溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
大數據領域技術總體介紹(各個組件的作用)
1、大數據技術介紹
大數據技術生態體系:
Hadoop 元老級分布式海量數據存儲、處理技術系統,擅長離線數據分析
Hbase 基于hadoop 的分布式海量數據庫,離線分析和在線業務通吃
Hive sql 基于hadoop 的數據倉庫工具,使用方便,功能豐富,使用方法類似SQL
Zookeeper 集群協調服務
Sqoop 數據導入導出工具
Flume 數據采集框架 //經常會結合kafka+flume數據流 或者用于大量的日志收集到hdfs上 日志收集分析大多數企業用elk
Storm 實時流式計算框架,流式處理領域頭牌框架
Spark 基于內存的分布式運算框架,一站式處理all in one,新秀,發展勢頭迅猛
sparkCore //應用開發
SparkSQL //sql操作 類似hive
SparkStreaming //類似于storm
機器學習:
Mahout 基于mapreduce 的機器學習算法庫
MLLIB 基于spark 機器學習算法庫
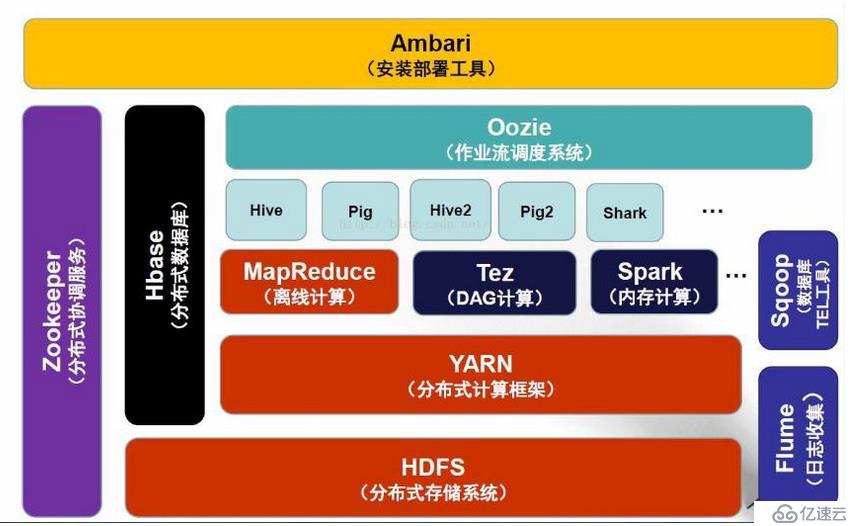

由上圖可以看出,大數據hadoop生態圈中類似于一個動物園,zookeeper組件就類似于一個管理者,管理這些動物。//大數據生態圈的組件很多,不知我們上面提到的組件,圖中展示的為基本組件。
2、需要由潛到深
一、理解該框架的功能和適用場景
二、使用(安裝部署,編程規范,API)
三、運行機制
四、結構原理
五、源碼
3、hadoop基本介紹
(1)hadoop 是用于處理(運算分析)海量數據的技術平臺,且是采用分布式集群的方式;
(2)hadoop 兩個大的功能:
? 提供海量數據的存儲服務;
? 提供分析海量數據的編程框架及運行平臺;
(3)Hadoop 有3大核心組件:
? HDFS---- hadoop 分布式文件系統海量數據的存儲(集群服務),
? MapReduce----分布式運算框架(編程框架)(導jar 包寫程序),海量數據運算分析(替代品:storm /spark 等)
? Yarn ----資源調度管理集群(可以理解為一個分布式的操作系統,管理和分配集群硬件資源)
(4)使用Hadoop:
? 可以把hadoop 理解為一個編程框架(類比:structs、spring、hibernate/mybatis),有著自己特定的API 封裝和用戶編程規范,用戶可借助這些API 來實現數據處理邏輯;從另一個角度,hadoop 又可以理解為一個提供服務的軟件(類比:數據庫服務
oracle/mysql、索引服務solr,緩存服務redis 等),用戶程序通過客戶端向hadoop集群請求服務來實現特定的功能;
(5)Hadoop 產生的歷史
最早來自于google 的三大技術論文:GFS/MAPREDUCE/BIG TABLE
(為什么google 會需要這么一種技術?)
后來經過doug cutting 的“山寨”,出現了java 版本的hdfs mapreduce 和hbase
并成為apache 的頂級項目hadoop ,hbase
經過演化,hadoop 的組件又多出一個yarn(mapreduce+ yarn + hdfs)
而且,hadoop 外圍產生了越來越多的工具組件,形成一個龐大的hadoop 生態體系
為什么需要hadoop
在數據量很大的情況下,單機的處理能力無法勝任,必須采用分布式集群的方式進行處理,而用分布式集群的方式處理數據,實現的復雜度呈級數增加,所以,在海量數據處理的需求下,一個通用的分布式數據處理技術框架能大大降低應用開發難度和減少工作量。
hadoop業務的整體開發流程:見圖
flume數據采集--->MapReduce清洗---->存入hbase或者hdfs---->hive統計分析---->存入hive表中--->sqoop導入導出--->mysql數據庫--->web展示
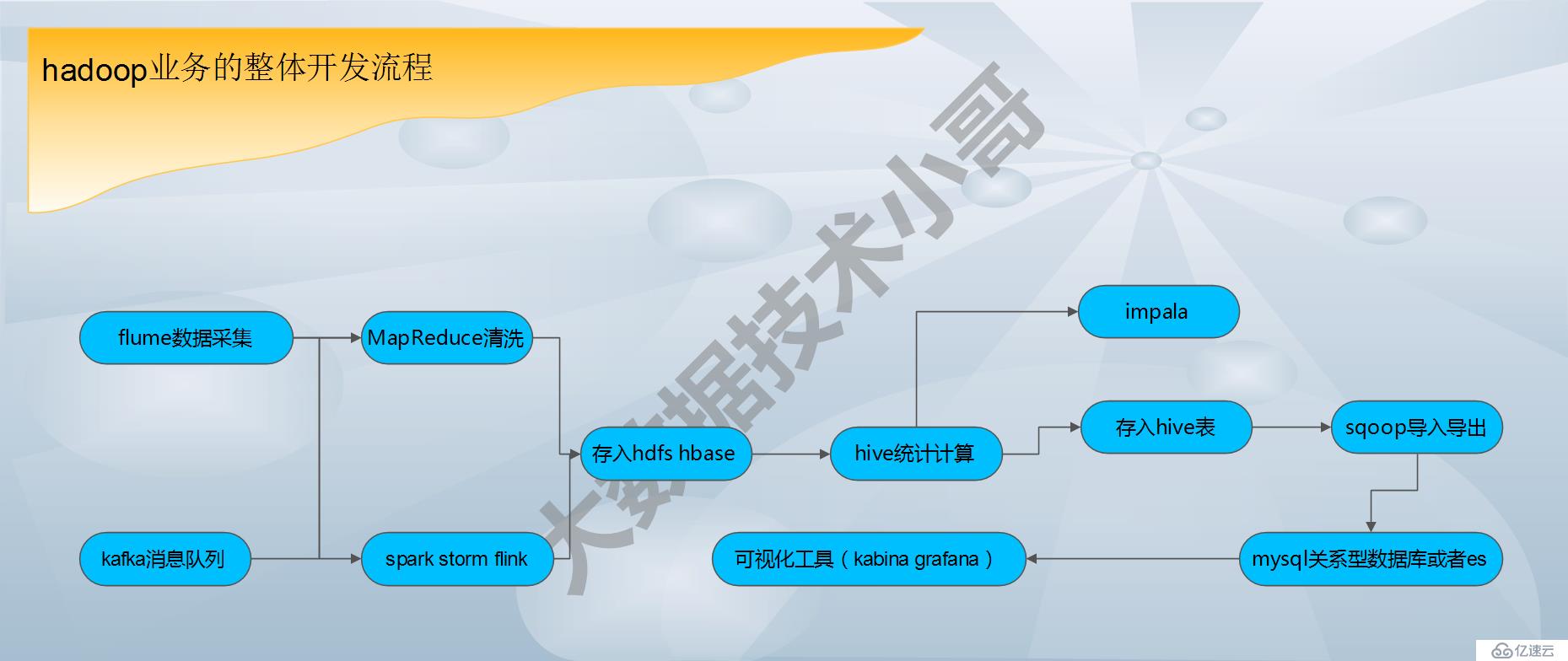
提示:其中我們當數據量非常大的時候,我們可以在flume數據采集節點加入kafka消息隊列形成緩存區;在數據清洗階段我們可以用spark 或者storm flink等內存和實時流算法框架(針對不同的業務場景);存入hadoop中的HBASE或者hdfs中;在數據分析階段,我們可以用hive或者impala等計算工具;web展示的時候,可以把數據用elk中kabina//數據可視化工具kabina或者Grafana
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





