溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“如何使用高并發大對象處理”,在日常操作中,相信很多人在如何使用高并發大對象處理問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”如何使用高并發大對象處理”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
常年浸潤在互聯網高并發中的同學,在寫代碼時會有一些約定俗成的規則:寧可將請求拆分成10個1秒的,也不去做一個耗時5秒的請求;寧可將對象拆成1000個10KB的,也盡量避免生成一個1MB的對象。
為什么?這是對于“大”的恐懼。
“大對象”,是一個泛化的概念,它可能存放在JVM中,也可能正在網絡上傳輸,也可能存在于數據庫中。
為什么大對象會影響我們的應用性能呢?有三點原因。
大對象占用的資源多,垃圾回收器要花一部分精力去對它進行回收;
大對象在不同的設備之間交換,會耗費網絡流量,以及昂貴的I/O;
對大對象的解析和處理操作是耗時的,對象職責不聚焦,就會承擔額外的性能開銷。
接下來,xjjdog將從數據的結構緯度和時間維度,來逐步看一下一些把對象變小,把操作聚焦的策略。
1. String的substring方法
我們都知道,String在Java中是不可變的,如果你改動了其中的內容,它就會生成一個新的字符串。
如果我們想要用到字符串中的一部分數據,就可以使用substring方法。
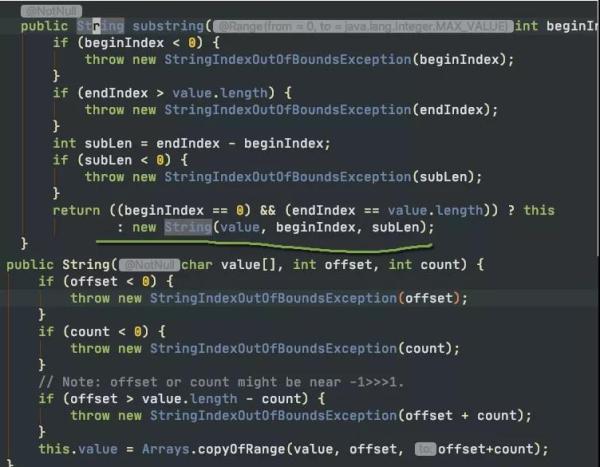
如圖所示,當我們需要一個子字符串的時候。substring生成了一個新的字符串,這個字符串通過構造函數的Arrays.copyOfRange函數進行構造。
這個函數在JDK7之后是沒有問題的,但在JDK6中,卻有著內存泄漏的風險。我們可以學習一下這個案例,來看一下大對象復用可能會產生的問題。
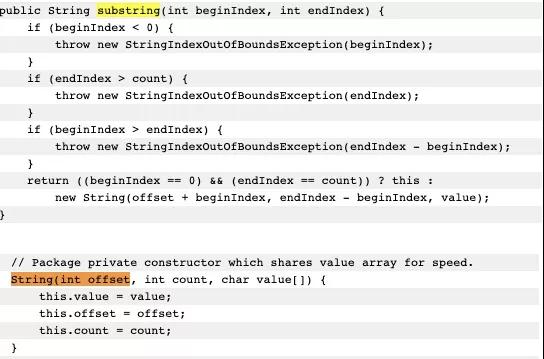
這是我從JDK官方的一張截圖。可以看到,它在創建子字符串的時候,并不只拷貝所需要的對象,而是把整個value引用了起來。如果原字符串比較大,即使不再使用,內存也不會釋放。
比如,一篇文章內容可能有幾MB,我們僅僅需要其中的摘要信息,也不得維持著整個的大對象。
String content = dao.getArticle(id); String summary=content.substring(0,100); articles.put(id,summary);
這對我們的借鑒意義是。如果你創建了比較大的對象,并基于這個對象生成了一些其他的信息。這個時候,一定要記得去掉和這個大對象的引用關系。
2. 集合大對象擴容
對象擴容,在Java中是司空見慣的現象。比如StringBuilder、StringBuffer,HashMap,ArrayList等。概括來講,Java的集合,包括List、Set、Queue、Map等,其中的數據都不可控。在容量不足的時候,都會有擴容操作。
我們先來看下StringBuilder的擴容代碼。
void expandCapacity(int minimumCapacity) { int newCapacity = value.length * 2 + 2; if (newCapacity - minimumCapacity < 0) newCapacity = minimumCapacity; if (newCapacity < 0) { if (minimumCapacity < 0) // overflow throw new OutOfMemoryError(); newCapacity = Integer.MAX_VALUE; } value = Arrays.copyOf(value, newCapacity); }容量不夠的時候,會將內存翻倍,并使用Arrays.copyOf復制源數據。
下面是HashMap的擴容代碼,擴容后大小也是翻倍。它的擴容動作就復雜的多,除了有負載因子的影響,它還需要把原來的數據重新進行散列。由于無法使用native的Arrays.copy方法,速度就會很慢。
void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); } void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable, initHashSeedAsNeeded(newCapacity)); table = newTable; threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }List的代碼大家可自行查看,也是阻塞性的,擴容策略是原長度的1.5倍。
由于集合在代碼中使用的頻率非常高,如果你知道具體的數據項上限,那么不妨設置一個合理的初始化大小。比如,HashMap需要1024個元素,需要7次擴容,會影響應用的性能。
但是要注意,像HashMap這種有負載因子的集合(0.75),初始化大小=需要的個數/負載因子+1。如果你不是很清楚底層的結構,那就不妨保持默認。
3. 保持合適的對象粒度
曾經碰到一個并發量非常高的業務系統,需要頻繁使用到用戶的基本數據。由于用戶的基本信息,都是存放在另外一個服務中,所以每次用到用戶的基本信息,都需要有一次網絡交互。更加讓人無法接受的是,即使是只需要用戶的性別屬性,也需要把所有的用戶信息查詢,拉取一遍。
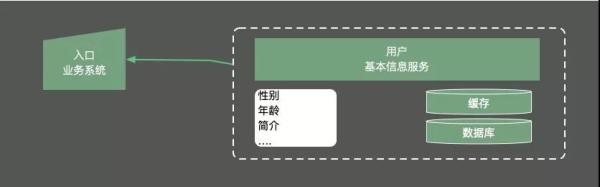
為了加快數據的查詢速度,對數據進行了初步的緩存,放入到了redis中。查詢性能有了大的改善,但每次還是要查詢很多冗余數據。
原始的redis key是這樣設計的。
type: string key: user_${userid} value: json這樣的設計有兩個問題:(1)查詢其中某個字段的值,需要把所有json數據查詢出來,并自行解析。(2)更新其中某個字段的值,需要更新整個json串,代價較高。
針對這種大粒度json信息,就可以采用打散的方式進行優化,使得每次更新和查詢,都有聚焦的目標。
接下來對redis中的數據進行了以下設計,采用hash結構而不是json結構:
type: hash key: user_${userid} value: {sex:f, id:1223, age:23}這樣,我們使用hget命令,或者hmget命令,就可以獲取到想要的數據,加快信息流轉的速度。
4. Bitmap把對象變小
還能再進一步優化么?比如,我們系統中就頻繁用到了用戶的性別數據,用來發放一些禮品,推薦一些異性的好友,定時循環用戶做一些清理動作等。或者,存放一些用戶的狀態信息,比如是否在線,是否簽到,最近是否發送信息等,統計一下活躍用戶等。
對是、否這兩個值的操作,就可以使用Bitmap這個結構進行壓縮。
如代碼所示,通過判斷int中的每一位,它可以保存32個boolean值!
int a= 0b0001_0001_1111_1101_1001_0001_1111_1101;
Bitmap就是使用Bit進行記錄的數據結構,里面存放的數據不是0就是1。Java中的相關結構類,就是java.util.BitSet。BitSet底層是使用long數組實現的,所以它的最小容量是64。
10億的boolean值,只需要128MB的內存。下面既是一個占用了256MB的用戶性別的判斷邏輯,可以涵蓋長度為10億的id。
static BitSet missSet = new BitSet(010_000_000_000); static BitSet sexSet = new BitSet(010_000_000_000); String getSex(int userId) { boolean notMiss = missSet.get(userId); if (!notMiss) { //lazy fetch String lazySex = dao.getSex(userId); missSet.set(userId, true); sexSet.set(userId, "female".equals(lazySex)); } return sexSet.get(userId) ? "female" : "male"; }這些數據,放在堆內內存中,還是過大了。幸運的是,Redis也支持Bitmap結構,如果內存有壓力,我們可以把這個結構放到redis中,判斷邏輯也是類似的。
這樣的問題還有很多:給出一個1GB內存的機器,提供60億int數據,如何快速判斷有哪些數據是重復的?大家可以類比思考一下。
Bitmap是一個比較底層的結構,在它之上還有一個叫做布隆過濾器的結構(Bloom Filter)。布隆過濾器可以判斷一個值不存在,或者可能存在。

相比較Bitmap,它多了一層hash算法。既然是hash算法,就會有沖突,所以有可能有多個值落在同一個bit上。
Guava中有一個BloomFilter的類,可以方便的實現相關功能。
5. 數據的冷熱分離
上面這種優化方式,本質上也是把大對象變成小對象的方式,在軟件設計中有很多類似的思路。像一篇新發布的文章,頻繁用到的是摘要數據,就不需要把整個文章內容都查詢出來;用戶的feed信息,也只需要保證可見信息的速度,而把完整信息存放在速度較慢的大型存儲里。
數據除了橫向的結構緯度,還有一個縱向的時間維度。對時間維度的優化,最有效的方式就是冷熱分離。
所謂熱數據,就是靠近用戶的,被頻繁使用的數據,而冷數據是那些訪問頻率非常低,年代非常久遠的數據。同一句復雜的SQL,運行在幾千萬的數據表上,和運行在幾百萬的數據表上,前者的效果肯定是很差的。所以,雖然你的系統剛開始上線時速度很快,但隨著時間的推移,數據量的增加,就會漸漸變得很慢。
冷熱分離是把數據分成兩份。如圖,一般都會保持一份全量數據,用來做一些耗時的統計操作。
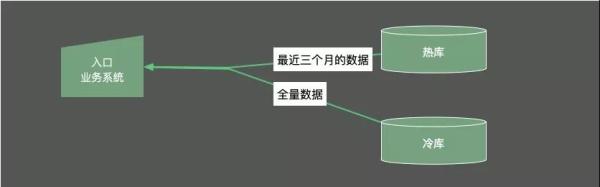
下面簡單介紹一下冷熱分離的三種方案。
(1)數據雙寫。把對冷熱庫的插入、更新、刪除操作,全部放在一個統一的事務里面。由于熱庫(比如MySQL)和冷庫(比如Hbase)的類型不同,這個事務大概率會是分布式事務。在項目初期,這種方式是可行的,但如果是改造一些遺留系統,分布式事務基本上是改不動的。我通常會把這種方案直接廢棄掉。
(2)寫入MQ分發。通過MQ的發布訂閱功能,在進行數據操作的時候,先不落庫,而是發送到MQ中。單獨啟動消費進程,將MQ中的數據分別落到冷庫、熱庫中。使用這種方式改造的業務,邏輯非常清晰,結構也比較優雅。像訂單這種結構比較清晰、對順序性要求較低的系統,就可以采用MQ分發的方式。但如果你的數據庫實體量非常的大,用這種方式就要考慮程序的復雜性了。
(3)使用binlog同步 針對于MySQL,就可以采用Binlog的方式進行同步。使用Canal組件,可持續獲取最新的Binlog數據,結合MQ,可以將數據同步到其他的數據源中。
End
關于大對象,我們可以再舉兩個例子。
像我們常用的數據庫索引,也是一種對數據的重新組織、加速。B+ tree可以有效的減少數據庫與磁盤交互的次數,它通過類似B+ tree的數據結構,將最常用的數據進行索引,存儲在有限的存儲空間中。
還有在RPC中常用的序列化。有的服務是采用的SOAP協議的WebService,它是基于XML的一種協議,內容大傳輸慢,效率低下。現在的Web服務中,大多數是使用json數據進行交互的,json的效率相比SOAP就更高一些。另外,大家應該都聽過google的protobuf,由于它是二進制協議,而且對數據進行了壓縮,性能是非常優越的。protobuf對數據壓縮后,大小只有json的1/10,xml的1/20,但是性能卻提高了5-100倍。protobuf的設計是值得借鑒的,它通過tag|leng|value三段對數據進行了非常緊湊的處理,解析和傳輸速度都特別快。
針對于大對象,我們有結構緯度的優化和時間維度的優化兩種方法。從結構緯度來說,通過把對象切分成合適的粒度,可以把操作集中在小數據結構上,減少時間處理成本;通過把對象進行壓縮、轉換,或者提取熱點數據,就可以避免大對象的存儲和傳輸成本。從時間緯度來說,就可以通過冷熱分離的手段,將常用的數據存放在高速設備中,減少數據處理的集合,加快處理速度。
到此,關于“如何使用高并發大對象處理”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





