溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹Elasticsearch寫入數據底層的示例分析,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
Document(文檔): 文檔是存儲在elasticsearch中的一個JSON文件,相當于關系數據庫中表的一行數據。
Shard(分片):索引數據可以拆分為較小的分片,每個分片放到不同的服務器上,提高并發能力。 Lucene 中的 Lucene index 相當于 ES 的一個 shard。
Segments(段): 分片由多個segments組成,每個segments都是一個獨立的倒排索引,且具有不變性,segment 提供了搜索功能。
Transaction Log(translog,事務日志):Elasticsearch使用translog來記錄index,delete,update,bulk請求,保障數據不丟失,如果Elasticsearch需要恢復數據可以從translog中讀取。每個分片對應一個translog文件。
Commit point(提交點):記錄著所有已知的segment,每個Shard都有一個Commit point, 其中保存了當前Shard成功寫入磁盤的所有Segment。
Lucene index :由一堆 Segment 的集合加上一個Commit point組成。
OS Cache: Lucene 中的倒排索引 segments 存儲在文件中,為提高訪問速度,都會把它加載到OS Cache中,從而提高 Lucene 性能,所以建議至少留系統一半內存給Lucene。
Node Query Cache:負責緩存filter 查詢結果,每個節點有一個,被所有 shard 共享,filter query查詢結果不涉及 scores 的計算。
Indexing Buffe:索引緩沖區,用于存儲新索引的文檔,當其被填滿時,緩沖區中的文檔被寫入磁盤中的 segments 中。
Shard Request Cache: 用于緩存aggregations,suggestions,hits.total的請求結果。
Field Data Cache:Elasticsearch 加載內存 fielddata 的默認行為是延遲加載 。在首次對text類型字段做聚合、排序或者在腳本中使用時,需要設置字段為fielddata數據結構,它將會完整加載這個字段所有 Segment 中的倒排索引到堆內存中。不推薦使用,因為fielddata會占用大量堆內存空間 ,聚合或者排序使用doc_value。
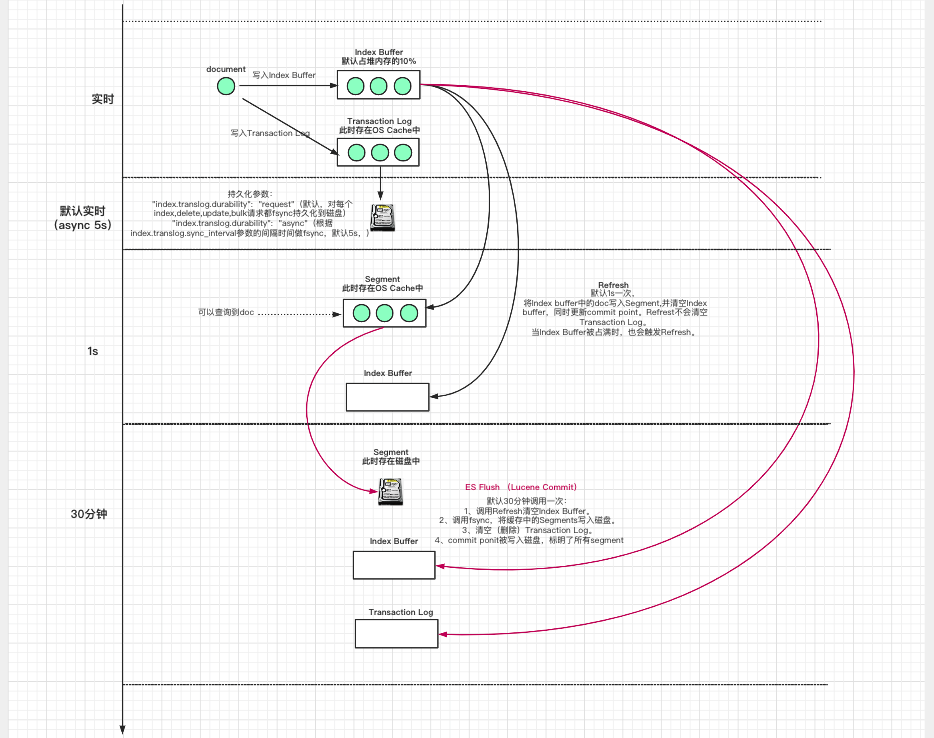
1.數據寫入Index Buffer緩沖和Translog日志文件。
為了保證數據不會丟失,從高版本開始Transaction Log對每個index,delete,update,bulk請求都fsync持久化到磁盤。
2.Refresh:將Index Buffer寫入Segment的過程叫做Refresh。
每隔1s,Index Buffer中的數據被寫入新的Segment(OS Cache中),此時Segment被打開并提供Search。Refresh后,數據就可以被搜索到了,這也是為什么Elasticsearch被稱為近實時搜索的原因。
當Index Buffer被占滿時,會觸發Refresh,默認值是JVM堆內存的10%。
Refresh不執行fsync操作,不會清空Transaction Log。
3.重復1~2步,新的Segment不斷添加,Index Buffer不斷被清空,而Transaction Log中的數據不斷累加。
4.每隔30分鐘或者當Transaction Log用滿時(默認512M),ES Flush (Lucene Commit) 操作發生:
4.1 調用Refresh清空Index Buffer。
4.2 調用fsync,將緩存中的Segments寫入磁盤。
4.3 清空(刪除)Transaction Log。
4.4 Commit ponit被寫入磁盤,每個Shard都有一個Commit point, 其中保存了當前Shard成功寫入磁盤的所有Segment。
PUT my-index/_settings
{
"refresh_interval": "60s" #默認1s
}PUT my-index/_settings
{
"translog.flush_threshold_size": "1gb", #默認512M,當 translog 超過該值,會觸發 flush
"translog.sync_interval": "60s", #默認5s
"translog.durability": "async" #默認是 request,每個請求都落盤,忽視translog.sync_interval。設置成 async,異步寫入,根據index.translog.sync_interval參數的間隔時間做fsync。
}關于Elasticsearch寫入數據底層的示例分析就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





