溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Science發表的超贊聚類算法是什么呢,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
作者提出了一種很簡潔優美的聚類算法, 可以識別各種形狀的類簇, 并且其超參數很容易確定.
算法思想
該算法的假設是類簇的中心由一些局部密度比較低的點圍繞, 并且這些點距離其他有高局部密度的點的距離都比較大. 首先定義兩個值: 局部密度ρi以及到高局部密度點的距離δi:
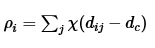
其中
dc是一個截斷距離, 是一個超參數. 所以ρi相當于距離點i的距離小于dc的點的個數. 由于該算法只對ρi的相對值敏感, 所以對dc的選擇比較魯棒, 一種推薦做法是選擇dc使得平均每個點的鄰居數為所有點的1%-2%. 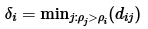
對于密度***的點, 設置 . 注意只有那些密度是局部或者全局***的點才會有遠大于正常的相鄰點間距.
. 注意只有那些密度是局部或者全局***的點才會有遠大于正常的相鄰點間距.
聚類過程
那些有著比較大的局部密度ρi和很大的δi的點被認為是類簇的中心. 局部密度較小但是δi較大的點是異常點.在確定了類簇中心之后, 所有其他點屬于距離其最近的類簇中心所代表的類簇. 圖例如下:

左圖是所有點在二維空間的分布, 右圖是以ρ為橫坐標, 以δ為縱坐標, 這種圖稱作決策圖(decision tree). 可以看到, 1和10兩個點的ρi和δi都比較大, 作為類簇的中心點. 26, 27, 28三個點的δi也比較大, 但是ρi較小, 所以是異常點.
聚類分析
在聚類分析中, 通常需要確定每個點劃分給某個類簇的可靠性. 在該算法中, 可以首先為每個類簇定義一個邊界區域(border region), 亦即劃分給該類簇但是距離其他類簇的點的距離小于dc的點. 然后為每個類簇找到其邊界區域的局部密度***的點, 令其局部密度為ρh. 該類簇中所有局部密度大于ρh的點被認為是類簇核心的一部分(亦即將該點劃分給該類簇的可靠性很大), 其余的點被認為是該類簇的光暈(halo), 亦即可以認為是噪音. 圖例如下
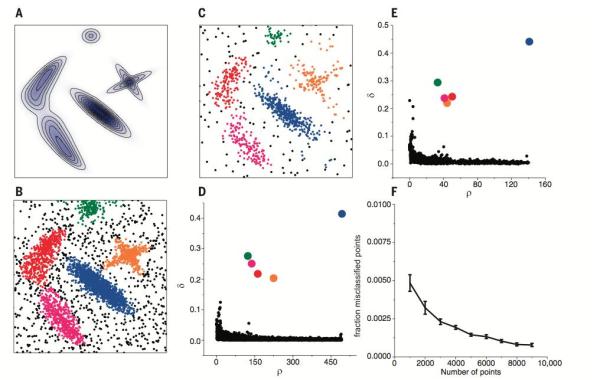
A圖為生成數據的概率分布, B, C二圖為分別從該分布中生成了4000, 1000個點. D, E分別是B, C兩組數據的決策圖(decision tree), 可以看到兩組數據都只有五個點有比較大的ρi和很大的δi. 這些點作為類簇的中心, 在確定了類簇的中心之后, 每個點被劃分到各個類簇(彩色點), 或者是劃分到類簇光暈(黑色點). F圖展示的是隨著抽樣點數量的增多, 聚類的錯誤率在逐漸下降, 說明該算法是魯棒的.
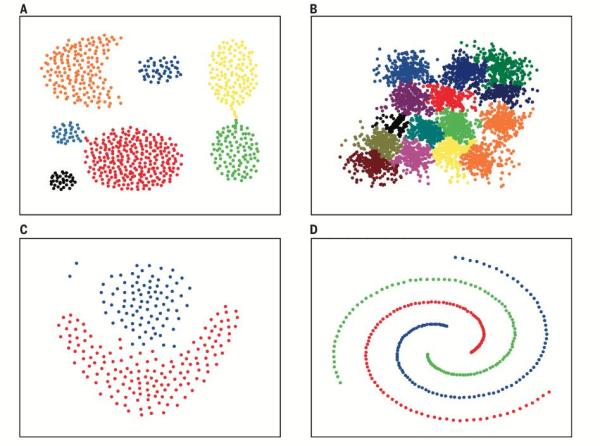
***展示一下該算法在各種數據分布上的聚類效果, 非常贊.
看完上述內容,你們對Science發表的超贊聚類算法是什么呢有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





