溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行kafka各原理的剖析,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
topic如何創建于刪除的
topic的創建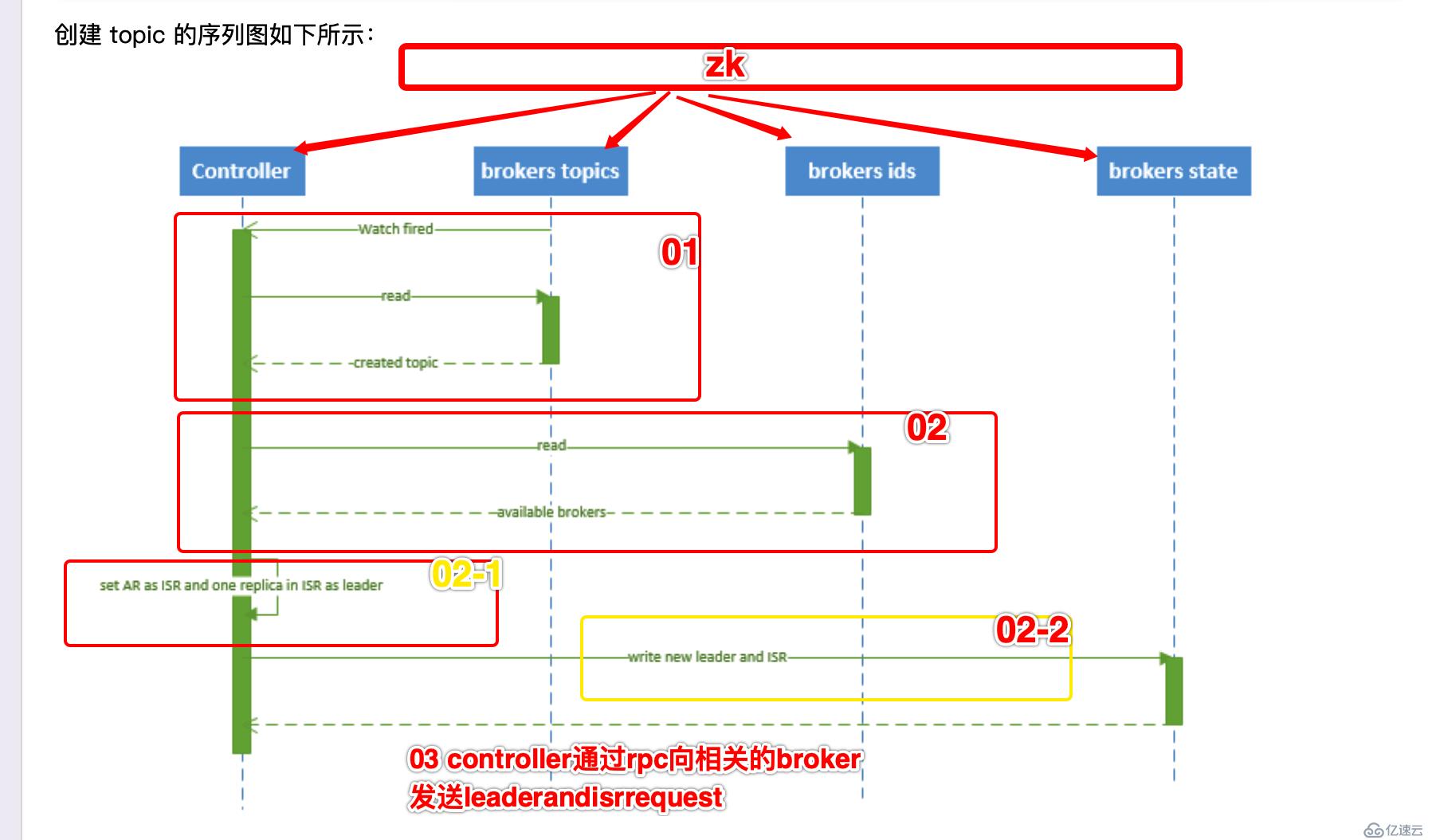
具體流程文字為:
1、 controller 在 ZooKeeper 的 /brokers/topics 節點上注冊 watcher,當 topic 被創建,則 controller 會通過 watch 得到該 topic 的 partition/replica 分配。 2、 controller從 /brokers/ids 讀取當前所有可用的 broker 列表,對于 set_p 中的每一個 partition: 2.1、 從分配給該 partition 的所有 replica(稱為AR)中任選一個可用的 broker 作為新的 leader,并將AR設置為新的 ISR 2.2、 將新的 leader 和 ISR 寫入 /brokers/topics/[topic]/partitions/[partition]/state 3、 controller 通過 RPC 向相關的 broker 發送 LeaderAndISRRequest。
注意:此部分 和 partition 的leader選舉過程很類似 都是需要 zk參與 相關信息都是記錄到zk中
controller在這些過程中啟到非常重要的作用。
topic的刪除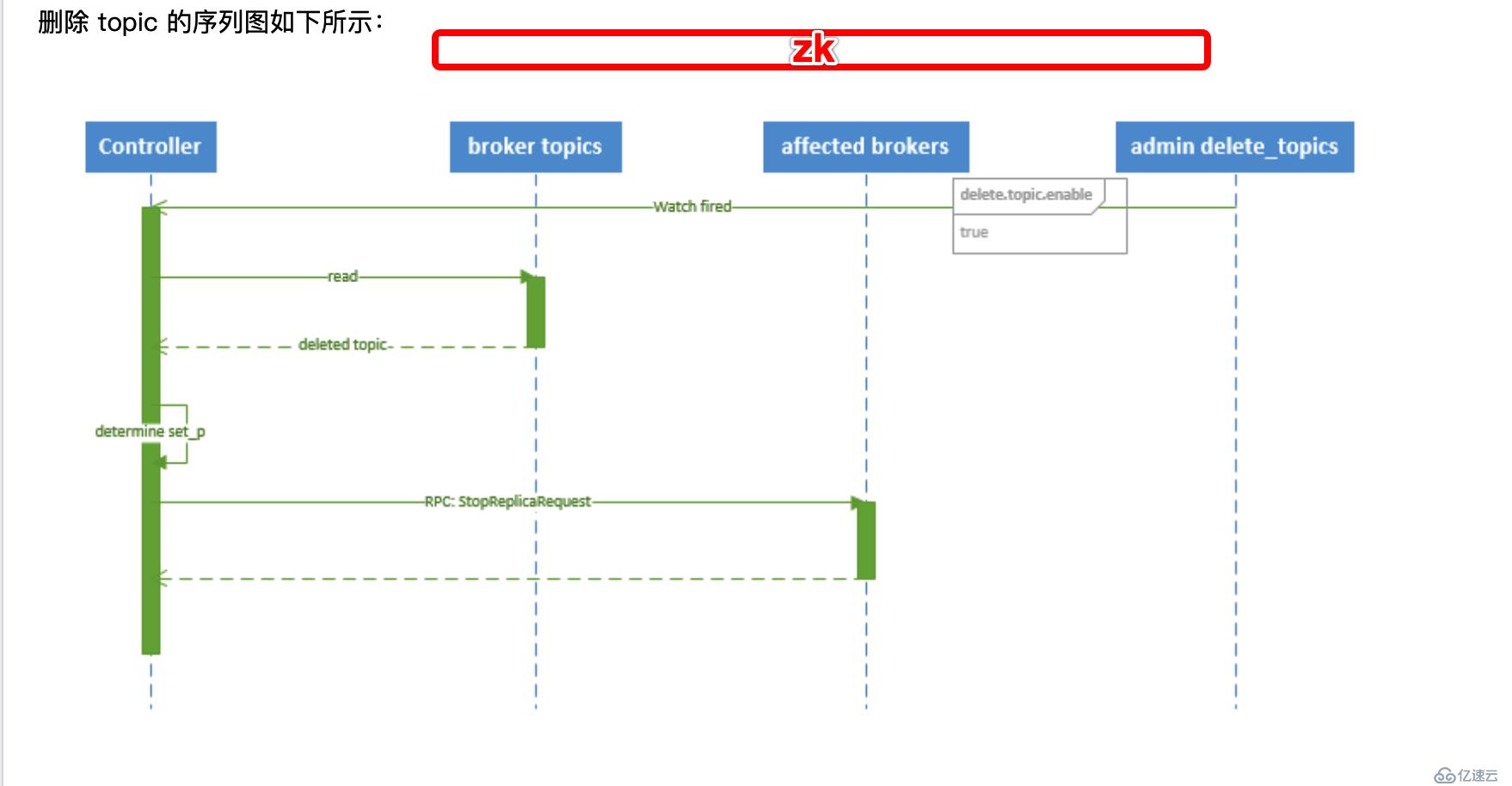
文字過程:
1、 controller 在 zooKeeper 的 /brokers/topics 節點上注冊 watcher,當 topic 被刪除,則 controller 會通過 watch 得到該 topic 的 partition/replica 分配。 2、 若 delete.topic.enable=false,結束;否則 controller 注冊在 /admin/delete_topics 上的 watch 被 fire,controller 通過回調向對應的 broker 發送 StopReplicaRequest。
前面我們講到的很多的處理故障過程 包括 topic創建刪除 partition leader的轉換 broker發生故障的過程中如何保證高可用 都涉及到了一個組件 controller,關于kafka中出現的相關概念名詞,我會專門的寫一個博客,這里先簡單的提一下。
Controller:Kafka 集群中的其中一個服務器,用來進行 Leader Election 以及各種 Failover。
大家有沒有想過一個問題,就是如果controller出現了故障,怎么辦,如何failover的呢?我們往下看。
首先我們最一個實驗,我們在zk中找到controller在哪個broker上,并查看controller_epoch的次數
[zk: localhost:2181(CONNECTED) 14] ls /kafkagroup/controller
controller_epoch controller
[zk: localhost:2181(CONNECTED) 14] ls /kafkagroup/controller
[]
[zk: localhost:2181(CONNECTED) 15] get /kafkagroup/controller
{"version":1,"brokerid":1002,"timestamp":"1566648802297"}
[zk: localhost:2181(CONNECTED) 22] get /kafkagroup/controller_epoch
23我們可以看到當前的controller在1002上 在此之前發了23次controller的切換
我們手動到 1002節點上殺死kafka進程 [hadoop@kafka02-55-12$ jps 11665 Jps 10952 Kafka 11068 ZooKeeperMain 10495 QuorumPeerMain [hadoop@kafka02-55-12$ kill -9 10952 [hadoop@kafka02-55-12$ jps 11068 ZooKeeperMain 11678 Jps 10495 QuorumPeerMain
再看zk上的信息,相關信息已經同步到zk中了
[zk: localhost:2181(CONNECTED) 16] get /kafkagroup/controller
{"version":1,"brokerid":1003,"timestamp":"1566665835022"}
[zk: localhost:2181(CONNECTED) 22] get /kafkagroup/controller_epoch
24
[zk: localhost:2181(CONNECTED) 25] ls /kafkagroup/brokers
[ids, topics, seqid]
[zk: localhost:2181(CONNECTED) 26] ls /kafkagroup/brokers/ids
[1003, 1001]在后臺日志中就會看到很多
[hadoop@kafka03-55-13 logs]$ vim state-change.log
[2019-08-25 01:01:07,886] TRACE [Controller id=1003 epoch=24] Received response {error_code=0} for request UPDATE_METADATA wit
h correlation id 7 sent to broker 10.211.55.13:9092 (id: 1003 rack: null) (state.change.logger)
[hadoop@kafka03-55-13 logs]$ pwd
/data/kafka/kafka-server-logs/logs
state改變的信息
[hadoop@kafka03-55-13 logs]$ tailf controller.log
[2019-08-25 01:05:42,295] TRACE [Controller id=1003] Leader imbalance ratio for broker 1002 is 1.0 (kafka.controller.KafkaCont
roller)
[2019-08-25 01:05:42,295] INFO [Controller id=1003] Starting preferred replica leader election for partitions (kafka.controll
er.KafkaController)
接下來,我們具體的分析一下,他到底內部發生了什么,如何切換的
當 controller 宕機時會觸發 controller failover。每個 broker 都會在 zookeeper 的 "/controller" 節點注冊 watcher,當 controller 宕機時 zookeeper 中的臨時節點消失,所有存活的 broker 收到 fire 的通知,每個 broker 都嘗試創建新的 controller path,只有一個競選成功并當選為 controller。
當新的 controller 當選時,會觸發 KafkaController.onControllerFailover 方法,在該方法中完成如下操作:
1、 讀取并增加 Controller Epoch。
2、 在 reassignedPartitions Patch(/admin/reassign_partitions) 上注冊 watcher。
3、 在 preferredReplicaElection Path(/admin/preferred_replica_election) 上注冊 watcher。
4、 通過 partitionStateMachine 在 broker Topics Patch(/brokers/topics) 上注冊 watcher。
5、 若 delete.topic.enable=true(默認值是 false),則 partitionStateMachine 在 Delete Topic Patch(/admin/delete_topics) 上注冊 watcher。
6、 通過 replicaStateMachine在 Broker Ids Patch(/brokers/ids)上注冊Watch。
7、 初始化 ControllerContext 對象,設置當前所有 topic,“活”著的 broker 列表,所有 partition 的 leader 及 ISR等。
8、 啟動 replicaStateMachine 和 partitionStateMachine。
9、 將 brokerState 狀態設置為 RunningAsController。
10、 將每個 partition 的 Leadership 信息發送給所有“活”著的 broker。
11、 若 auto.leader.rebalance.enable=true(默認值是true),則啟動 partition-rebalance 線程。
12、 若 delete.topic.enable=true 且Delete Topic Patch(/admin/delete_topics)中有值,則刪除相應的Topic。
可以看到,都是在zk上進行交互,controller的從新選舉會依次通知 zk中相關的位置 并注冊watcher ,在此過程中 就會發送 partition的leader的選舉,還會發生partition-rebalanced 刪除無用的topic等一系列操作(因為我們這里是直接考慮的最糟糕的情況就是broker宕機了一個,然而宕機的這臺上就是controller)
consumer是如何消費消息的
重要概念:每個 Consumer 都劃歸到一個邏輯 Consumer Group 中,一個 Partition 只能被同一個 Consumer Group 中的一個 Consumer 消費,但可以被不同的 Consumer Group 消費。
若 Topic 的 Partition 數量為 p,Consumer Group 中訂閱此 Topic 的 Consumer 數量為 c, 則:
p < c: 會有 c - p 個 consumer閑置,造成浪費
p > c: 一個 consumer 對應多個 partition
p = c: 一個 consumer 對應一個 partition
應該合理分配 Consumer 和 Partition 的數量,避免造成資源傾斜,
本人建議最好 Partiton 數目是 Consumer 數目的整數倍。
在consumer消費的過程中如何把partition分配給consumer?
也可以理解為consumer發生rebalance的過程是如何的?
生產過程中 Broker 要分配 Partition,消費過程這里,也要分配 Partition 給消費者。
類似 Broker 中選了一個 Controller 出來,消費也要從 Broker 中選一個 Coordinator,用于分配 Partition。// Coordinator 和 Controller 都是一個概念,協調者 組織者
當 Partition 或 Consumer 數量發生變化時,比如增加 Consumer,減少 Consumer(主動或被動),增加 Partition,都會進行 consumer的Rebalance。//發生rebalance發生在consumer端
見圖: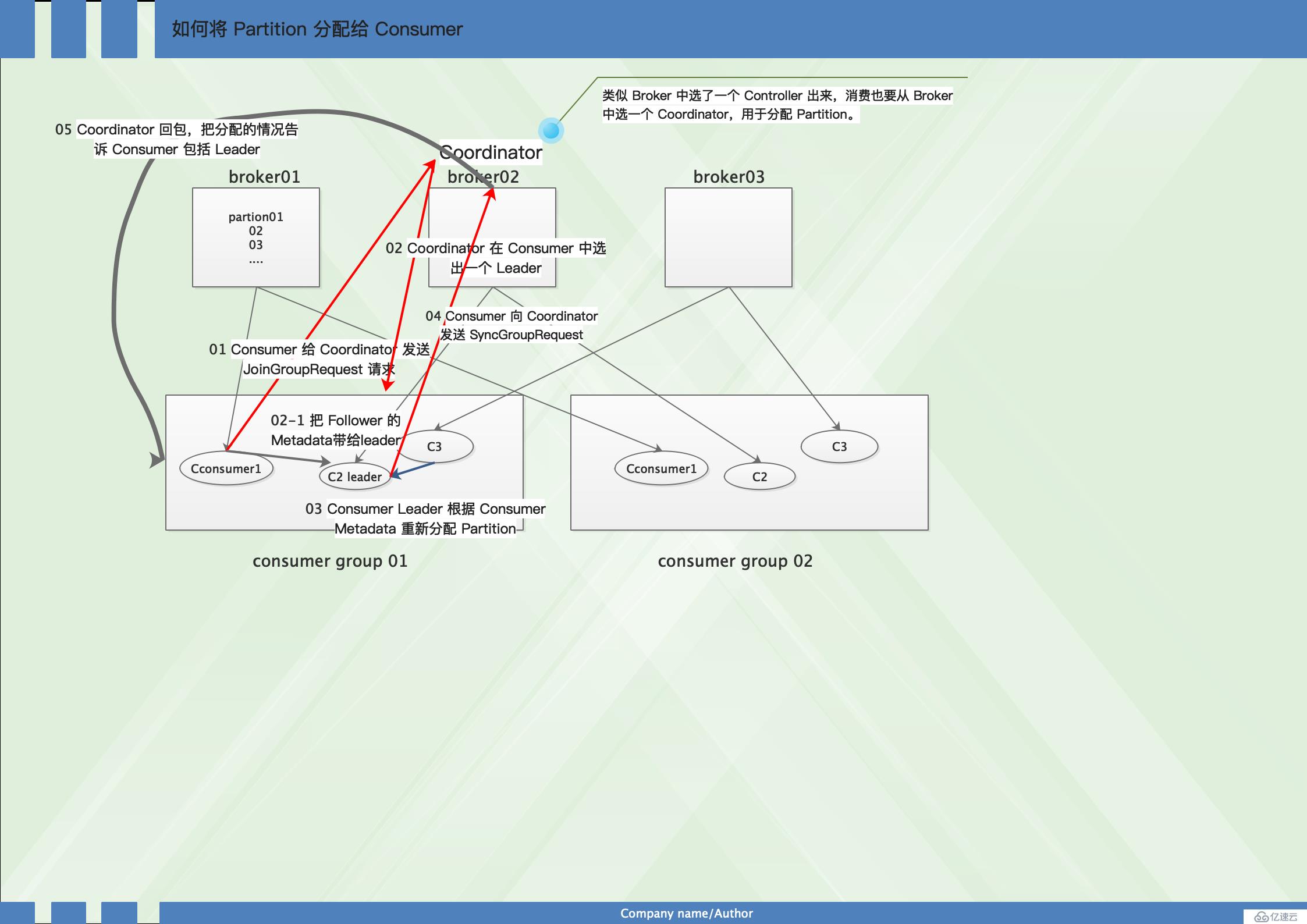
文字信息為:
1、Consumer 給 Coordinator 發送 JoinGroupRequest 請求。這時其他 Consumer 發 Heartbeat 請求過來時,Coordinator 會告訴他們,要 Rebalance了。其他 Consumer 也發送 JoinGroupRequest 請求。
2、Coordinator 在 Consumer 中選出一個 Leader,其他作為 Follower,通知給各個 Consumer,對于 Leader,還會把 Follower 的 Metadata 帶給它。
3、Consumer Leader 根據 Consumer Metadata 重新分配 Partition。
4、Consumer 向 Coordinator 發送 SyncGroupRequest,其中 Leader 的 SyncGroupRequest 會包含分配的情況。
5、Coordinator 回包,把分配的情況告訴 Consumer,包括 Leader。
小結:
消費組與分區重平衡
可以看到,當新的消費者加入消費組,它會消費一個或多個分區,而這些分區之前是由其他消費者負責的;另外,當消費者離開消費組(比如重啟、宕機等)時,它所消費的分區會分配給其他分區。這種現象稱為重平衡(rebalance)。
重平衡是 Kafka 一個很重要的性質,這個性質保證了高可用和水平擴展。
不過也需要注意到,在重平衡期間,所有消費者都不能消費消息,因此會造成整個消費組短暫的不可用。而且,將分區進行重平衡也會導致原來的消費者狀態過期,從而導致消費者需要重新更新狀態,這段期間也會降低消費性能。
文字過程實例:
消費者通過定期發送心跳(hearbeat)到一個作為組協調者(group coordinator)的 broker 來保持在消費組內存活。這個 broker 不是固定的,每個消費組都可能不同。當消費者拉取消息或者提交時,便會發送心跳。
如果消費者超過一定時間沒有發送心跳,那么它的會話(session)就會過期,組協調者會認為該消費者已經宕機,然后觸發重平衡。可以看到,從消費者宕機到會話過期是有一定時間的,這段時間內該消費者的分區都不能進行消息消費;通常情況下,我們可以進行優雅關閉,這樣消費者會發送離開的消息到組協調者,這樣組協調者可以立即進行重平衡而不需要等待會話過期。
在 0.10.1 版本,Kafka 對心跳機制進行了修改,將發送心跳與拉取消息進行分離,這樣使得發送心跳的頻率不受拉取的頻率影響。另外更高版本的 Kafka 支持配置一個消費者多長時間不拉取消息但仍然保持存活,這個配置可以避免活鎖(livelock)。活鎖,是指應用沒有故障但是由于某些原因不能進一步消費。
接下來思考一個問題,consumer是如何取消息的 Consumer Fetch Message
Consumer 采用"拉模式"消費消息,這樣 Consumer 可以自行決定消費的行為。
Consumer 調用 Poll(duration)從服務器拉取消息。拉取消息的具體行為由下面的配置項決定:
#consumer.properties #消費者最多 poll 多少個 record max.poll.records=500 #消費者 poll 時 partition 返回的最大數據量 max.partition.fetch.bytes=1048576 #Consumer 最大 poll 間隔 #超過此值服務器會認為此 consumer failed #并將此 consumer 踢出對應的 consumer group max.poll.interval.ms=300000
小結:
1、在 Partition 中,每個消息都有一個 Offset。新消息會被寫到 Partition 末尾(最新的一個 Segment 文件末尾), 每個 Partition 上的消息是順序消費的,不同的 Partition 之間消息的消費順序是不確定的。
2、若一個 Consumer 消費多個 Partition, 則各個 Partition 之前消費順序是不確定的,但在每個 Partition 上是順序消費。
3、若來自不同 Consumer Group 的多個 Consumer 消費同一個 Partition,則各個 Consumer 之間的消費互不影響,每個 Consumer 都會有自己的 Offset。
舉個官方小栗子: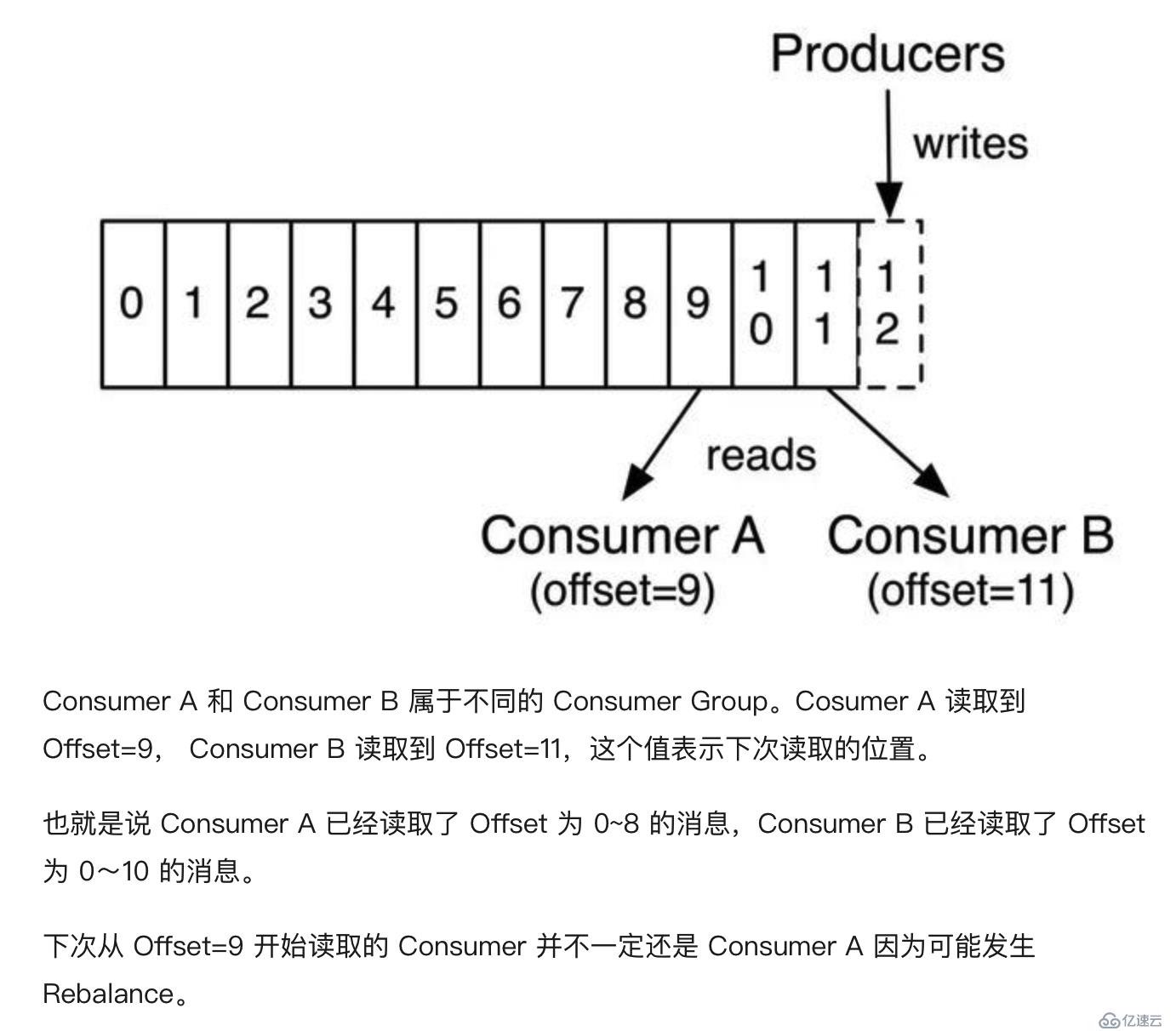
Offset 如何保存?
Consumer 消費 Partition 時,需要保存 Offset 記錄當前消費位置。
Offset 可以選擇自動提交或調用 Consumer 的 commitSync() 或 commitAsync() 手動提交,相關配置為:
#是否自動提交 offset enable.auto.commit=true #自動提交間隔。enable.auto.commit=true 時有效 auto.commit.interval.ms=5000 //enable.auto.commit 的默認值是 true;就是默認采用自動提交的機制。 auto.commit.interval.ms 的默認值是 5000,單位是毫秒。5 秒
Offset 保存在名叫 __consumeroffsets 的 Topic 中。寫消息的 Key 由 GroupId、Topic、Partition 組成,Value 是 Offset。
一般情況下,每個 Key 的 Offset 都是緩存在內存中,查詢的時候不用遍歷 Partition,如果沒有緩存,第一次就會遍歷 Partition 建立緩存,然后查詢返回
__consumeroffsets 的 Partition 數量由下面的 Server 配置決定:
offsets.topic.num.partitions=50
默然的consumeroffsets是沒有repale副本的 需要我們通過在一開始的參數指定,或者通過后期的增加 consumeroffsets 的副本json的方式動態添加
auto.create.topics.enable=true default.replication.factor=2 num.partitions=3
經過測試上面的3個參數雖然在搭建好kafak的時候第一次指定了,但是 consumeroffsets副本數還是1個,這個的關鍵在于,配置文件中需要指定
kafka配置文件關于此參數解釋如下:
############################# Internal Topic Settings ############################# 內部主題設置
#組元數據內部主題“consumer_offsets”和“transaction_state”的復制因子
#對于除開發測試之外的任何其他內容,建議使用大于1的值以確保可用性,例如設置成3。
The replication factor for the group metadata internal topics "__consumer_offsets" and "transaction_state"
For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=2
transaction.state.log.min.isr=2
//關于這3個參數,可以在修改kafka程序中指定的 consumer_offsets 的副本數
然后@上海-馬吉輝 說只要num.partitions=3,__consumer_offsets副本數就是3,我測試不是 還是1
所以還是以offsets.topic.replication.factor參數控制為準
如果不是第一次啟動kafka 那幾個配置只有在初次啟動生效的。 apache kafka 下載下來應該都默認是 1 吧,2.* 也是 1 啊。
可以這樣修改
先停止kafka集群,刪除每個broker data目錄下所有consumeroffsets*
然后刪除zookeeper下rmr /kafkatest/brokers/topics/consumer_offsets 然后重啟kafka
消費一下,這個__consumer_offsets就會創建了
注意:是在第一次消費時,才創建這個topic的,不是broker集群啟動就創建,還有那個trancation_state topic也是第一次使用事務的時候才會創建
小結:在生產上,沒人去刪zk里的內容,危險系數大,還是推薦動態擴副本,只要把json寫對就好
控制 __consumer_offsets 的副本數 的關鍵參數為這3個。
Offset 保存在哪個分區上,即 __consumeroffsets 的分區機制,可以表示為
groupId.hashCode() mode groupMetadataTopicPartitionCount
groupMetadataTopicPartitionCount 是上面配置的分區數。因為一個 Partition 只能被同一個 Consumer Group 的一個 Consumer 消費,因此可以用 GroupId 表示此 Consumer 消費 Offeset 所在分區。
Kafka 中的可靠性保證有如下四點:
1、對于一個分區來說,它的消息是有序的。如果一個生產者向一個分區先寫入消息A,然后寫入消息B,那么消費者會先讀取消息A再讀取消息B。
2、當消息寫入所有in-sync狀態的副本后,消息才會認為已提交(committed)。這里的寫入有可能只是寫入到文件系統的緩存,不一定刷新到磁盤。生產者可以等待不同時機的確認,比如等待分區主副本寫入即返回,后者等待所有in-sync狀態副本寫入才返回。
3、一旦消息已提交,那么只要有一個副本存活,數據不會丟失。
4、消費者只能讀取到已提交的消息。
看到這里,我們對kafka有了全新的認識 ,kafka到底為什么這么厲害,下面總結了11點
1、批量處理
2、客戶端優化
3、日志格式優化
4、日志編碼
5、消息壓縮
6、建立索引
7、分區
8、一致性
9、順序寫盤
10、頁緩存 *
11、零拷貝
有關內存映射:
即便是順序寫入硬盤,硬盤的訪問速度還是不可能追上內存。所以Kafka的數據并不是實時的寫入硬盤,它充分利用了現代操作系統分頁存儲來利用內存提高I/O效率。 Memory Mapped Files(后面簡稱mmap)也被翻譯成內存映射文件,它的工作原理是直接利用操作系統的Page來實現文件到物理內存的直接映射。完成映射之后你對物理內存的操作會被同步到硬盤上(操作系統在適當的時候)。 通過mmap,進程像讀寫硬盤一樣讀寫內存,也不必關心內存的大小有虛擬內存為我們兜底。 mmap其實是Linux中的一個用來實現內存映射的函數,在Java NIO中可用MappedByteBuffer來實現內存映射。
Kafka消息壓縮
生產者發送壓縮消息,是把多個消息批量發送,把多個消息壓縮成一個wrapped message來發送。和普通的消息一樣,在磁盤上的數據和從producer發送來到broker的數據格式一模一樣,發送給consumer的數據也是同樣的格式。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





