溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Python3如何利用urllib進行簡單的網頁抓取”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Python3如何利用urllib進行簡單的網頁抓取”這篇文章吧。
運行平臺:Windows
Python版本:Python3.x
IDE:Sublime text3
轉載請注明作者和出處:http://blog.csdn.net/c406495762/article/details/58716886
一直想學習Python爬蟲的知識,在網上搜索了一下,大部分都是基于Python2.x的。因此打算寫一個Python3.x的爬蟲筆記,以便后續回顧,歡迎一起交流、共同進步。
一、預備知識
1.Python3.x基礎知識學習:
可以在通過如下方式進行學習:
(1)廖雪峰Python3教程(文檔):
URL:http://www.liaoxuefeng.com/
(2)菜鳥教程Python3教程(文檔):
URL:http://www.runoob.com/python3/python3-tutorial.html
(3)魚C工作室Python教程(視頻):
小甲魚老師很厲害,講課風格幽默詼諧,如果時間充裕可以考慮看視頻。
URL:http://www.fishc.com/
2.開發環境搭建:
Sublime text3搭建Pyhthon IDE可以查看博客:
URL:http://www.cnblogs.com/nx520zj/p/5787393.html
URL:http://blog.csdn.net/c406495762/article/details/56489253
二、網絡爬蟲的定義
網絡爬蟲,也叫網絡蜘蛛(Web Spider),如果把互聯網比喻成一個蜘蛛網,Spider就是一只在網上爬來爬去的蜘蛛。網絡爬蟲就是根據網頁的地址來尋找網頁的,也就是URL。舉一個簡單的例子,我們在瀏覽器的地址欄中輸入的字符串就是URL,例如:https://www.baidu.com/
URL就是同意資源定位符(Uniform Resource Locator),它的一般格式如下(帶方括號[]的為可選項):
protocol :// hostname[:port] / path / [;parameters][?query]#fragment
URL的格式由三部分組成:
(1)protocol:第一部分就是協議,例如百度使用的就是https協議;
(2)hostname[:port]:第二部分就是主機名(還有端口號為可選參數),一般網站默認的端口號為80,例如百度的主機名就是www.baidu.com,這個就是服務器的地址;
(3)path:第三部分就是主機資源的具體地址,如目錄和文件名等。
網絡爬蟲就是根據這個URL來獲取網頁信息的。
三、簡單爬蟲實例
在Python3.x中,我們可以使用urlib這個組件抓取網頁,urllib是一個URL處理包,這個包中集合了一些處理URL的模塊,如下:
1.urllib.request模塊是用來打開和讀取URLs的;
2.urllib.error模塊包含一些有urllib.request產生的錯誤,可以使用try進行捕捉處理;
3.urllib.parse模塊包含了一些解析URLs的方法;
4.urllib.robotparser模塊用來解析robots.txt文本文件.它提供了一個單獨的RobotFileParser類,通過該類提供的can_fetch()方法測試爬蟲是否可以下載一個頁面。
我們使用urllib.request.urlopen()這個接口函數就可以很輕松的打開一個網站,讀取并打印信息。
urlopen有一些可選參數,具體信息可以查閱Python自帶的documentation。
了解到這些,我們就可以寫一個最簡單的程序,文件名為urllib_test01.py,感受一個urllib庫的魅力:
# -*- coding: UTF-8 -*-from urllib import requestif __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com")
html = response.read()
print(html)urllib使用使用request.urlopen()打開和讀取URLs信息,返回的對象response如同一個文本對象,我們可以調用read(),進行讀取。再通過print(),將讀到的信息打印出來。
運行程序ctrl+b,可以在Sublime中查看運行結果,如下:
也可以在cmd(控制臺)中輸入指令:
python urllib_test01.py
運行py文件,輸出信息是一樣的,如下:
其實這就是瀏覽器接收到的信息,只不過我們在使用瀏覽器的時候,瀏覽器已經將這些信息轉化成了界面信息供我們瀏覽。當然這些代碼我們也可以從瀏覽器中查看到。例如,使用谷歌瀏覽器,在任意界面單擊右鍵選擇檢查,也就是審查元素(不是所有頁面都可以審查元素的,例如起點中文網付費章節就不行.),以百度界面為例,截圖如下:
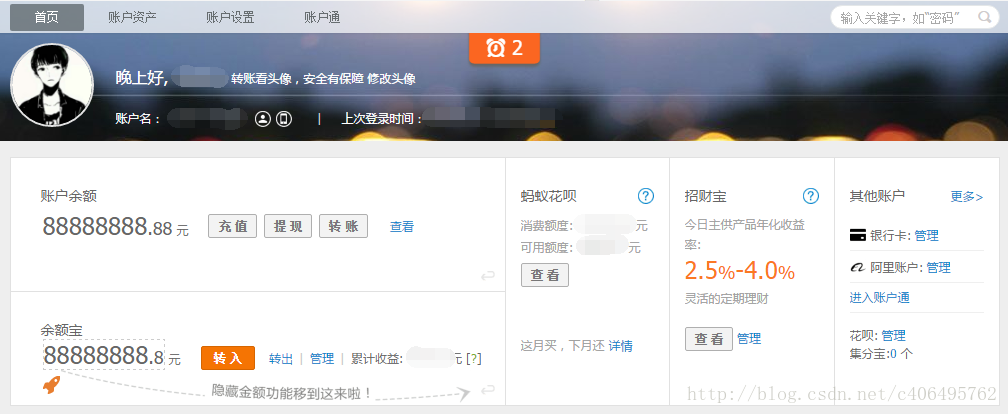
可以看到,右邊就是我們的審查結果。我們可以在本地,也就是瀏覽器(客戶端)更改元素,但是這個不會上傳到服務器端。例如我可以修改自己的支付寶余額裝一裝,比如這樣:
我實際有這些錢嗎?顯然苦逼的我,是不會有這些錢的,我只不過是修改了下審查元素的信息而已。
有些跑偏,不過說的道理就是,瀏覽器就是作為客戶端從服務器端獲取信息,然后將信息解析,再展示給我們的。
回歸正題,雖然我們已經成功獲取了信息,但是顯然他們都是二進制的亂碼,看起來很不方便。我們怎么辦呢?
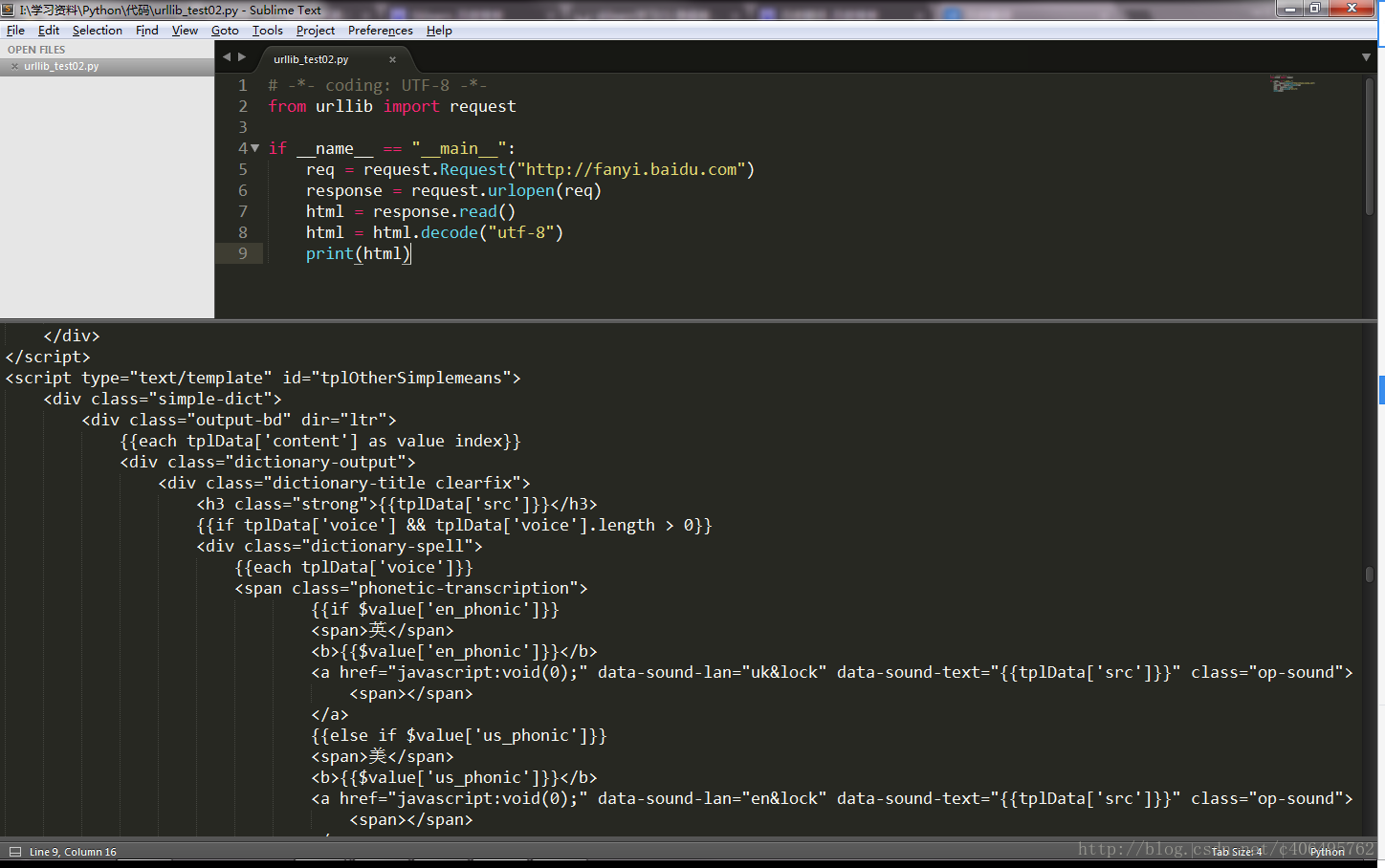
我們可以通過簡單的decode()命令將網頁的信息進行解碼,并顯示出來,我們新創建一個文件,命名為urllib_test02.py,編寫如下代碼(還是以百度翻譯網站fanyi.baidu.com為例):
# -*- coding: UTF-8 -*-from urllib import requestif __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)這樣我們就可以得到這樣的結果,顯然解碼后的信息看起來工整和舒服多了:
當然這個前提是我們已經知道了這個網頁是使用utf-8編碼的,怎么查看網頁的編碼方式呢?需要人為操作,且非常簡單的方法是使用使用瀏覽器審查元素,只需要找到head標簽開始位置的chareset,就知道網頁是采用何種編碼的了。如下:
這樣我們就知道了這個網站的編碼方式,但是這需要我們每次都打開瀏覽器,并找下編碼方式,顯然有些費事,使用幾行代碼解決更加省事并且顯得酷一些。
四、自動獲取網頁編碼方式的方法
獲取網頁編碼的方式有很多,個人更喜歡用第三方庫的方式。
首先我們需要安裝第三方庫chardet,它是用來判斷編碼的模塊,安裝方法如下圖所示,只需要輸入指令:
pip install chardet
安裝好后,我們就可以使用chardet.detect()方法,判斷網頁的編碼方式了。至此,我們就可以編寫一個小程序判斷網頁的編碼方式了,新建文件名為chardet_test01.py:
# -*- coding: UTF-8 -*-from urllib import requestimport chardetif __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/")
html = response.read()
charset = chardet.detect(html)
print(charset)運行程序,查看輸出結果如下:
瞧,返回的是一個字典,這樣我們就知道網頁的編碼方式了,通過獲得的信息,采用不同的解碼方式即可。
以上是“Python3如何利用urllib進行簡單的網頁抓取”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。