,每個topic包含一個或者多個partition;
segment:一個partition當中存在多個segment文件段,每個segment分為兩部分,.log文件和 .index 文件,其中 .index 文件是索引文件,主要用于快速查詢, .log 文件當中數據的偏移量位置;
producer:消息的生產者,負責發布消息到 kafka 的 broker 中;
consumer:消息的消費者,向 kafka 的 broker 中讀取消息的客戶端;
consumer group:消費者組,每一個 consumer 屬于一個特定的 consumer group(可以為每個consumer指定 groupName);
.log:存放數據文件;
.index:存放.log文件的索引數據。
producer主要是用于生產消息,是kafka當中的消息生產者,生產的消息通過topic進行歸類,保存到kafka的broker里面去。
kafka將消息以topic為單位進行歸類;
topic特指kafka處理的消息源(feeds of messages)的不同分類;
topic是一種分類或者發布的一些列記錄的名義上的名字。kafka主題始終是支持多用戶訂閱的;也就是說,一 個主題可以有零個,一個或者多個消費者訂閱寫入的數據;
在kafka集群中,可以有無數的主題;
生產者和消費者消費數據一般以主題為單位。更細粒度可以到分區級別。
kafka當中,topic是消息的歸類,一個topic可以有多個分區(partition),每個分區保存部分topic的數據,所有的partition當中的數據全部合并起來,就是一個topic當中的所有的數據。
一個broker服務下,可以創建多個分區,broker數與分區數沒有關系;
在kafka中,每一個分區會有一個編號:編號從0開始。
每一個分區內的數據是有序的,但全局的數據不能保證是有序的。(有序是指生產什么樣順序,消費時也是什么樣的順序)
consumer是kafka當中的消費者,主要用于消費kafka當中的數據,消費者一定是歸屬于某個消費組中的。
消費者組由一個或者多個消費者組成,同一個組中的消費者對于同一條消息只消費一次。
每個消費者都屬于某個消費者組,如果不指定,那么所有的消費者都屬于默認的組。
每個消費者組都有一個ID,即group ID。組內的所有消費者協調在一起來消費一個訂閱主題( topic)的所有分區(partition)。當然,每個分區只能由同一個消費組內的一個消費者(consumer)來消費,可以由不同的消費組來消費。
partition數量決定了每個consumer group中并發消費者的最大數量。如下圖:
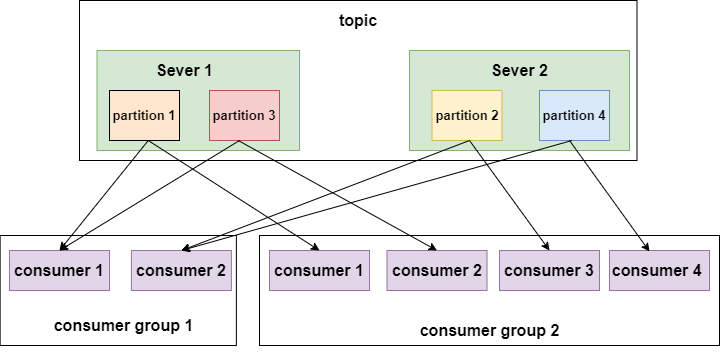
示例 2
如上圖所示,不同的消費者組消費同一個topic,這個topic有4個分區,分布在兩個節點上。左邊的 消費組1有兩個消費者,每個消費者就要消費兩個分區才能把消息完整的消費完,右邊的 消費組2有四個消費者,每個消費者消費一個分區即可。
總結下kafka中分區與消費組的關系:
消費組: 由一個或者多個消費者組成,同一個組中的消費者對于同一條消息只消費一次。
某一個主題下的分區數,對于消費該主題的同一個消費組下的消費者數量,應該小于等于該主題下的分區數。
如:某一個主題有4個分區,那么消費組中的消費者應該小于等于4,而且最好與分區數成整數倍 1 2 4 這樣。同一個分區下的數據,在同一時刻,不能同一個消費組的不同消費者消費。
總結:分區數越多,同一時間可以有越多的消費者來進行消費,消費數據的速度就會越快,提高消費的性能。
kafka 中的分區副本如下圖所示:

.index 與 .log
上圖左半部分是索引文件,里面存儲的是一對一對的key-value,其中key是消息在數據文件(對應的log文件)中的編號,比如“1,3,6,8……”,
分別表示在log文件中的第1條消息、第3條消息、第6條消息、第8條消息……
那么為什么在index文件中這些編號不是連續的呢?
這是因為index文件中并沒有為數據文件中的每條消息都建立索引,而是采用了稀疏存儲的方式,每隔一定字節的數據建立一條索引。
這樣避免了索引文件占用過多的空間,從而可以將索引文件保留在內存中。
但缺點是沒有建立索引的Message也不能一次定位到其在數據文件的位置,從而需要做一次順序掃描,但是這次順序掃描的范圍就很小了。
value 代表的是在全局partiton中的第幾個消息。
以索引文件中元數據 3,497 為例,其中3代表在右邊log數據文件中從上到下第3個消息,
497表示該消息的物理偏移地址(位置)為497(也表示在全局partiton表示第497個消息-順序寫入特性)。
log日志目錄及組成
kafka在我們指定的log.dir目錄下,會創建一些文件夾;名字是 (主題名字-分區名) 所組成的文件夾。 在(主題名字-分區名)的目錄下,會有兩個文件存在,如下所示:
#索引文件00000000000000000000.index#日志內容00000000000000000000.log
在目錄下的文件,會根據log日志的大小進行切分,.log文件的大小為1G的時候,就會進行切分文件;如下:
-rw-r--r--. 1 root root 389k 1月 17 18:03 00000000000000000000.index -rw-r--r--. 1 root root 1.0G 1月 17 18:03 00000000000000000000.log -rw-r--r--. 1 root root 10M 1月 17 18:03 00000000000000077894.index -rw-r--r--. 1 root root 127M 1月 17 18:03 00000000000000077894.log
在kafka的設計中,將offset值作為了文件名的一部分。
segment文件命名規則:partion全局的第一個segment從0開始,后續每個segment文件名為上一個全局 partion的最大offset(偏移message數)。數值最大為64位long大小,20位數字字符長度,沒有數字就用 0 填充。
通過索引信息可以快速定位到message。通過index元數據全部映射到內存,可以避免segment File的IO磁盤操作;
通過索引文件稀疏存儲,可以大幅降低index文件元數據占用空間大小。
稀疏索引:為了數據創建索引,但范圍并不是為每一條創建,而是為某一個區間創建;
好處:就是可以減少索引值的數量。
不好的地方:找到索引區間之后,要得進行第二次處理。
生產者發送到kafka的每條消息,都被kafka包裝成了一個message
生產者發送給kafka數據,可以采用同步方式或異步方式
同步方式:
發送一批數據給kafka后,等待kafka返回結果:
生產者等待10s,如果broker沒有給出ack響應,就認為失敗。
生產者重試3次,如果還沒有響應,就報錯.
異步方式:
發送一批數據給kafka,只是提供一個回調函數:
先將數據保存在生產者端的buffer中。buffer大小是2萬條 。
滿足數據閾值或者數量閾值其中的一個條件就可以發送數據。
發送一批數據的大小是500條。
注:如果broker遲遲不給ack,而buffer又滿了,開發者可以設置是否直接清空buffer中的數據。
生產者數據發送出去,需要服務端返回一個確認碼,即ack響應碼;ack的響應有三個狀態值0,1,-1
0:生產者只負責發送數據,不關心數據是否丟失,丟失的數據,需要再次發送
1:partition的leader收到數據,不管follow是否同步完數據,響應的狀態碼為1
-1:所有的從節點都收到數據,響應的狀態碼為-1
如果broker端一直不返回ack狀態,producer永遠不知道是否成功;producer可以設置一個超時時間10s,超過時間認為失敗。
在broker中,保證數據不丟失主要是通過副本因子(冗余),防止數據丟失。
在消費者消費數據的時候,只要每個消費者記錄好offset值即可,就能保證數據不丟失。也就是需要我們自己維護偏移量(offset),可保存在 Redis 中。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





