溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹pig的原理及特點是什么,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
Apache Pig是MapReduce的一個抽象。它是一個工具/平臺,用于分析較大的數據集,并將它們表示為數據流。Pig通常與 Hadoop 一起使用;我們可以使用Apache Pig在Hadoop中執行所有的數據處理操作。
要使用 Apache Pig 分析數據,程序員需要使用Pig Latin語言編寫腳本。所有這些腳本都在內部轉換為Map和Reduce任務。Apache Pig有一個名為 Pig Engine 的組件,它接受Pig Latin腳本作為輸入,并將這些腳本轉換為MapReduce作業。
為什么要使用Apache Pig
使用 Pig Latin ,程序員可以輕松地執行MapReduce作業,而無需在Java中鍵入復雜的代碼。
Apache Pig使用多查詢方法,從而減少代碼長度。例如,需要在Java中輸入200行代碼(LoC)的操作在Apache Pig中輸入少到10個LoC就能輕松完成。最終,Apache Pig將開發時間減少了近16倍。
Pig Latin是類似SQL的語言,當你熟悉SQL后,很容易學習Apache Pig。
Apache Pig提供了許多內置操作符來支持數據操作,如join,filter,ordering等。此外,它還提供嵌套數據類型,例如tuple(元組),bag(包)和MapReduce缺少的map(映射)。
Apache Pig具有以下特點:
豐富的運算符集 - 它提供了許多運算符來執行諸如join,sort,filer等操作。
易于編程 - Pig Latin與SQL類似,如果你善于使用SQL,則很容易編寫Pig腳本。
優化機會 - Apache Pig中的任務自動優化其執行,因此程序員只需要關注語言的語義。
可擴展性 - 使用現有的操作符,用戶可以開發自己的功能來讀取、處理和寫入數據。
用戶定義函數 - Pig提供了在其他編程語言(如Java)中創建用戶定義函數的功能,并且可以調用或嵌入到Pig腳本中。
處理各種數據 - Apache Pig分析各種數據,無論是結構化還是非結構化,它將結果存儲在HDFS中。
下面列出的是Apache Pig和MapReduce之間的主要區別。
| Apache Pig | MapReduce |
|---|---|
| Apache Pig是一種數據流語言。 | MapReduce是一種數據處理模式。 |
它是一種高級語言。 | MapReduce是低級和剛性的。 |
| 在Apache Pig中執行Join操作非常簡單。 | 在MapReduce中執行數據集之間的Join操作是非常困難的。 |
| 任何具備SQL基礎知識的新手程序員都可以方便地使用Apache Pig工作。 | 向Java公開是必須使用MapReduce。 |
| Apache Pig使用多查詢方法,從而在很大程度上減少代碼的長度。 | MapReduce將需要幾乎20倍的行數來執行相同的任務。 |
| 沒有必要編譯。執行時,每個Apache Pig操作符都在內部轉換為MapReduce作業。 | MapReduce作業具有很長的編譯過程。 |
下面列出了Apache Pig和SQL之間的主要區別。
| Pig | SQL |
| Pig Latin是一種程序語言。 | SQL是一種聲明式語言。 |
| 在Apache Pig中,模式是可選的。我們可以存儲數據而無需設計模式(值存儲為01,01, 02等) | 模式在SQL中是必需的。 |
| Apache Pig中的數據模型是嵌套關系。 | SQL 中使用的數據模型是平面關系。 |
| Apache Pig為查詢優化提供有限的機會。 | 在SQL中有更多的機會進行查詢優化。 |
除了上面的區別,Apache Pig Latin:
允許在pipeline(流水線)中拆分。
允許開發人員在pipeline中的任何位置存儲數據。
聲明執行計劃。
提供運算符來執行ETL(Extract提取,Transform轉換和Load加載)功能。
Apache Pig和Hive都用于創建MapReduce作業。在某些情況下,Hive以與Apache Pig類似的方式在HDFS上運行。在下表中,我們列出了幾個重要的點區分Apache Pig與Hive。
| Apache Pig | Hive |
|---|---|
| Apache Pig使用一種名為 Pig Latin 的語言(最初創建于 Yahoo )。 | Hive使用一種名為 HiveQL 的語言(最初創建于Facebook )。 |
| Pig Latin是一種數據流語言。 | HiveQL是一種查詢處理語言。 |
| Pig Latin是一個過程語言,它適合流水線范式。 | HiveQL是一種聲明性語言。 |
| Apache Pig可以處理結構化,非結構化和半結構化數據。 | Hive主要用于結構化數據。 |
Apache Pig通常被數據科學家用于執行涉及特定處理和快速原型設計的任務。使用Apache Pig:
處理巨大的數據源,如Web日志。
為搜索平臺執行數據處理。
處理時間敏感數據的加載
用于使用Pig分析Hadoop中的數據的語言稱為 Pig Latin ,是一種高級數據處理語言,它提供了一組豐富的數據類型和操作符來對數據執行各種操作。
要執行特定任務時,程序員使用Pig,需要用Pig Latin語言編寫Pig腳本,并使用任何執行機制(Grunt Shell,UDFs,Embedded)執行它們。執行后,這些腳本將通過應用Pig框架的一系列轉換來生成所需的輸出。
Apache Pig的架構
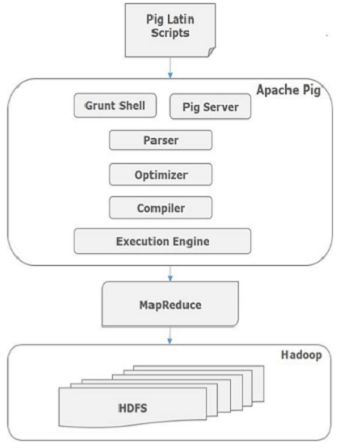
如圖所示,Apache Pig框架中有各種組件。讓我們來看看主要的組件。
最初,Pig腳本由解析器處理,它檢查腳本的語法,類型檢查和其他雜項檢查。解析器的輸出將是DAG(有向無環圖),它表示Pig Latin語句和邏輯運算符。在DAG中,腳本的邏輯運算符表示為節點,數據流表示為邊。
邏輯計劃(DAG)傳遞到邏輯優化器,邏輯優化器執行邏輯優化,例如投影和下推。
編譯器將優化的邏輯計劃編譯為一系列MapReduce作業。
最后,MapReduce作業以排序順序提交到Hadoop。這些MapReduce作業在Hadoop上執行,產生所需的結果。
Pig Latin的數據模型是完全嵌套的,它允許復雜的非原子數據類型,例如 map 和 tuple 。
Pig Latin中的任何單個值,無論其數據類型,都稱為 Atom 。它存儲為字符串,可以用作字符串和數字。int,long,float,double,chararray和bytearray是Pig的原子值。一條數據或一個簡單的原子值被稱為字段。例:“raja“或“30"
由有序字段集合形成的記錄稱為元組,字段可以是任何類型。元組與RDBMS表中的行類似。例:(Raja,30)
一個包是一組無序的元組。換句話說,元組(非唯一)的集合被稱為包。每個元組可以有任意數量的字段(靈活模式)。包由“{}"表示。它類似于RDBMS中的表,但是與RDBMS中的表不同,不需要每個元組包含相同數量的字段,或者相同位置(列)中的字段具有相同類型。
例:{(Raja,30),(Mohammad,45)}
包可以是關系中的字段;在這種情況下,它被稱為內包(inner bag)。
例:{Raja,30, {9848022338,raja@gmail.com,} }
映射(或數據映射)是一組key-value對。key需要是chararray類型,且應該是唯一的。value可以是任何類型,它由“[]"表示,
例:[name#Raja,age#30]
一個關系是一個元組的包。Pig Latin中的關系是無序的(不能保證按任何特定順序處理元組)。
關于pig的原理及特點是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





