溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“有關String源碼知識點總結”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“有關String源碼知識點總結”吧!
不知道大家有沒有這樣得經歷,就是無意中點進去得一個業面,然后鉆到里面瀏覽了好久,我就是這樣得,今天無意中,ctrl+左鍵,就點進了string得源碼,正好今天下午沒啥事,就在里面看一下,沒想到,下次緩過來,就是我同事拍我讓我去吃飯,哈哈哈哈,不過好處就是,我這邊也整理了一些string類得知識點,也分享給大家,整理得不好還望海涵
文章首發個人公眾號:Java架構師聯盟,每日更新技術好文
想要了解一個類,最好的辦法就是看這個類的實現源代碼,來看一下String類的源碼:
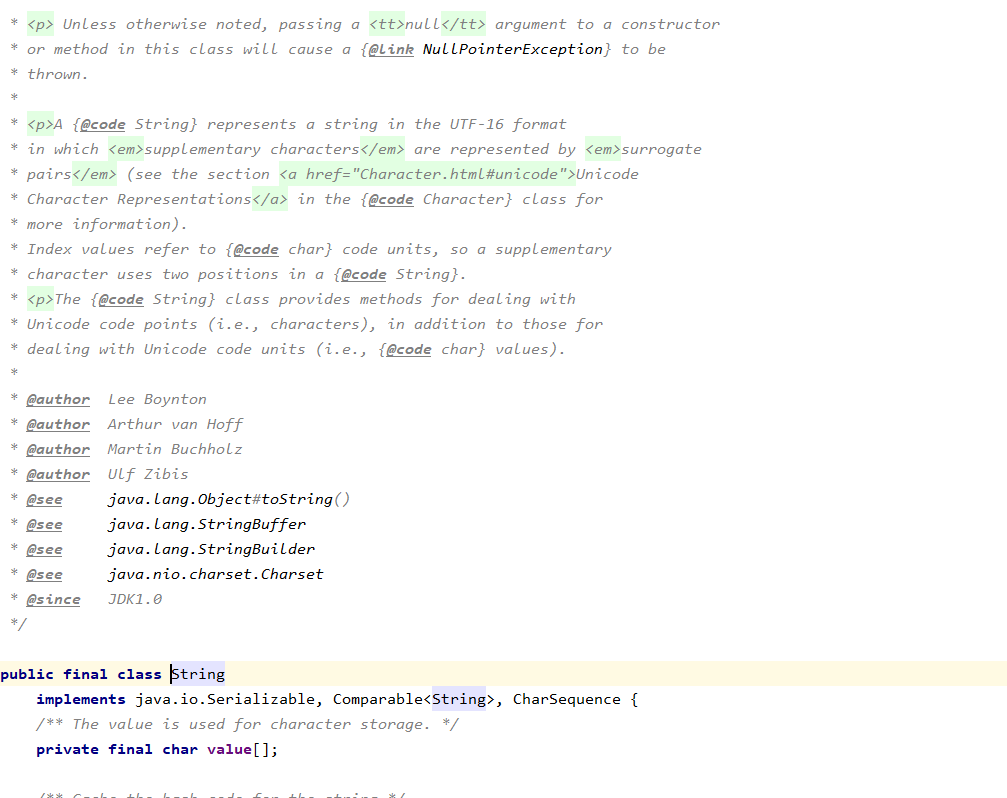
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence
{
/** The value is used for character storage. */
private final char value[];
/** The offset is the first index of the storage that is used. */
private final int offset;
/** The count is the number of characters in the String. */
private final int count;
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
........
}從上面可以看出幾點:
1)String類是final類,也即意味著String類不能被繼承,并且它的成員方法都默認為final方法。在Java中,被final修飾的類是不允許被繼承的,并且該類中的成員方法都默認為final方法。
2)上面列舉出了String類中所有的成員屬性,從上面可以看出String類其實是通過char數組來保存字符串的。
下面再繼續看String類的一些方法實現:
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ? this :
new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
char buf[] = new char[count + otherLen];
getChars(0, count, buf, 0);
str.getChars(0, otherLen, buf, count);
return new String(0, count + otherLen, buf);
}
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = count;
int i = -1;
char[] val = value; /* avoid getfield opcode */
int off = offset; /* avoid getfield opcode */
while (++i < len) {
if (val[off + i] == oldChar) {
break;
}
}
if (i < len) {
char buf[] = new char[len];
for (int j = 0 ; j < i ; j++) {
buf[j] = val[off+j];
}
while (i < len) {
char c = val[off + i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
return new String(0, len, buf);
}
}
return this;
}從上面的三個方法可以看出,無論是sub操、concat還是replace操作都不是在原有的字符串上進行的,而是重新生成了一個新的字符串對象。也就是說進行這些操作后,最原始的字符串并沒有被改變。
在這里要永遠記住一點:“String對象一旦被創建就是固定不變的了,對String對象的任何改變都不影響到原對象,相關的任何change操作都會生成新的對象”。
二、字符串常量池
我們知道字符串的分配和其他對象分配一樣,是需要消耗高昂的時間和空間的,而且字符串我們使用的非常多。JVM為了提高性能和減少內存的開銷,在實例化字符串的時候進行了一些優化:使用字符串常量池。每當我們創建字符串常量時,JVM會首先檢查字符串常量池,如果該字符串已經存在常量池中,那么就直接返回常量池中的實例引用。如果字符串不存在常量池中,就會實例化該字符串并且將其放到常量池中。由于String字符串的不可變性我們可以十分肯定常量池中一定不存在兩個相同的字符串(這點對理解上面至關重要)。
Java中的常量池,實際上分為兩種形態:靜態常量池和運行時常量池。 所謂靜態常量池,即*.class文件中的常量池,class文件中的常量池不僅僅包含字符串(數字)字面量,還包含類、方法的信息,占用class文件絕大部分空間。 而運行時常量池,則是jvm虛擬機在完成類裝載操作后,將class文件中的常量池載入到內存中,并保存在方法區中,我們常說的常量池,就是指方法區中的運行時常量池。
來看下面的程序:
String a = "chenssy"; String b = "chenssy";
a、b和字面上的chenssy都是指向JVM字符串常量池中的"chenssy"對象,他們指向同一個對象。
String c = new String("chenssy");new關鍵字一定會產生一個對象chenssy(注意這個chenssy和上面的chenssy不同),同時這個對象是存儲在堆中。所以上面應該產生了兩個對象:保存在棧中的c和保存堆中chenssy。但是在Java中根本就不存在兩個完全一模一樣的字符串對象。故堆中的chenssy應該是引用字符串常量池中chenssy。所以c、chenssy、池chenssy的關系應該是:c--->chenssy--->池chenssy。整個關系如下:
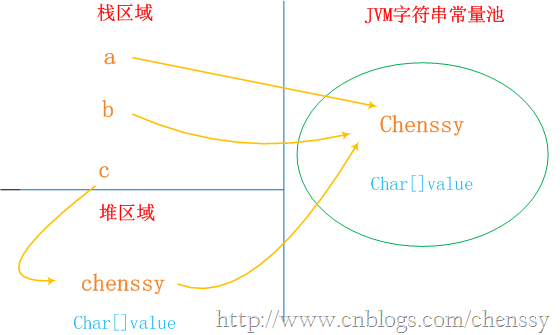
通過上面的圖我們可以非常清晰的認識他們之間的關系。所以我們修改內存中的值,他變化的是所有。
**總結:**雖然a、b、c、chenssy是不同的對象,但是從String的內部結構我們是可以理解上面的。String c = new String("chenssy");雖然c的內容是創建在堆中,但是他的內部value還是指向JVM常量池的chenssy的value,它構造chenssy時所用的參數依然是chenssy字符串常量。
下面再來看幾個例子:
例子1:
/**
* 采用字面值的方式賦值
*/
public void test1(){
String str1="aaa";
String str2="aaa";
System.out.println("===========test1============");
System.out.println(str1==str2);//true 可以看出str1跟str2是指向同一個對象
}執行上述代碼,結果為:true。 分析:當執行String str1="aaa"時,JVM首先會去字符串池中查找是否存在"aaa"這個對象,如果不存在,則在字符串池中創建"aaa"這個對象,然后將池中"aaa"這個對象的引用地址返回給字符串常量str1,這樣str1會指向池中"aaa"這個字符串對象;如果存在,則不創建任何對象,直接將池中"aaa"這個對象的地址返回,賦給字符串常量。當創建字符串對象str2時,字符串池中已經存在"aaa"這個對象,直接把對象"aaa"的引用地址返回給str2,這樣str2指向了池中"aaa"這個對象,也就是說str1和str2指向了同一個對象,因此語句System.out.println(str1 == str2)輸出:true。
例子2:
/**
* 采用new關鍵字新建一個字符串對象
*/
public void test2(){
String str3=new String("aaa");
String str4=new String("aaa");
System.out.println("===========test2============");
System.out.println(str3==str4);//false 可以看出用new的方式是生成不同的對象
}執行上述代碼,結果為:false。
分析: 采用new關鍵字新建一個字符串對象時,JVM首先在字符串池中查找有沒有"aaa"這個字符串對象,如果有,則不在池中再去創建"aaa"這個對象了,直接在堆中創建一個"aaa"字符串對象,然后將堆中的這個"aaa"對象的地址返回賦給引用str3,這樣,str3就指向了堆中創建的這個"aaa"字符串對象;如果沒有,則首先在字符串池中創建一個"aaa"字符串對象,然后再在堆中創建一個"aaa"字符串對象,然后將堆中這個"aaa"字符串對象的地址返回賦給str3引用,這樣,str3指向了堆中創建的這個"aaa"字符串對象。當執行String str4=new String("aaa")時, 因為采用new關鍵字創建對象時,每次new出來的都是一個新的對象,也即是說引用str3和str4指向的是兩個不同的對象,因此語句System.out.println(str3 == str4)輸出:false。
例子3:
/**
* 編譯期確定
*/
public void test3(){
String s0="helloworld";
String s1="helloworld";
String s2="hello"+"world";
System.out.println("===========test3============");
System.out.println(s0==s1); //true 可以看出s0跟s1是指向同一個對象
System.out.println(s0==s2); //true 可以看出s0跟s2是指向同一個對象
}執行上述代碼,結果為:true、true。
分析:因為例子中的s0和s1中的"helloworld”都是字符串常量,它們在編譯期就被確定了,所以s0s1為true;而"hello”和"world”也都是字符串常量,當一個字符串由多個字符串常量連接而成時,它自己肯定也是字符串常量,所以s2也同樣在編譯期就被解析為一個字符串常量,所以s2也是常量池中"helloworld”的一個引用。所以我們得出s0s1==s2。
例子4:
/**
* 編譯期無法確定
*/
public void test4(){
String s0="helloworld";
String s1=new String("helloworld");
String s2="hello" + new String("world");
System.out.println("===========test4============");
System.out.println( s0==s1 ); //false
System.out.println( s0==s2 ); //false
System.out.println( s1==s2 ); //false
}執行上述代碼,結果為:false、false、false。
分析:用new String() 創建的字符串不是常量,不能在編譯期就確定,所以new String() 創建的字符串不放入常量池中,它們有自己的地址空間。
s0還是常量池中"helloworld”的引用,s1因為無法在編譯期確定,所以是運行時創建的新對象"helloworld”的引用,s2因為有后半部分new String(”world”)所以也無法在編譯期確定,所以也是一個新創建對象"helloworld”的引用。
例子5:
/**
* 繼續-編譯期無法確定
*/
public void test5(){
String str1="abc";
String str2="def";
String str3=str1+str2;
System.out.println("===========test5============");
System.out.println(str3=="abcdef"); //false
}執行上述代碼,結果為:false。
分析:因為str3指向堆中的"abcdef"對象,而"abcdef"是字符串池中的對象,所以結果為false。JVM對String str="abc"對象放在常量池中是在編譯時做的,而String str3=str1+str2是在運行時刻才能知道的。new對象也是在運行時才做的。而這段代碼總共創建了5個對象,字符串池中兩個、堆中三個。+運算符會在堆中建立來兩個String對象,這兩個對象的值分別是"abc"和"def",也就是說從字符串池中復制這兩個值,然后在堆中創建兩個對象,然后再建立對象str3,然后將"abcdef"的堆地址賦給str3。
步驟: 1)棧中開辟一塊中間存放引用str1,str1指向池中String常量"abc"。 2)棧中開辟一塊中間存放引用str2,str2指向池中String常量"def"。 3)棧中開辟一塊中間存放引用str3。 4)str1 + str2通過StringBuilder的最后一步toString()方法還原一個新的String對象"abcdef",因此堆中開辟一塊空間存放此對象。 5)引用str3指向堆中(str1 + str2)所還原的新String對象。 6)str3指向的對象在堆中,而常量"abcdef"在池中,輸出為false。
例子6:
/**
* 編譯期優化
*/
public void test6(){
String s0 = "a1";
String s1 = "a" + 1;
System.out.println("===========test6============");
System.out.println((s0 == s1)); //result = true
String s2 = "atrue";
String s3= "a" + "true";
System.out.println((s2 == s3)); //result = true
String s4 = "a3.4";
String s5 = "a" + 3.4;
System.out.println((s4 == s5)); //result = true
}執行上述代碼,結果為:true、true、true。
分析:在程序編譯期,JVM就將常量字符串的"+"連接優化為連接后的值,拿"a" + 1來說,經編譯器優化后在class中就已經是a1。在編譯期其字符串常量的值就確定下來,故上面程序最終的結果都為true。
/**
* 編譯期無法確定
*/
public void test7(){
String s0 = "ab";
String s1 = "b";
String s2 = "a" + s1;
System.out.println("===========test7============");
System.out.println((s0 == s2)); //result = false
}執行上述代碼,結果為:false。
分析:JVM對于字符串引用,由于在字符串的"+"連接中,有字符串引用存在,而引用的值在程序編譯期是無法確定的,即"a" + s1無法被編譯器優化,只有在程序運行期來動態分配并將連接后的新地址賦給s2。所以上面程序的結果也就為false。
例子8:
/**
* 比較字符串常量的“+”和字符串引用的“+”的區別
*/
public void test8(){
String test="javalanguagespecification";
String str="java";
String str1="language";
String str2="specification";
System.out.println("===========test8============");
System.out.println(test == "java" + "language" + "specification");
System.out.println(test == str + str1 + str2);
}執行上述代碼,結果為:true、false。
分析:為什么出現上面的結果呢?這是因為,字符串字面量拼接操作是在Java編譯器編譯期間就執行了,也就是說編譯器編譯時,直接把"java"、"language"和"specification"這三個字面量進行"+"操作得到一個"javalanguagespecification" 常量,并且直接將這個常量放入字符串池中,這樣做實際上是一種優化,將3個字面量合成一個,避免了創建多余的字符串對象。而字符串引用的"+"運算是在Java運行期間執行的,即str + str2 + str3在程序執行期間才會進行計算,它會在堆內存中重新創建一個拼接后的字符串對象。總結來說就是:字面量"+"拼接是在編譯期間進行的,拼接后的字符串存放在字符串池中;而字符串引用的"+"拼接運算實在運行時進行的,新創建的字符串存放在堆中。
對于直接相加字符串,效率很高,因為在編譯器便確定了它的值,也就是說形如"I"+"love"+"java"; 的字符串相加,在編譯期間便被優化成了"Ilovejava"。對于間接相加(即包含字符串引用),形如s1+s2+s3; 效率要比直接相加低,因為在編譯器不會對引用變量進行優化。
例子9:
/**
* 編譯期確定
*/
public void test9(){
String s0 = "ab";
final String s1 = "b";
String s2 = "a" + s1;
System.out.println("===========test9============");
System.out.println((s0 == s2)); //result = true
}執行上述代碼,結果為:true。
分析:和例子7中唯一不同的是s1字符串加了final修飾,對于final修飾的變量,它在編譯時被解析為常量值的一個本地拷貝存儲到自己的常量池中或嵌入到它的字節碼流中。所以此時的"a" + s1和"a" + "b"效果是一樣的。故上面程序的結果為true。
例子10:
/**
* 編譯期無法確定
*/
public void test10(){
String s0 = "ab";
final String s1 = getS1();
String s2 = "a" + s1;
System.out.println("===========test10============");
System.out.println((s0 == s2)); //result = false
}
private static String getS1() {
return "b";
}執行上述代碼,結果為:false。
分析:這里面雖然將s1用final修飾了,但是由于其賦值是通過方法調用返回的,那么它的值只能在運行期間確定,因此s0和s2指向的不是同一個對象,故上面程序的結果為false。
三、總結
1.String類初始化后是不可變的(immutable)
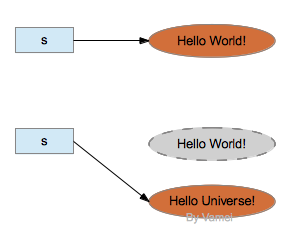
String使用private final char value[]來實現字符串的存儲,也就是說String對象創建之后,就不能再修改此對象中存儲的字符串內容,就是因為如此,才說String類型是不可變的(immutable)。程序員不能對已有的不可變對象進行修改。我們自己也可以創建不可變對象,只要在接口中不提供修改數據的方法就可以。 然而,String類對象確實有編輯字符串的功能,比如replace()。這些編輯功能是通過創建一個新的對象來實現的,而不是對原有對象進行修改。比如:
s = s.replace("World", "Universe");上面對s.replace()的調用將創建一個新的字符串"Hello Universe!",并返回該對象的引用。通過賦值,引用s將指向該新的字符串。如果沒有其他引用指向原有字符串"Hello World!",原字符串對象將被垃圾回收。
2.引用變量與對象
A aa; 這個語句聲明一個類A的引用變量aa[我們常常稱之為句柄],而對象一般通過new創建。所以aa僅僅是一個引用變量,它不是對象。
3.創建字符串的方式
創建字符串的方式歸納起來有兩類:
(1)使用""引號創建字符串;
(2)使用new關鍵字創建字符串。
結合上面例子,總結如下:
(1)單獨使用""引號創建的字符串都是常量,編譯期就已經確定存儲到String Pool中;
(2)使用new String("")創建的對象會存儲到heap中,是運行期新創建的;
new創建字符串時首先查看池中是否有相同值的字符串,如果有,則拷貝一份到堆中,然后返回堆中的地址;如果池中沒有,則在堆中創建一份,然后返回堆中的地址(注意,此時不需要從堆中復制到池中,否則,將使得堆中的字符串永遠是池中的子集,導致浪費池的空間)!
(3)使用只包含常量的字符串連接符如"aa" + "aa"創建的也是常量,編譯期就能確定,已經確定存儲到String Pool中;
(4)使用包含變量的字符串連接符如"aa" + s1創建的對象是運行期才創建的,存儲在heap中;
4.使用String不一定創建對象
在執行到雙引號包含字符串的語句時,如String a = "123",JVM會先到常量池里查找,如果有的話返回常量池里的這個實例的引用,否則的話創建一個新實例并置入常量池里。所以,當我們在使用諸如String str = "abc";的格式定義對象時,總是想當然地認為,創建了String類的對象str。**擔心陷阱!對象可能并沒有被創建!而可能只是指向一個先前已經創建的對象。**只有通過new()方法才能保證每次都創建一個新的對象。
5.使用new String,一定創建對象
在執行String a = new String("123")的時候,首先走常量池的路線取到一個實例的引用,然后在堆上創建一個新的String實例,走以下構造函數給value屬性賦值,然后把實例引用賦值給a:
public String(String original) {
int size = original.count;
char[] originalValue = original.value;
char[] v;
if (originalValue.length > size) {
// The array representing the String is bigger than the new
// String itself. Perhaps this constructor is being called
// in order to trim the baggage, so make a copy of the array.
int off = original.offset;
v = Arrays.copyOfRange(originalValue, off, off+size);
} else {
// The array representing the String is the same
// size as the String, so no point in making a copy.
v = originalValue;
}
this.offset = 0;
this.count = size;
this.value = v;
}從中我們可以看到,雖然是新創建了一個String的實例,但是value是等于常量池中的實例的value,即是說沒有new一個新的字符數組來存放"123"。
6.關于String.intern()
**intern方法使用:**一個初始為空的字符串池,它由類String獨自維護。當調用 intern方法時,如果池已經包含一個等于此String對象的字符串(用equals(oject)方法確定),則返回池中的字符串。否則,將此String對象添加到池中,并返回此String對象的引用。
它遵循以下規則:對于任意兩個字符串 s 和 t,當且僅當 s.equals(t) 為 true 時,s.intern() == t.intern() 因為 true。
String.intern(); 再補充介紹一點:存在于.class文件中的常量池,在運行期間被jvm裝載,并且可以擴充。String的intern()方法就是擴充常量池的一個方法;當一個String實例str調用intern()方法時,java查找常量池中是否有相同unicode的字符串常量,如果有,則返回其引用,如果沒有,則在常量池中增加一個unicode等于str的字符串并返回它的引用。
/**
* 關于String.intern()
*/
public void test11(){
String s0 = "kvill";
String s1 = new String("kvill");
String s2 = new String("kvill");
System.out.println("===========test11============");
System.out.println( s0 == s1 ); //false
System.out.println( "**********" );
s1.intern(); //雖然執行了s1.intern(),但它的返回值沒有賦給s1
s2 = s2.intern(); //把常量池中"kvill"的引用賦給s2
System.out.println( s0 == s1); //flase
System.out.println( s0 == s1.intern() ); //true//說明s1.intern()返回的是常量池中"kvill"的引用
System.out.println( s0 == s2 ); //true
}運行結果:false、false、true、true。
7.關于equals和==
(1)對于==,如果作用于基本數據類型的變量(byte,short,char,int,long,float,double,boolean ),則直接比較其存儲的"值"是否相等;如果作用于引用類型的變量(String),則比較的是所指向的對象的地址(即是否指向同一個對象)。
(2)equals方法是基類Object中的方法,因此對于所有的繼承于Object的類都會有該方法。在Object類中,equals方法是用來比較兩個對象的引用是否相等,即是否指向同一個對象。
(3)對于equals方法,注意:equals方法不能作用于基本數據類型的變量。如果沒有對equals方法進行重寫,則比較的是引用類型的變量所指向的對象的地址;而String類對equals方法進行了重寫,用來比較指向的字符串對象所存儲的字符串是否相等。其他的一些類諸如Double,Date,Integer等,都對equals方法進行了重寫用來比較指向的對象所存儲的內容是否相等。
/**
* 關于equals和==
*/
public void test12(){
String s1="hello";
String s2="hello";
String s3=new String("hello");
System.out.println("===========test12============");
System.out.println( s1 == s2); //true,表示s1和s2指向同一對象,它們都指向常量池中的"hello"對象
//flase,表示s1和s3的地址不同,即它們分別指向的是不同的對象,s1指向常量池中的地址,s3指向堆中的地址
System.out.println( s1 == s3);
System.out.println( s1.equals(s3)); //true,表示s1和s3所指向對象的內容相同
}8.String相關的+:
String中的 + 常用于字符串的連接。看下面一個簡單的例子:
/**
* String相關的+
*/
public void test13(){
String a = "aa";
String b = "bb";
String c = "xx" + "yy " + a + "zz" + "mm" + b;
System.out.println("===========test13============");
System.out.println(c);
}編譯運行后,主要字節碼部分如下:
public static main([Ljava/lang/String;)V L0 LINENUMBER 5 L0 LDC "aa" ASTORE 1 L1 LINENUMBER 6 L1 LDC "bb" ASTORE 2 L2 LINENUMBER 7 L2 NEW java/lang/StringBuilder DUP LDC "xxyy " INVOKESPECIAL java/lang/StringBuilder.<init> (Ljava/lang/String;)V ALOAD 1 INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder; LDC "zz" INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder; LDC "mm" INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder; ALOAD 2 INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder; INVOKEVIRTUAL java/lang/StringBuilder.toString ()Ljava/lang/String; ASTORE 3 L3 LINENUMBER 8 L3 GETSTATIC java/lang/System.out : Ljava/io/PrintStream; ALOAD 3 INVOKEVIRTUAL java/io/PrintStream.println (Ljava/lang/String;)V L4 LINENUMBER 9 L4 RETURN L5 LOCALVARIABLE args [Ljava/lang/String; L0 L5 0 LOCALVARIABLE a Ljava/lang/String; L1 L5 1 LOCALVARIABLE b Ljava/lang/String; L2 L5 2 LOCALVARIABLE c Ljava/lang/String; L3 L5 3 MAXSTACK = 3 MAXLOCALS = 4 }
顯然,通過字節碼我們可以得出如下幾點結論: (1).String中使用 + 字符串連接符進行字符串連接時,連接操作最開始時如果都是字符串常量,編譯后將盡可能多的直接將字符串常量連接起來,形成新的字符串常量參與后續連接(通過反編譯工具jd-gui也可以方便的直接看出);
(2).接下來的字符串連接是從左向右依次進行,對于不同的字符串,首先以最左邊的字符串為參數創建StringBuilder對象,然后依次對右邊進行append操作,最后將StringBuilder對象通過toString()方法轉換成String對象(注意:中間的多個字符串常量不會自動拼接)。
也就是說String c = "xx" + "yy " + a + "zz" + "mm" + b; 實質上的實現過程是: String c = new StringBuilder("xxyy ").append(a).append("zz").append("mm").append(b).toString();
由此得出結論:當使用+進行多個字符串連接時,實際上是產生了一個StringBuilder對象和一個String對象。
9.String的不可變性導致字符串變量使用+號的代價:
String s = "a" + "b" + "c"; String s1 = "a"; String s2 = "b"; String s3 = "c"; String s4 = s1 + s2 + s3;
分析:變量s的創建等價于 String s = "abc"; 由上面例子可知編譯器進行了優化,這里只創建了一個對象。由上面的例子也可以知道s4不能在編譯期進行優化,其對象創建相當于:
StringBuilder temp = new StringBuilder(); temp.append(a).append(b).append(c); String s = temp.toString();
由上面的分析結果,可就不難推斷出String 采用連接運算符(+)效率低下原因分析,形如這樣的代碼:
public class Test {
public static void main(String args[]) {
String s = null;
for(int i = 0; i < 100; i++) {
s += "a";
}
}
}每做一次 + 就產生個StringBuilder對象,然后append后就扔掉。下次循環再到達時重新產生個StringBuilder對象,然后 append 字符串,如此循環直至結束。 如果我們直接采用 StringBuilder 對象進行 append 的話,我們可以節省 N - 1 次創建和銷毀對象的時間。所以對于在循環中要進行字符串連接的應用,一般都是用StringBuffer或StringBulider對象來進行append操作。
10.String、StringBuffer、StringBuilder的區別
(1)可變與不可變:String是不可變字符串對象,StringBuilder和StringBuffer是可變字符串對象(其內部的字符數組長度可變)。
(2)是否多線程安全:String中的對象是不可變的,也就可以理解為常量,顯然線程安全。StringBuffer 與 StringBuilder 中的方法和功能完全是等價的,只是StringBuffer 中的方法大都采用了synchronized 關鍵字進行修飾,因此是線程安全的,而 StringBuilder 沒有這個修飾,可以被認為是非線程安全的。
(3)String、StringBuilder、StringBuffer三者的執行效率: StringBuilder > StringBuffer > String 當然這個是相對的,不一定在所有情況下都是這樣。比如String str = "hello"+ "world"的效率就比 StringBuilder st = new StringBuilder().append("hello").append("world")要高。因此,這三個類是各有利弊,應當根據不同的情況來進行選擇使用: 當字符串相加操作或者改動較少的情況下,建議使用 String str="hello"這種形式; 當字符串相加操作較多的情況下,建議使用StringBuilder,如果采用了多線程,則使用StringBuffer。
11.String中的final用法和理解
final StringBuffer a = new StringBuffer("111");
final StringBuffer b = new StringBuffer("222");
a=b;//此句編譯不通過
final StringBuffer a = new StringBuffer("111");
a.append("222");//編譯通過可見,**final只對引用的"值"(即內存地址)有效,它迫使引用只能指向初始指向的那個對象,改變它的指向會導致編譯期錯誤。**至于它所指向的對象的變化,final是不負責的。
12.關于String str = new String("abc")創建了多少個對象?
這個問題在很多書籍上都有說到比如《Java程序員面試寶典》,包括很多國內大公司筆試面試題都會遇到,大部分網上流傳的以及一些面試書籍上都說是2個對象,這種說法是片面的。
首先必須弄清楚創建對象的含義,創建是什么時候創建的?這段代碼在運行期間會創建2個對象么?毫無疑問不可能,用javap -c反編譯即可得到JVM執行的字節碼內容:
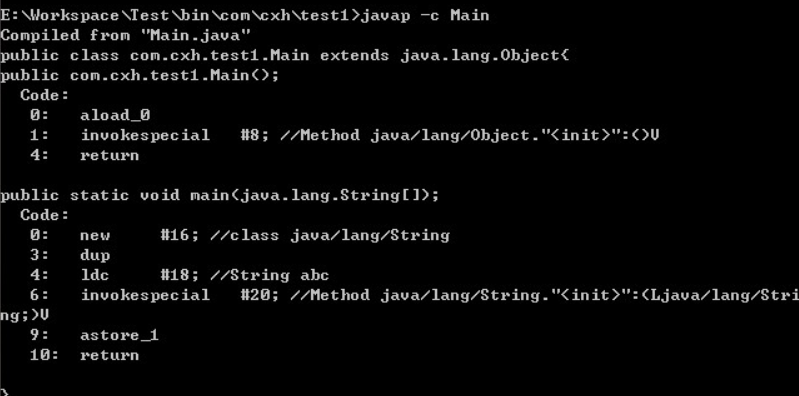
很顯然,new只調用了一次,也就是說只創建了一個對象。而這道題目讓人混淆的地方就是這里,這段代碼在運行期間確實只創建了一個對象,即在堆上創建了"abc"對象。而為什么大家都在說是2個對象呢,這里面要澄清一個概念,該段代碼執行過程和類的加載過程是有區別的。在類加載的過程中,確實在運行時常量池中創建了一個"abc"對象,而在代碼執行過程中確實只創建了一個String對象。 因此,這個問題如果換成 String str = new String("abc")涉及到幾個String對象?合理的解釋是2個。 個人覺得在面試的時候如果遇到這個問題,可以向面試官詢問清楚”是這段代碼執行過程中創建了多少個對象還是涉及到多少個對象“再根據具體的來進行回答。
13.字符串池的優缺點: 字符串池的優點就是避免了相同內容的字符串的創建,節省了內存,省去了創建相同字符串的時間,同時提升了性能;另一方面,字符串池的缺點就是犧牲了JVM在常量池中遍歷對象所需要的時間,不過其時間成本相比而言比較低。
四、綜合實例
package com.spring.test;
public class StringTest {
public static void main(String[] args) {
/**
* 情景一:字符串池
* JAVA虛擬機(JVM)中存在著一個字符串池,其中保存著很多String對象;
* 并且可以被共享使用,因此它提高了效率。
* 由于String類是final的,它的值一經創建就不可改變。
* 字符串池由String類維護,我們可以調用intern()方法來訪問字符串池。
*/
String s1 = "abc";
//↑ 在字符串池創建了一個對象
String s2 = "abc";
//↑ 字符串pool已經存在對象“abc”(共享),所以創建0個對象,累計創建一個對象
System.out.println("s1 == s2 : "+(s1==s2));
//↑ true 指向同一個對象,
System.out.println("s1.equals(s2) : " + (s1.equals(s2)));
//↑ true 值相等
//↑------------------------------------------------------over
/**
* 情景二:關于new String("")
*
*/
String s3 = new String("abc");
//↑ 創建了兩個對象,一個存放在字符串池中,一個存在與堆區中;
//↑ 還有一個對象引用s3存放在棧中
String s4 = new String("abc");
//↑ 字符串池中已經存在“abc”對象,所以只在堆中創建了一個對象
System.out.println("s3 == s4 : "+(s3==s4));
//↑false s3和s4棧區的地址不同,指向堆區的不同地址;
System.out.println("s3.equals(s4) : "+(s3.equals(s4)));
//↑true s3和s4的值相同
System.out.println("s1 == s3 : "+(s1==s3));
//↑false 存放的地區多不同,一個棧區,一個堆區
System.out.println("s1.equals(s3) : "+(s1.equals(s3)));
//↑true 值相同
//↑------------------------------------------------------over
/**
* 情景三:
* 由于常量的值在編譯的時候就被確定(優化)了。
* 在這里,"ab"和"cd"都是常量,因此變量str3的值在編譯時就可以確定。
* 這行代碼編譯后的效果等同于: String str3 = "abcd";
*/
String str1 = "ab" + "cd"; //1個對象
String str11 = "abcd";
System.out.println("str1 = str11 : "+ (str1 == str11));
//↑------------------------------------------------------over
/**
* 情景四:
* 局部變量str2,str3存儲的是存儲兩個拘留字符串對象(intern字符串對象)的地址。
*
* 第三行代碼原理(str2+str3):
* 運行期JVM首先會在堆中創建一個StringBuilder類,
* 同時用str2指向的拘留字符串對象完成初始化,
* 然后調用append方法完成對str3所指向的拘留字符串的合并,
* 接著調用StringBuilder的toString()方法在堆中創建一個String對象,
* 最后將剛生成的String對象的堆地址存放在局部變量str3中。
*
* 而str5存儲的是字符串池中"abcd"所對應的拘留字符串對象的地址。
* str4與str5地址當然不一樣了。
*
* 內存中實際上有五個字符串對象:
* 三個拘留字符串對象、一個String對象和一個StringBuilder對象。
*/
String str2 = "ab"; //1個對象
String str3 = "cd"; //1個對象
String str4 = str2+str3;
String str5 = "abcd";
System.out.println("str4 = str5 : " + (str4==str5)); // false
//↑------------------------------------------------------over
/**
* 情景五:
* JAVA編譯器對string + 基本類型/常量 是當成常量表達式直接求值來優化的。
* 運行期的兩個string相加,會產生新的對象的,存儲在堆(heap)中
*/
String str6 = "b";
String str7 = "a" + str6;
String str67 = "ab";
System.out.println("str7 = str67 : "+ (str7 == str67));
//↑str6為變量,在運行期才會被解析。
final String str8 = "b";
String str9 = "a" + str8;
String str89 = "ab";
System.out.println("str9 = str89 : "+ (str9 == str89));
//↑str8為常量變量,編譯期會被優化
//↑------------------------------------------------------over
}
}運行結果:
s1 == s2 : true s1.equals(s2) : true s3 == s4 : false s3.equals(s4) : true s1 == s3 : false s1.equals(s3) : true str1 = str11 : true str4 = str5 : false str7 = str67 : false str9 = str89 : true
感謝各位的閱讀,以上就是“有關String源碼知識點總結”的內容了,經過本文的學習后,相信大家對有關String源碼知識點總結這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





