溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹如何進行關于HFile的存儲結構梳理以及快速定位rowkey,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
一、HFile結構介紹
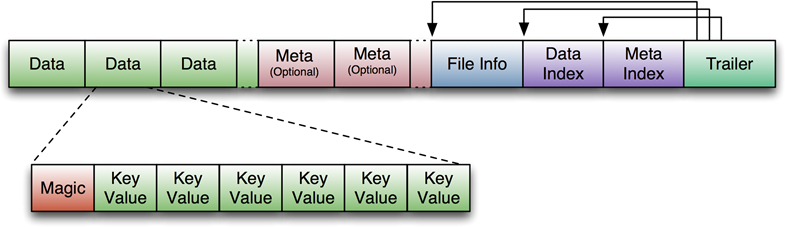
為了支持數據的隨機查詢,HFile結構分為六個部分:
1、數據塊–保存表中的數據,每一個數據塊由塊頭和一些keyValue(record)組成,key的值是嚴格按照順序存儲的。塊大小默認為64K(由建表時創建cf時指定或者HColumnDescriptor.setBlockSize(size)),這一部分可以壓縮存儲。在查詢數據時,是以數據塊為單位從硬盤load到內存。查找數據時,是順序的遍歷該塊中的keyValue對。
2、元數據塊 (可選的)–保存用戶自定義的kv對,可以被壓縮。比如booleam filter就是存在元數據塊中的,該塊只保留value值,key值保存在元數據索引塊中。每一個元數據塊由塊頭和value值組成。可以快速判斷key是都在這個HFile中。
3、File Info–Hfile的元信息,不被壓縮,用戶也可以在這一部分添加自己的元信息。
4、數據索引塊 –Data Block的索引,每條索引的key是被索引的block的第一條記錄的key(格式為:頭信息,數據塊offset數據塊大小塊第一個記錄的key,........)。
這個參數控制hfile中索引塊的大小,默認值是128K,也就是說當索引的信息超過128K后,就會新分配一個索引塊。hbase對于hfile的訪問都是通過索引塊來實現的,通過索引來定位所要查的數據到底在哪個數據塊里面。hfile中的索引塊可以分成三中,根索引塊,枝索引塊,葉索引塊。根索引塊是一定會有的,但是如果hfile中的數據塊比較少的話,枝索引塊和葉索引塊就可能不存在。當單個的索引塊中沒有辦法存儲全部的數據塊的信息時,索引塊就會分裂,會產生葉索引塊和根索引塊,根索引塊是對葉索引塊的索引,如果數據塊繼續增加就會產生枝索引塊,整個索引結果的層次也會加深。
想象一下,如果整個hfile中只有根索引塊,那么訪問真正的數據的路徑是,首先查根索引塊定位數據塊的位置,然后去查詢數據塊找到需要的數據。整個過程涉及到一次對索引塊的掃描和一次對數據塊的掃描。
如果hfile總塊比較多,整個索引結構有2次的話,訪問的路徑是,首先訪問根索引塊定位葉索引塊,訪問葉索引塊定位數據塊,整個過程涉及到兩次對索引塊的掃描和一次對數據塊的掃描。
整個索引樹的深度越深,那么訪問過程就越長,相應的掃描的時間也會越長。
那是不是把hfile.index.block.max.size設置得越大越好呢?也不是的,如果索引塊太大了,對索引塊本身的掃描時間就會顯著的增加的。
根索引塊一定是被緩存到內存中的,這個是在hfile打開的時候就緩存的.
想象一下,如果整個hfile中只有根索引塊,那么訪問真正的數據的路徑是,首先查根索引塊定位數據塊的位置,然后去查詢數
據塊找到需要的數據。整個過程涉及到一次對索引塊的掃描和一次對數據塊的掃描。
HFile的數據塊,元數據塊通常采用壓縮方式存儲,壓縮之后可以大大減少網絡IO和磁盤IO,隨之而來的開銷當然是需要花費cpu進行壓縮和解壓縮
HFile Data Block Index索引層級的問題,
hfile.data.block.size(默認64K):同樣的數據量,數據塊越小,數據塊越多,索引塊相應的也就越多,索引層級就越深
hfile.index.block.max.size(默認128K):控制索引塊的大小,索引塊越小,需要的索引塊越多,索引的層級越深
table key length:越大,索引層級越深
hfile中存儲的數據量:越大,索引層級越深
5、元數據索引塊 (可選的)–Meta Block的索引。
6、Trailer–這一段是定長的。保存了每一段(由一種類型的塊組成)的偏移量,讀取一個HFile時,會首先 讀取Trailer,Trailer保存了每個段的起始位置(段的Magic Number用來做安全check),然后,數據索引會被讀取到內存中,這樣,當檢索某個key時,不需要掃描整個HFile,而只需從內存中找到key所在的block,通過一次磁盤io將整個block讀取到內存中,再找到需要的key。數據索引塊采用LRU機制淘汰。
二、怎樣從一系列的HFile中找到某個rowkey?
如果創建表時,指定了booleamFilter,那么就根據booleamFilter快速的判斷該rowkey是否在這個HFile中。
如果沒有定義booleamFilter,hbase在查找先會根據時間戳或者查詢列的信息來進行過濾,過濾掉那些肯定不含有所需數據的storefile或者memstore,盡量把我們的查詢目標范圍縮小。
盡管縮小了,但仍可能會有多個文件需要掃描的。storefile的內部有序的,但是各個storefile之間并不是有序的。storefile的rowkey的范圍很有可能有交叉。所以查詢數據的過程也不可能是對storefile的順序查找。
hbase會首先查看每個storefile的最小的rowkey,然后按照從小到大的順序進行排序,結果放到一個隊列中,排序的算法就是按照hbase的三維順序,按照rowkey,column,ts進行排序,rowkey和column是升序,而ts是降序。
實際上并不是所有滿足時間戳和列過濾的文件都會加到這個隊列中,hbase會首先對各個storefile中的數據進行探測,只會掃描掃描那些存在比當前查詢的rowkey大的記錄的storefile。
下面開始查詢數據,整個過程用到了類似歸并排序的算法,首先通過poll取出隊列的頭storefile,會從storefile讀取一條記錄返回;接下來呢,該storefile的下條記錄并不一定是查詢結果的下一條記錄,因為隊列的比較順序是比較的每個storefile的第一條符合要求的rowkey。所以,hbase會繼續從隊列中剩下的storefile取第一條記錄,把該記錄與頭storefile的第二條記錄做比較,如果前者大,那么返回頭storefile的第二條記錄;如果后者大,則會把頭storefile放回隊列重新排序,在重新取隊列的頭storefile。然后重復上面的整個過程,直到找到key所在的HFile。范圍縮小到該HFile后,就根據上面介紹的索引查找定位到塊,快速的找到對應的記錄。
關于如何進行關于HFile的存儲結構梳理以及快速定位rowkey就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





