溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“flume的功能是什么”,在日常操作中,相信很多人在flume的功能是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”flume的功能是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
flume自帶寫hdfs的組建 hdfs sink,功能和性能都不錯,就是有些缺點不好克服。
1,收集的日志一直在寫hadoop,雖然可以訂一個規則間斷寫hadoop,例如設置batchSize等,但在大壓力下,幾乎可以認為是每時每刻都在寫hafs.
2,容錯性差,日志收集的過程中,hadoop出現錯誤(例如,hdfs丟塊)等問題,就會崩潰。
3,還有4,5等等,就是hdfs sink 有些問題了,不寫了。
這里寫一個先收集日志到本地,形成文件,然后把這個文件上載到遠程的hadoop上。
這樣做有好處,
1,日志收聚到本地文件。在收集日志過程中出現的hadoop錯誤、異常等等文件,在收集日志成文件的工程中不存在。
2,上傳到hadoop采用文件的方式,使用hadoop自己的fs API,可以有很好的效率。
3,很好的容錯機制,上傳文件的工程中出現hadoop問題,導致文件上傳失敗,沒關系,下一個工作任務再上傳就好了,只有上傳成功才刪除本地文件。
4,還有好多了,這里不寫了。
大致的架構
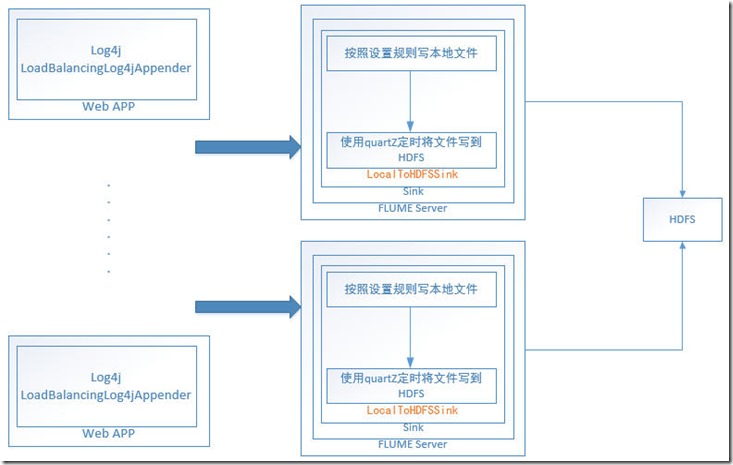
這里做假單的解釋:
LocalToHDFSSink.java 就是flume sink的啟動類,在配置文件中要做配置的,a1.sinks.k1.type = com.fone.flume.sink.localFile.LocalToHDFSSink
其中如下代碼:
@Overridepublic void start() {
......
CronTriggerFileHDFS cronTriggerFileHDFS = new CronTriggerFileHDFS();
LOG.info("定時器設置,cron expression :{} .", cronExpression);try {
cronTriggerFileHDFS.run(filePath, hdfsPath, cronExpression, isKeep);
} catch (Exception e) {
LOG.warn("向hdfs寫文件的定時器錯誤,錯誤:{}.", e);
}
sinkCounter.start();
......
}@Overridepublic void stop() {
......if (cronTriggerFileHDFS != null) {try {
cronTriggerFileHDFS.shutdown();
} catch (Exception e) {// TODO Auto-generated catch block e.printStackTrace();
}
}
......
}開關定時器。
定時器設定:a1.sinks.k1.local.cronExpression = 0 */15  * * * ? 按照quartZ的設置要求進行設置,不了解者去看quartZ cronTigger設置。
LocalToHDFSSink的文件存儲是這樣的,本地文件給定一個初始的目錄a1.sinks.k1.local.directory,日志在這個初始的目錄存儲,動態的目錄結構通過a1.sinks.k1.local.middleDir 設置。
遠程的hadoop給定一個初始的目錄a1.sinks.k1.hdfs.directory ,其它的目錄結構和文件與本地的設置完全相同,也就是把a1.sinks.k1.local.directory目錄下的所有內容,復制到a1.sinks.k1.hdfs.directory 完成工作。
日志收集文件在本地產生,沒有完成的時候,帶文件名后綴.tmp,完成后去掉.tmp,以此作為是否現在執行復制到hadoop的標志。
其余的看代碼吧。
到此,關于“flume的功能是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





