溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹數億MySQL數據七步走到MongoDB的操作過程,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
一、問題
在好大夫在線內部,S3系統負責各業務方操作日志的集中存儲、查詢和管理。目前,該系統日均查詢量數千萬次,插入量數十萬次。隨著日志量的不斷累積,主表已經達到數十億,單表占用磁盤空間400G+。S3是業務早期就存在的系統,當時為了簡單快速落地,使用了MySQL來存儲,隨著業務的不斷增長,同時也要兼顧性能和可擴展性,到了必須要重新選型的時候了。
新項目命名為:LogStore。
二、目標
1、安全性
S3系統在設計之初,沒有按業務系統考慮數據隔離,而是直接采用 key(系統 + 類名 + id) + 有限固定字段 + 序列化value 的方式進行存儲,這種方式顯然不便于后續集群拆分和管理。LogStore系統要在邏輯上進行數據區域劃分,業務方在接入時要指定app進行必要的權限驗證,以區分不同業務數據,進而再進行插入和查詢操作。
2、通用性
S3主要提供一種3層結構,采用MySQL固定字段進行存儲,這就不可避免的會造成字段空間的浪費。LogStore系統需要提供一種通用的日志存儲格式,由業務方自行規定字段含義,并且保留一定程度的可查詢維度。
3、高性能
S3系統的QPS在300+,單條數據最大1KB左右。LogStore系統要支持當前QPS 10倍以上的寫入和讀取速度。
4、可審計
要滿足內部安全審計的要求,LogStore系統不提供對數據的更新,只允許數據的插入和查詢。
5、易擴展
LogStore系統以及底層存儲要滿足可擴展特性,可以在線擴容,滿足公司未來5年甚至更長時間的日志存儲需求,并且要最大化節省磁盤空間。
三、方案選型
為了達成改造目標,本次調研了四種存儲改造方案,各種方案對比如下:

1、我們不合適—分庫分表
分庫分表主要分為應用層依賴類中間件和代理中間件,無論哪種均需要修改現有PHP和Java框架,同時對DBA管理數據也帶來一定的操作困難。為了降低架構復雜度,架構團隊否定了引入DB中間件的方案,還是要求運維簡單、成本低的方案。
2、我們不合適—TiDB
TiDB也曾一度進入了我們重點調研對象,只是由于目前公司的DB生態主要還是在MGR、MongoDB、MySQL上,在可預見的需求中,也沒有能充分發揮TiDB的場景,所以就暫時擱置了。
3、我們不合適—ElasticSearch
ELK-stack提供的套件確實讓ES很有吸引力,公司用ES集群也有較長時間了。ES優勢在于檢索和數據分析領域,也正是因為其檢索和分析的功能的強大,無論寫入、查詢和存儲成本都比較高,在日志處理的這個場景下,性價比略低,所以也被pass了。
4、適合的選擇—MongoDB
業務操作日志讀多寫少,很適合文檔型數據庫MongoDB的特點。同時,MongoDB在業界得到了廣泛的使用,公司也有很多業務在使用,在MongoDB上積累了一定的運維經驗,最終決定選擇MongoDB作為新日志系統存儲方案。
四、性能測試
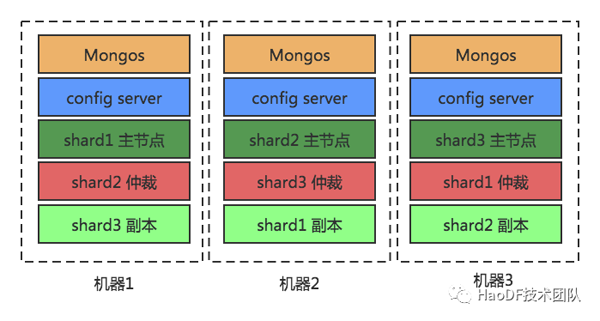
為了驗證MongoDB的性能能否達到要求,我們搭建了MongoDB集群,機器配置、架構圖和測試結果如下:
1、機器配置
MongoDB集群3臺機器配置如下:
CPU | 內存 | 硬盤 | OS | Mongo版本 |
8核 | 15G MongoDB 內存分配單節點8G | 100G | CentOS release 6.6 (Final) | 3.2.17 |
2、架構圖架構圖
3、測試場景架構圖
本次MongoDB測試采用YCSB(https://github.com/brianfrankcooper/YCSB)性能測試工具,ycsb的workloads目錄下保存了6種不同的workload類型,代表了不同的壓測負載類型,本次我們只用到了其中5種,具體場景和測試結果如下。
workloada | 100%插入,用來加載測試數據 |
workloadb | 讀多寫少,90%讀,10%更新。 |
workloadc | 讀多寫少,100%讀。 |
workloadd | 讀多寫少,90%讀,10%插入。 |
workloadf | 混合讀寫,50%讀,25%插入、25%更新 |
(1) 插入平均文檔大小為5K,數據量為100萬,并發100,數據量總共5.265G 左右,執行的時間以及磁盤壓力:
結論:插入100w數據,總耗時219s,平均insert耗時21.8ms,吞吐量4568/s。
(2) 測試90%讀,10%更新,并發100的場景:
結論:總耗時236s,read平均耗時23.6ms,update平均耗時23.56ms,吞吐量達到4225/s。
(3) 測試讀多寫少,100%讀 ,并發100場景:
結論:總耗時123s,平均read耗時12.3ms,吞吐量達到8090/s。
(4) 測試讀多寫少,90%讀,10%插入,并發100的場景:
結論:總耗時220s,read平均耗時21.9ms,insert平均耗時21.9ms,吞吐量達到4541/s。
(5) 測試混合讀寫,50%讀,25%插入、25%更新,并發100的場景:
結論:總耗時267s,read平均耗時26.7ms,update平均耗時26.7ms,insert平均耗時26.6ms,吞吐量為3739/s。
4、測試結果對比架構圖

可以看出MongoDB適合讀多寫少的時候,性能最好,讀寫速率能滿足生產需求。
五、無縫遷移實踐
為了保障業務的無縫遷移,也為了最大化降低業務研發同學的投入成本,我們決定采用分階段切換的方案。
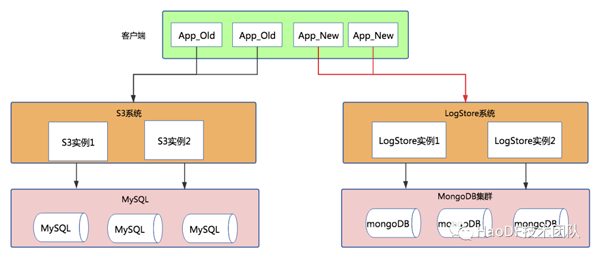
第一步:系統應用層改造+LogStore系統搭建
首先,在S3系統中內置讀開關和寫開關,可將讀寫流量分別引入到LogStore系統中,而新應用的接入可以直接調用LogStore系統,此時結構示意圖如下。
第二步:增量數據同步
為了讓S3系統和LogStore系統中新增數據達到一致,在底層數據庫采用Maxwell訂閱MySQL Binlog的方式同步到MongoDB中,示意圖如下:
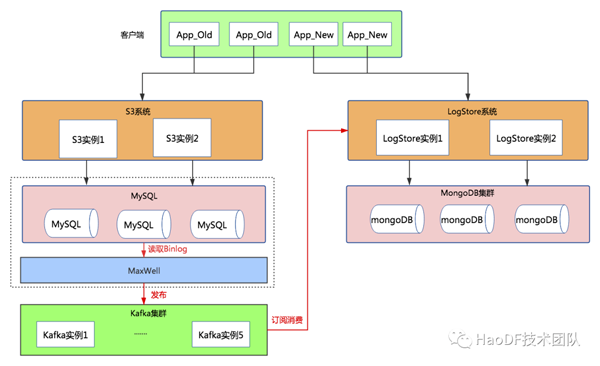
Maxwell(http://maxwells-daemon.io)實時讀取MySQL二進制日志binlog,并生成 JSON 格式的消息,作為生產者發送給 Kafka,Logstore系統消費Kafka中的數據寫入到mongodb數據庫中。
至此,對于業務方現有日志類型,新增數據在底層達到雙寫目的,S3系統和LogStore系統存儲兩份數據;如果業務方新增日志類型,則直接調用LogStore系統接口即可。接下來,我們將對已有日志類型老數據進行遷移。
第三步:存量數據遷移
此次遷移S3老數據采用php定時任務腳本(多個)查詢數據,將數據投遞到RabbitMQ隊列中,LogStore系統從RabbitMQ隊列拉取消息進行消費存儲到MongoDB中,示意圖如下:

(1) 由于原mysql表中id為varchar類型并且非主鍵索引,只能利用ctime索引分批次進行查詢,數據密集處進行chunk投遞到mq隊列中。
(2) 數據無法一天就遷移完,遷移過程中可能存在中斷的情況。腳本采用定時任務每天執行20h, 在上線時間停止執行,同時將停止時間記錄到Redis中。
(3) 由于需要遷移數據量較大,在mq和消費者能承受的情況下,盡可能多地增加腳本數量,縮短導數據的時間。
(4) 腳本執行期間,觀察業務延時情況和MySQL監控情況,發現有影響立即進行調整,以保障不影響正常業務。
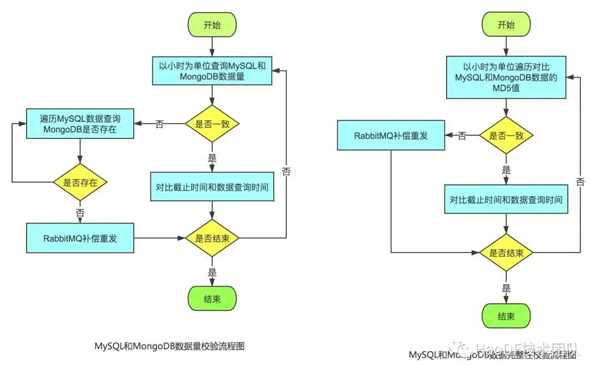
第四步:校驗數據
老數據導入完成后,下面就要對老數據進行校驗,校驗從兩個方面進行: 數據量和數據完整性。
數據量:基于S3系統老數據的id, 查詢在MongoDB中是否存在,如果不存在則進行補償重發;
數據完整性:對于S3和MongoDB中的數據按照相同規則進行md5校驗,校驗不通過則進行補償重發。
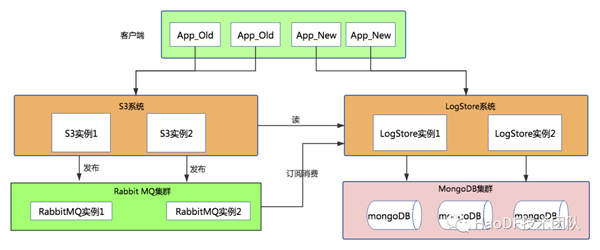
第五步:數據雙寫
將應用層預制的寫開關打開,將流量導入到LogStore中,此時MySQL的流量并沒有停掉,繼續執行binlog同步。結構如下:

從圖中可以看到,從S3調用點的寫接口的流量都寫入到MongoDB數據庫backuplogs集合中,為什么不直接寫入到logs表中呢?留個小懸念,在后文中有解釋。
第六步:灰度切換S3讀到LogStore系統
上文我們提到,對于S3系統應用層讀寫調用點均分別內置了切換開關,打開應用層讀開關,所有的讀操作全部走LogStore, 切換后示意圖如下所示:
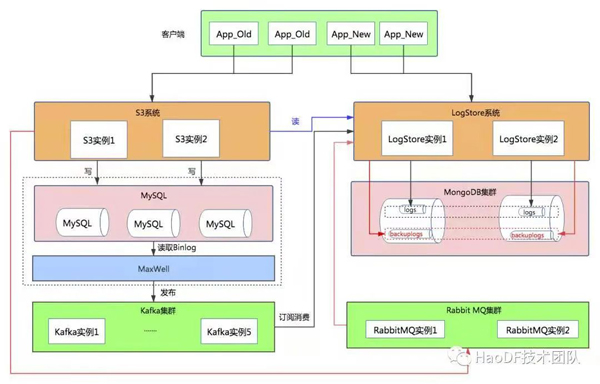
第七步:灰度切換寫接口到LogStore系統
打開應用層寫開關,所有寫操作會通過mq異步寫到MongoDB中,那如何證明應用層寫調用點修改完全了呢?
上文中雙寫數據一份到logs表中,一份到backuplogs表中,通過Maxwell的Binlog同步的數據肯定是最全的,數據量上按理來說 count( logs) >= count(backuplogs), 如果兩個集合一段時間內的數據增量相同,則證明寫調用點修改完全,可以去掉雙寫,只保留LogStore這條線,反之需要檢查修改再次驗證。切換寫完成后,示意圖如下:
六、MongoDB與故障演練
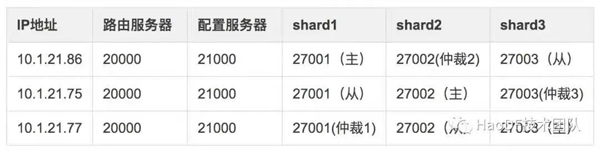
故障演練能夠檢測服務是否真正高可用,及時發現系統薄弱的環節,提前準備好預案減少故障恢復時間。為了驗證MongoDB是否真正高可用,我們在線下搭建了MongoDB集群:
同時,我們編寫腳本模擬用戶MongoDB數據插入和讀取,基于好大夫在線自研故障演練平臺,對機器進行故障注入,查看各種故障對用戶的影響。故障演練內容CPU、內存、磁盤、網絡和進程Kill等操作,詳情如下圖所示:
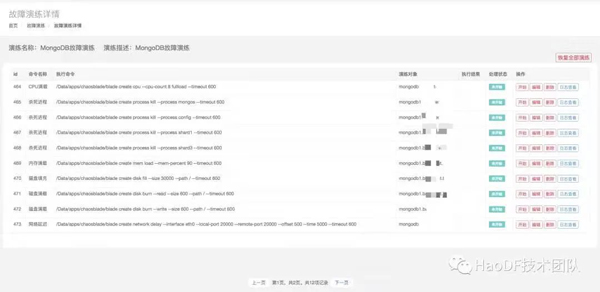
實驗結果:
CPU、磁盤填充和磁盤負載對MongoDB集群影響較小;
內存滿載可能會發生系統OOM,導致MongoDB進程被操作系統Kill,由于MongoDB存在數據副本和自動主從切換,對用戶影響較小;
網絡抖動、延遲和丟包會導致mongos連接服務器時間變長,客戶端卡頓的現象發生,可通過網絡監控的手段監測;
分別主動Kill掉MongoDB的主節點、從節點、仲裁節點、mongos、config節點,對整個集群影響較小。
整體而言,MongoDB存在副本和自動主從切換,客戶端存在自動檢測重連機制,單個機器發生故障時對整體集群可用性影響較小。同時,可增加對單機器的資源進行監控,達到閾值進行報警,減小故障發現和恢復時間。
1、MongoDB的使用
MongoDB數據寫入可能各個分片不均勻,此時可以開啟塊均衡策略;由于均衡器會增加系統負載,最好選擇在業務量較小的時候進行;
合理選擇分片鍵和建立索引,會使你的查詢速度更快,這個要具體場景具體分析。
2、遷移數據
必須保留唯一標識數據的字段,最好是主鍵id,方便校驗數據;
一定要考慮多進程,腳本要自動化,縮短遷移時間和減小人工介入;
遷移過程中,要時刻關注數據庫、中間件及應用相關指標,防止導出導入數據影響正常業務;
要在同樣配置的環境下充分演練,提前制定數據比對測試用例,以防止數據丟失;
每一步線上操作(如切換讀寫),都要有對應的回滾計劃,最大限度降低對業務的影響。
關于數億MySQL數據七步走到MongoDB的操作過程就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





