溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“R語言的聚類方法介紹”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
一、層次聚類
1)距離和相似系數
r語言中使用dist(x, method = “euclidean”,diag = FALSE, upper = FALSE, p = 2) 來計算距離。其中x是樣本矩陣或者數據框。method表示計算哪種距離。method的取值有:
euclidean 歐幾里德距離,就是平方再開方
maximum 切比雪夫距離
manhattan 絕對值距離
canberra Lance 距離
minkowski 明科夫斯基距離,使用時要指定p值
binary 定性變量距離.
定性變量距離: 記m個項目里面的 0:0配對數為m0 ,1:1配對數為m1,不能配對數為m2,距離=m1/(m1+m2);
diag 為TRUE的時候給出對角線上的距離。upper為TURE的時候給出上三角矩陣上的值。
r語言中使用scale(x, center = TRUE, scale = TRUE) 對數據矩陣做中心化和標準化變換。
如只中心化 scale(x,scale=F) ,
r語言中使用sweep(x, MARGIN, STATS, FUN=”-“, …) 對矩陣進行運算。MARGIN為1,表示行的方向上進行運算,為2表示列的方向上運算。STATS是運算的參數。FUN為運算函數,默認是減法。下面利用sweep對矩陣x進行極差標準化變換

有時候我們不是對樣本進行分類,而是對變量進行分類。這時候,我們不計算距離,而是計算變量間的相似系數。常用的有夾角和相關系數。
r語言計算兩向量的夾角余弦:

相關系數用cor函數
2)層次聚類法
層次聚類法。先計算樣本之間的距離。每次將距離最近的點合并到同一個類。然后,再計算類與類之間的距離,將距離最近的類合并為一個大類。不停的合并,直到合成了一個類。其中類與類的距離的計算方法有:最短距離法,最長距離法,中間距離法,類平均法等。比如最短距離法,將類與類的距離定義為類與類之間樣本的最段距離。。。
r語言中使用hclust(d, method = “complete”, members=NULL) 來進行層次聚類。
其中d為距離矩陣。
method表示類的合并方法,有:
single 最短距離法
complete 最長距離法
median 中間距離法
mcquitty 相似法
average 類平均法
centroid 重心法
ward 離差平方和法
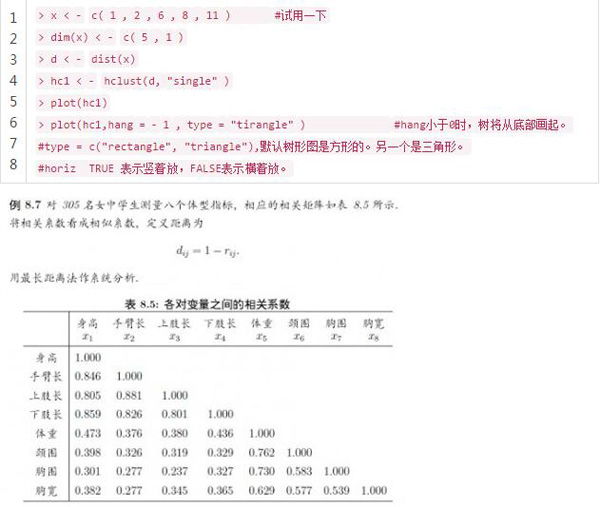

然后可以用rect.hclust(tree, k = NULL, which = NULL, x = NULL, h = NULL,border = 2, cluster = NULL)來確定類的個數。 tree就是求出來的對象。k為分類的個數,h為類間距離的閾值。border是畫出來的顏色,用來分類的。
二、動態聚類k-means
層次聚類,在類形成之后就不再改變。而且數據比較大的時候更占內存。
動態聚類,先抽幾個點,把周圍的點聚集起來。然后算每個類的重心或平均值什么的,以算出來的結果為分類點,不斷的重復。直到分類的結果收斂為止。r語言中主要使用kmeans(x, centers, iter.max = 10, nstart = 1,algorithm =c(“Hartigan-Wong”, “Lloyd”,”Forgy”, “MacQueen”))來進行聚類。centers是初始類的個數或者初始類的中心。iter.max是***迭代次數。nstart是當centers是數字的時候,隨機集合的個數。algorithm是算法,默認是***個。
使用knn包進行Kmean聚類分析
將數據集進行備份,將列newiris$Species置為空,將此數據集作為測試數據集

在數據集newiris上運行Kmean聚類分析, 將聚類結果保存在kc中。在kmean函數中,將需要生成聚類數設置為

Cluster means: 每個聚類中各個列值生成的最終平均值

Clustering vector: 每行記錄所屬的聚類(2代表屬于第二個聚類,1代表屬于***個聚類,3代表屬于第三個聚類)

Within cluster sum of squares by cluster: 每個聚類內部的距離平方和

(between_SS / total_SS = 88.4 %) 組間的距離平方和占了整體距離平方和的的88.4%,也就是說各個聚類間的距離做到了***
Available components: 運行kmeans函數返回的對象所包含的各個組成部分

(“cluster”是一個整數向量,用于表示記錄所屬的聚類
“centers”是一個矩陣,表示每聚類中各個變量的中心點
“totss”表示所生成聚類的總體距離平方和
“withinss”表示各個聚類組內的距離平方和
“tot.withinss”表示聚類組內的距離平方和總量
“betweenss”表示聚類組間的聚類平方和總量
“size”表示每個聚類組中成員的數量)
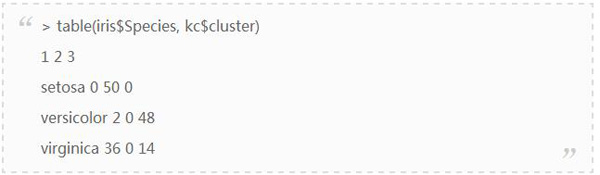
創建一個連續表,在三個聚類中分別統計各種花出現的次數
根據***的聚類結果畫出散點圖,數據為結果集中的列”Sepal.Length”和”Sepal.Width”,顏色為用1,2,3表示的缺省顏色

在圖上標出每個聚類的中心點

三、DBSCAN
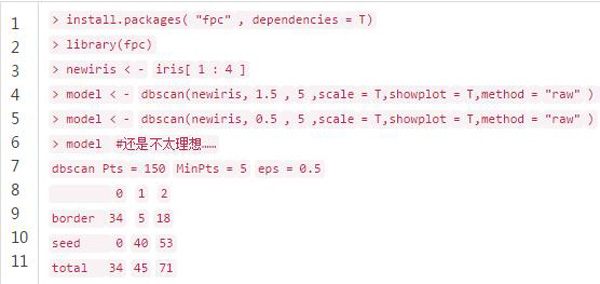
動態聚類往往聚出來的類有點圓形或者橢圓形。基于密度掃描的算法能夠解決這個問題。思路就是定一個距離半徑,定最少有多少個點,然后把可以到達的點都連起來,判定為同類。在r中的實現

其中eps是距離的半徑,minpts是最少多少個點。 scale是否標準化(我猜) ,method 有三個值raw,dist,hybird,分別表示,數據是原始數據避免計算距離矩陣,數據就是距離矩陣,數據是原始數據但計算部分距離矩陣。showplot畫不畫圖,0不畫,1和2都畫。countmode,可以填個向量,用來顯示計算進度。用鳶尾花試一試
“R語言的聚類方法介紹”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





