溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關 ElasticSearch的常用術語有哪些,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
這篇文章主要介紹 ElasticSearch 的基本概念,學習文檔、索引、集群、節點、分片等概念,同時會將 ElasticSearch 和關系型數據庫做簡單的類比,還會簡單介紹 REST API 的使用用法。
ElasticSearch 術語
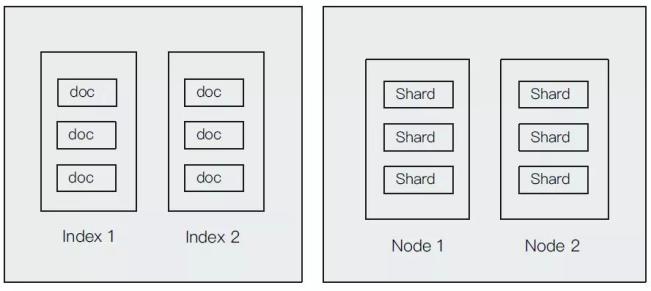
索引和文檔是偏向于邏輯上的概念,節點和分片更偏向于物理上的概念。
首先來說下什么是文檔:
文檔(Document)
ElasticSearch(簡稱 ES) 是面向文檔的,文檔是所有可搜索數據的最小單位。
給大家舉幾個例子,讓大家更形象地理解什么是文檔:
日志文件中日志項
一本電影的具體信息、一張唱片的詳細信息
MP3 播放器里的一首歌、一篇 PDF 文檔中的具體內容
一條客戶數據、一條商品分類數據、一條訂單數據
大家可以把文檔理解為關系型數據庫中的一條記錄。
在 ES 中文檔會被序列化成 JSON 格式,保存在 ES 中,JSON 對象由字段組成,其中每個字段都有對應的字段類型(字符串/數組/布爾/日期/二進制/范圍類型)。
在 ES 中,每個文檔都有一個 Unique ID,可以自己指定 ID 或者通過 ES 自動生成。
在上一篇文章手把手教你搭建 ELK 實時日志分析平臺中,我們講到了通過 Logstash 向 ES 中導入數據,其中部分測試數據集和對應的轉換后的格式如下所示:
movieId,title,genres 193585,Flint (2017),Drama 193587,Bungo Stray Dogs: Dead Apple (2018),Action|Animation 193609,Andrew Dice Clay: Dice Rules (1991),Comedy
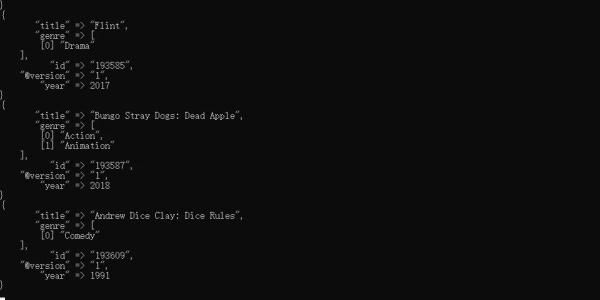
我們從測試數據集 csv 文件中讀取一個個的 RowData 的電影數據,然后通過 Logstash 轉換進行轉化以后進入到 ES 中就是 JSON 格式。
JSON 每個字段都有自己的數據類型,ES 可以幫助你自動做做一個數據類型的推算,并且在 ES 中數據還支持數組和嵌套。
每一個文檔都有對應的元數據,用于標注文檔的相關信息,我們來了解下元數據都有什么內容:
{ "_index" : "movies", "_type" : "_doc", "_id" : "2035", "_score" : 1.0, "_source" : { "title" : "Blackbeard's Ghost", "genre" : [ "Children", "Comedy" ], "id" : "2035", "@version" : "1", "year" : 1968 } }其中,_index 代表文檔所屬的索引名;_type 表示文檔所屬的類型名;_id 為文檔唯一 id;_source 為文檔的原始 JSON 數據,當搜索文檔的時候默認返回的就是 _source 字段;@version 為文檔的版本信息,可以很好地來解決版本沖突的問題;_score為相關性打分,是這個文檔在這次查詢中的算分。
介紹完文檔后,讓我們來看下索引:
索引(Index)
索引簡單來說就是相似結構文檔的集合,比如可以有一個客戶索引,商品分類索引,訂單索引,索引有一個名稱,一個索引可以包含很多文檔,一個索引就代表了一類類似的或者相同的文檔,比如說建立一個商品索引,里面可能就存放了所有的商品數據,也就是所有的商品文檔。每一個索引都是自己的 Mapping 定義文件,用來去描述去包含文檔字段的類型,分片(Shard)體現的是物理空間的概念,索引中的數據分散在分片上。
在一個的索引當中,可以去為它設置 Mapping 和 Setting,Mapping 定義的是索引當中所有文檔字段的類型結構,Setting 主要是指定要用多少的分片以及數據是怎么樣進行分布的。
索引在不同的上下文會有不同的含義,比如,在 ES 當中,索引是一類文檔的集合,這里就是名詞;同時保存一個文檔到 ES 的過程也叫索引(indexing),拋開 ES,提到索引,還有可能是 B 樹索引或者是倒排索引,倒排索引是 ES 中一個重要的數據結構,會在以后的文章進行講解。
接下來對類型進行講解:
類型(Type)
在 7.0 之前,每一個索引是可以設置多個 Types 的,每個 Type 會擁有相同結構的文檔,但是在 6.0 開始,Type 已經被廢除,在 7.0 開始,一個索引只能創建一個 Type,也就是 _doc。
每個索引里都可以有一個或多個 Type,Type 是索引中的一個邏輯數據分類,一個 Type 下的文檔,都有相同的字段(Field),比如博客系統,有一個索引,可以定義用戶數據 Type,博客數據 Type,評論數據 Type 等。
到此為止,我們學習了文檔、索引以及類型的概念,接下來學習什么是集群?什么是節點?什么是分片?
首先來看下集群的概念。
集群(Cluster)
ES 集群其實是一個分布式系統,要滿足高可用性,高可用就是當集群中有節點服務停止響應的時候,整個服務還能正常工作,也就是服務可用性;或者說整個集群中有部分節點丟失的情況下,不會有數據丟失,即數據可用性。
當用戶的請求量越來越高,數據的增長越來越多的時候,系統需要把數據分散到其他節點上,最后來實現水平擴展。當集群中有節點出現問題的時候,整個集群的服務也不會受到影響。
ES 的分布架構當中,不同的集群是通過不同的名字來區分的,默認的名字為 elasticsearch,可以在配置文件中進行修改,或者在命令行中使用 -E cluster.name=wupx 進行設定,一個集群中可以有一個或者多個節點。
一個 ES 集群有三種顏色來表示健康程度:
Green:主分片與副本都正常分配
Yellow:主分片全部正常分配,有副本分片未能正常分配
Red:有主分片未能分配(例如,當服務器的磁盤容量超過 85% 時,去創建了一個新的索引)
了解完集群,那么就來看下什么是節點。
節點(Node)
節點其實就是一個 ES 實例,本質上是一個 Java 進程,一臺機器上可以運行多個 ES 進程,但是生產環境一般建議一臺機器上只運行一個 ES 實例。
每一個節點都有自己的名字,節點名稱很重要(在執行運維管理操作的時候),可以通過配置文件進行配置,或者啟動的時候 -E node.name=node1 指定。每一個節點在啟動之后,會分配一個 UID,保存在 data 目錄下。
默認節點會去加入一個名稱為 elasticsearch 的集群,如果直接啟動很多節點,那么它們會自動組成一個 elasticsearch 集群,當然一個節點也可以組成一個 elasticsearch 集群。
候選主節點(Master-eligible Node) & 主節點(Master Node)
每一個節點啟動后,默認就是一個 Master-eligible 節點,可以通過在配置文件中設置 node.master: false 禁止,Master-eligible 節點可以參加選主流程,成為 Master 節點。當第一個節點啟動時候,它會將自己選舉成 Master 節點。
每個節點上都保存了集群的狀態,只有 Master 節點才能修改集群的狀態信息,如果是任意節點都能修改信息就會導致數據的不一致性。
集群狀態(Cluster State),維護一個集群中必要的信息,主要包括如下信息:
所有的節點信息
所有的索引和其相關的 Mapping 與 Setting 信息
分片的路由信息
下面我們來看下什么是 Data Node 和 Coordinating Node?
數據節點(Data Node) & 協調節點(Coordinating Node)
顧名思義,可以保存數據的節點叫作 Data Node,負責保存分片上存儲的所有數據,當集群無法保存現有數據的時候,可以通過增加數據節點來解決存儲上的問題,在數據擴展上有至關重要的作用。
Coordinating Node 負責接收 Client 的請求,將請求分發到合適的節點,最終把結果匯集到一起返回給客戶端,每個節點默認都起到了 Coordinating Node 的職責。
還有其他的節點類型,大家可以了解下:
其他節點類型
冷熱節點(Hot & Warm Node) :熱節點(Hot Node)就是配置高的節點,可以有更好的磁盤吞吐量和更好的 CPU,那冷節點(Warm Node)存儲一些比較久的節點,這些節點的機器配置會比較低。不同硬件配置的 Data Node,用來實現 Hot & Warm 架構,降低集群部署的成本。
機器學習節點(Machine Learning Node):負責跑機器學習的工作,用來做異常檢測。
部落節點(Tribe Node):連接到不同的 ES 集群,并且支持將這些集群當成一個單獨的集群處理。
預處理節點(Ingest Node):預處理操作允許在索引文檔之前,即寫入數據之前,通過事先定義好的一系列的 processors(處理器)和 pipeline(管道),對數據進行某種轉換、富化。
每個節點在啟動的時候會通過讀取 elasticsearch.yml 配置文件決定自己承擔什么樣的角色,那么讓我們看下配置節點類型吧!
配置節點類型
開發環境中一個節點可以承擔多種角色。
生產環境中,應該設置單一的角色的節點(dedicated node)。

講完節點,讓我們來看下什么是分片?
分片(Shard)
由于單臺機器無法存儲大量數據,ES 可以將一個索引中的數據切分為多個分片(Shard),分布在多臺服務器上存儲。有了分片就可以橫向擴展,存儲更多數據,讓搜索和分析等操作分布到多臺服務器上去執行,提升吞吐量和性能。
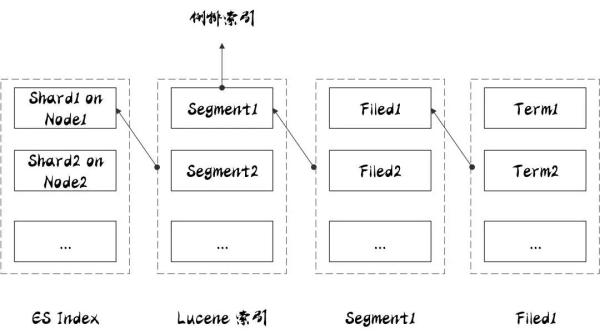
索引與分片的關系如上圖所示,一個 ES 索引包含很多分片,一個分片是一個 Lucene 的索引,它本身就是一個完整的搜索引擎,可以獨立執行建立索引和搜索任務。Lucene 索引又由很多分段組成,每個分段都是一個倒排索引。 ES 每次 refresh 都會生成一個新的分段,其中包含若干文檔的數據。在每個分段內部,文檔的不同字段被單獨建立索引。每個字段的值由若干詞(Term)組成,Term 是原文本內容經過分詞器處理和語言處理后的最終結果(例如,去除標點符號和轉換為詞根)。
分片分為兩類,一類為主分片(Primary Shard),另一類為副本分片(Replica Shard)。
主分片主要用以解決水平擴展的問題,通過主分片,就可以將數據分布到集群上的所有節點上,一個主分片就是一個運行的 Lucene 實例,當我們在創建 ES 索引的時候,可以指定分片數,但是主分片數在索引創建時指定,后續不允許修改,除非使用 Reindex 進行修改。
副本分片用以解決數據高可用的問題,也就是說集群中有節點出現硬件故障的時候,通過副本的方式,也可以保證數據不會產生真正的丟失,因為副本分片是主分片的拷貝,在索引中副本分片數可以動態調整,通過增加副本數,可以在一定程度上提高服務查詢的性能(讀取的吞吐)。
下面通過一個例子來理解下主分片和副本分片是怎么樣把數據分散在集群不同的節點上的:
PUT /blogs { "settings" :{ "number_of_shards" : 3, "number_of_repicas" : 1 } }上面是 blogs 索引的定義,其中 settings 中的 number_of_shards 表示主分片數為 3,number_of_repicas 表示副本只有 1 份。
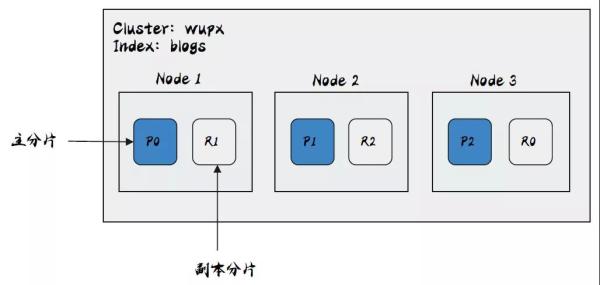
上圖為 wupx 的一個集群,里面總共有 3 個節點,通過上面對索引 blogs 的配置,當有數據進來的時候,ES 內部就會把主分片分散在三個節點上,同時把每個分片的副本分散到其他節點上,當集群中有節點出現故障,ES 內部就會產生故障轉移的機制,故障轉移機制會在以后的文章進行講解,在上圖中可以看到三個主分片被分散到三個節點上,若在這個時候為集群增加一個節點,是否可以增加系統的可用性呢?
帶著這個問題,我們先看下分片的設定:
分片的設定
分片的設定在生產環境中是十分重要的,很多時候需要提前做好容量規劃,因為主分片在索引創建的時候需要預先設定的,并且在事后無法修改,在前面的例子中,一個索引被分成了 3 個主分片,這個集群即便增加再多節點,索引也只能分散在 3 個節點上。
分片設置過大的時候,也會帶來副作用,一方面來說會影響搜索結果的打分,影響統計結果的準確性,另外,單個節點上過多的分片,也會導致資源浪費,同時也會影響性能。從 7.0 版本開始,ES 的默認主分片數設置從 5 改為了 1,從這個方面也可以解決 over-sharding 的問題。
在了解完 ES 的術語后,來和我們熟悉的關系型數據庫做個類比,以便于我們理解。
RDBMS & ES
我相信大家對關系型數據庫(簡稱 RDBMS)應該比較了解,因此接下來拿關系型數據庫和 ES 做一個類比,讓大家更容易理解:

從表中,不難看出,關系型數據庫和 ES 有如下對應關系:
關系型數據庫中的表(Table)對于 ES 中的索引(Index)
關系型數據庫中的每條記錄(Row)對應 ES 中的文檔(Document)
關系型數據庫中的字段(Column)對應 ES 中的字段(Filed)
關系型數據庫中的表定義(Schema)對應著 ES 中的映射(Mapping)
關系型數據庫中可以通過 SQL 進行查詢等操作,在 ES 中也提供了 DSL 進行查詢等操作
當進行全文檢索或者對搜索結果進行算分的時候,ES 比較合適,但如果對數據事務性要求比較高的時候,會把關系型數據庫和 ES 結合使用。
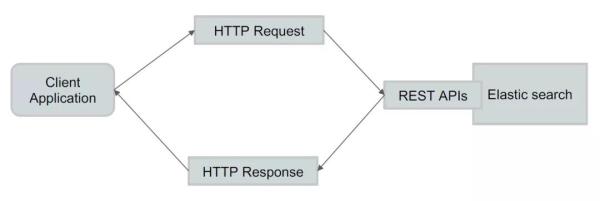
為了方便其他語言的整合,ES 提供了 REST API 來給其他程序進行調用,當我們的程序要和 ES 進行集成的時候,只需要發出 HTTP 的請求就會得到相應的結果,接下來對基本的 API 進行介紹:
REST API
打開 Kibana,我們首先打開 Kibana 的管理菜單(Management),其中提供索引管理功能,可以看到索引管理中有 movies 索引,為上篇文章中導入的,點擊索引,可以看到索引的 Setting 和 Mapping 信息,如何對其進行設置會在之后的文章會進行介紹。
言歸正傳,來給大家看 REST API:
接下來打開 Kibana 的開發工具(Dev Tools),movies 為索引,現在輸入 GET movies點擊執行,就可以查看電影索引相關的信息,主要包含索引的 Mapping 和 Setting。
輸入 GET movies/_count 點擊執行,就可以看到索引的文檔總數,運行結果如下:
{ "count" : 9743, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 } }輸入如下代碼
POST movies/_search { }點擊執行,就可以查看前 10 條文檔,了解文檔格式。
還可以對索引的名字進行通配符查詢,使用 GET /_cat/indices/mov*?v&s=index ,可以查看匹配的索引。
使用 GET /_cat/indices?v&s=docs.count:desc,可以按照文檔個數排序。
使用 GET /_cat/indices?v&health=green,可以查看狀態為 green 的索引。
使用 GET /_cat/indices?v&h=i,tm&s=tm:desc,可以查看每個索引占用的內存。
ES 還提供了 API 去查看集群的健康狀況,使用 GET _cluster/health 可以集群的健康狀況,返回結果如下:
{ "cluster_name" : "wupx", "status" : "green", "timed_out" : false, "number_of_nodes" : 2, "number_of_data_nodes" : 2, "active_primary_shards" : 10, "active_shards" : 10, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }可以看到集群名字叫 wupx,集群狀態是 green,一共有 2 個節點,這兩個節點都是承擔 Data Node 角色,另外還有 10 個主分片。
REST API 就介紹到這里,其余的大家可以自己去摸索下。
細心的小伙伴會發現 Kibana 怎么變成中文界面了,其實 Kibana 在 7.0 版本之后,官方自帶漢化資源文件(位于 Kibana 目錄下的 node_modules/x-pack/plugins/translations/translations/),大家可以在 config 目錄下修改 kibana.yml 文件,在文件中加上配置項 i18n.locale: "zh-CN",然后重新啟動 Kibana 就漢化完成了。
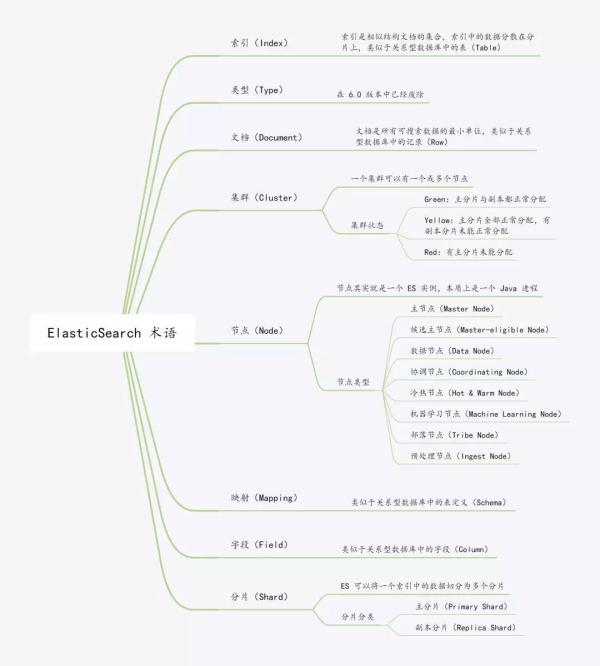
本文主要學習了文檔、索引、集群、節點等概念,了解到每個集群中每個節點可以承擔不同的角色,還了解了什么是主分片和副本分片以及它們在分布式系統中起到的作用,還通過和關系型數據庫做類比,讓大家更易理解,另外還介紹了 REST API 使用,最后給大家總結下 ES 術語的思維導圖,思維導圖源文件可以在公眾號武培軒回復es獲取。
看完上述內容,你們對 ElasticSearch的常用術語有哪些有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





