溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Python怎么爬取B站排行榜視頻播放量和視頻評論量等數據”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Python怎么爬取B站排行榜視頻播放量和視頻評論量等數據”吧!
小Q發現小P每天在B站的時間特別長,他想和小P深入地交流一下B站,可小Q前段時間學業壓力很大的,一直沒看B站,他想知道現在B站流行什么,那你能幫幫他嗎?
實現爬取當前B站排行榜的內容(爬取任一榜單即可),要求包括視頻排名視頻BV號,視頻封面,視頻播放量,視頻評論量, up主姓名
獲取數據內容
標題
播放量
彈幕量
作者
綜合得分
詳情頁地址
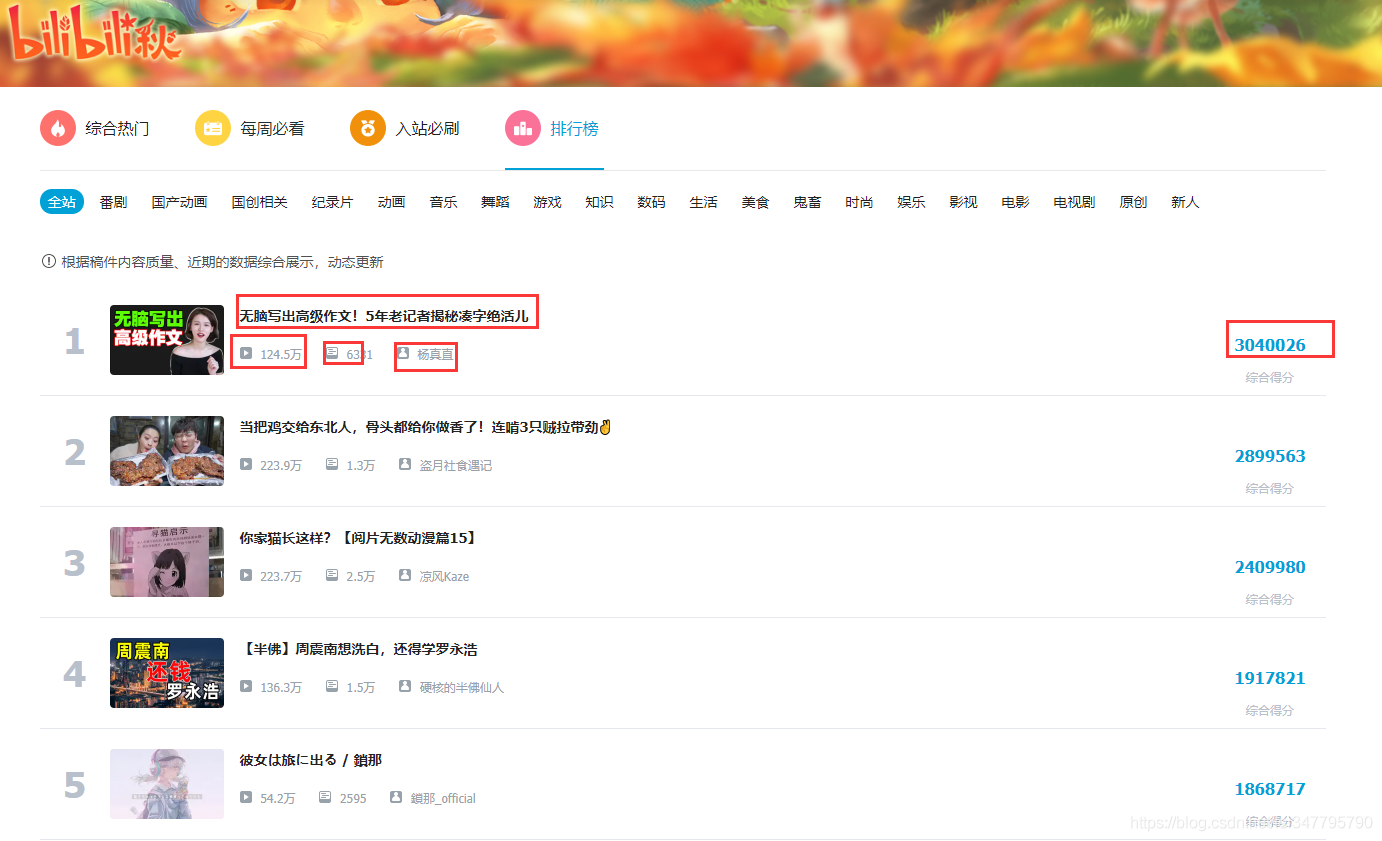
開發者工具一看,好家伙,就這?
當看到這樣的情況,是真的不用分析什么了,直接就可以從頭到尾開始寫代碼了
直接就是爬蟲三部曲走起了。
1、模擬瀏覽器請求網站獲得網頁數據;
2、解析網頁數據,提取想要的內容;
3、保存數據
import requests
import parsel
import csv
f = open('B站排行榜數據.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['標題', '播放量', '彈幕量', '作者', '綜合得分', '視頻地址'])
csv_writer.writeheader()
url = 'https://www.bilibili.com/v/popular/rank/all?spm_id_from=333.851.b_7072696d61727950616765546162.3'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('.rank-list li')
dit = {}
for li in lis:
title = li.css('.info a::text').get() # 標題
bf_info = li.css('div.content > div.info > div.detail > span:nth-child(1)::text').get().strip() # 播放量
dm_info = li.css('div.content > div.info > div.detail > span:nth-child(2)::text').get().strip() # 彈幕量
bq_info = li.css('div.content > div.info > div.detail > a > span::text').get().strip() # 作者
score = li.css('.pts div::text').get() # 綜合得分
page_url = li.css('.img a::attr(href)').get() # 視頻地址
dit = {
'標題': title,
'播放量': bf_info,
'彈幕量': dm_info,
'作者': bq_info,
'綜合得分': score,
'視頻地址': page_url,
}
csv_writer.writerow(dit)
print(dit)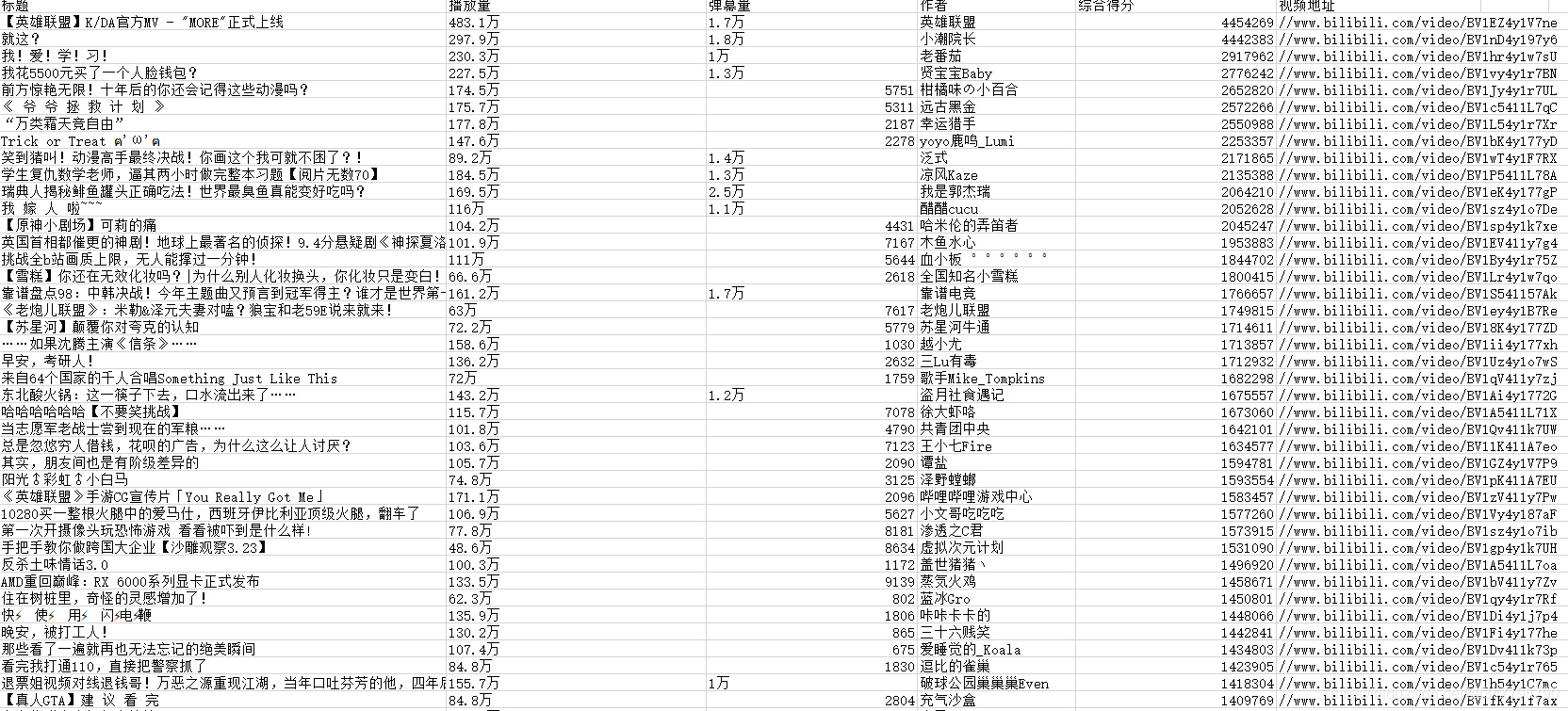
到此,相信大家對“Python怎么爬取B站排行榜視頻播放量和視頻評論量等數據”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





