溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python數據可視化舉例分析”,在日常操作中,相信很多人在Python數據可視化舉例分析問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Python數據可視化舉例分析”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
01 網頁分析
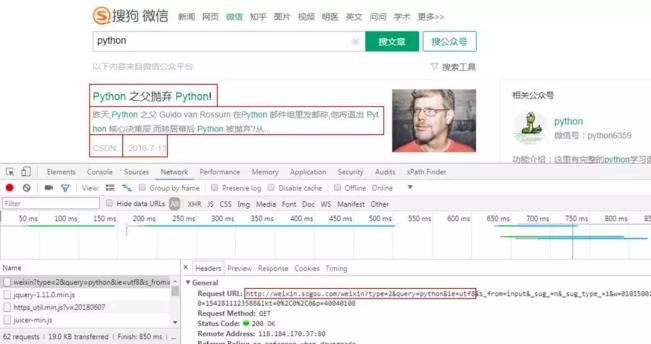
獲取微信公眾號文章信息,標題、開頭、公眾號、發布時間。
請求方式為GET,請求網址為紅框部分,后面的信息沒什么用。
02 反爬破解
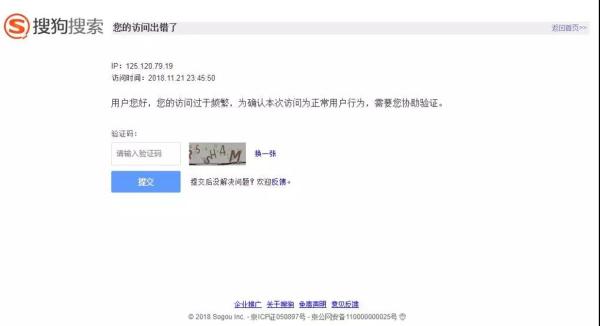
什么時候出現上圖這種情況呢?
兩種,一種同一個IP重復訪問頁面,另一種同一個Cookies重復訪問頁面。
兩個都有,掛的更快!完整爬取我只成功了一次...
因為我最開始就是先什么都不設置,然后就出現驗證碼頁面。然后用了代理IP,還是會跳轉驗證碼頁面,直到***改變Cookies,才成功爬取。
01 代理IP設置
def get_proxies(i): """ 獲取代理IP """ df = pd.read_csv('sg_effective_ip.csv', header=None, names=["proxy_type", "proxy_url"]) proxy_type = ["{}".format(i) for i in np.array(df['proxy_type'])] proxy_url = ["{}".format(i) for i in np.array(df['proxy_url'])] proxies = {proxy_type[i]: proxy_url[i]} return proxies代理的獲取以及使用這里就不贅述了,前面的文章有提到,有興趣的小伙伴可以自行去看看。
經過我兩天的實踐,免費IP確實沒什么用,兩下子就把我真實IP揪出來了。
02 Cookies設置
def get_cookies_snuid(): """ 獲取SNUID值 """ time.sleep(float(random.randint(2, 5))) url = "http://weixin.sogou.com/weixin?type=2&s_from=input&query=python&ie=utf8&_sug_=n&_sug_type_=" headers = {"Cookie": "ABTEST=你的參數;IPLOC=CN3301;SUID=你的參數;SUIR=你的參數"} # HEAD請求,請求資源的首部 response = requests.head(url, headers=headers).headers result = re.findall('SNUID=(.*?); expires', response['Set-Cookie']) SNUID = result[0] return SNUID總的來說,Cookies的設置是整個反爬中最重要的,而其中的關鍵便是動態改變SNUID值。
這里就不詳細說其中緣由,畢竟我也是在網上看大神的帖子才領悟到的,而且領悟的還很淺。
成功爬取100頁就只有一次,75頁,50頁,甚至到***一爬就掛的情況都出現了...
我可不想身陷「爬-反爬-反反爬」的泥潭之中,爬蟲之后的事情才是我的真正目的,比如數據分析,數據可視化。
所以干票大的趕緊溜,只能膜拜搜狗工程師。
03 數據獲取
1 構造請求頭
head = """ Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 Accept-Encoding:gzip, deflate Accept-Language:zh-CN,zh;q=0.9 Connection:keep-alive Host:weixin.sogou.com Referer:'http://weixin.sogou.com/', Upgrade-Insecure-Requests:1 User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 """ # 不包含SNUID值 cookie = '你的Cookies' def str_to_dict(header): """ 構造請求頭,可以在不同函數里構造不同的請求頭 """ header_dict = {} header = header.split('\n') for h in header: h = h.strip() if h: k, v = h.split(':', 1) header_dict[k] = v.strip() return header_dict2 獲取網頁信息
def get_message(): """ 獲取網頁相關信息 """ failed_list = [] for i in range(1, 101): print('第' + str(i) + '頁') print(float(random.randint(15, 20))) # 設置延時,這里是度娘查到的,說要設置15s延遲以上,不會被封 time.sleep(float(random.randint(15, 20))) # 每10頁換一次SNUID值 if (i-1) % 10 == 0: value = get_cookies_snuid() snuid = 'SNUID=' + value + ';' # 設置Cookies cookies = cookie + snuid url = 'http://weixin.sogou.com/weixin?query=python&type=2&page=' + str(i) + '&ie=utf8' host = cookies + '\n' header = head + host headers = str_to_dict(header) # 設置代理IP proxies = get_proxies(i) try: response = requests.get(url=url, headers=headers, proxies=proxies) html = response.text soup = BeautifulSoup(html, 'html.parser') data = soup.find_all('ul', {'class': 'news-list'}) lis = data[0].find_all('li') for j in (range(len(lis))): h4 = lis[j].find_all('h4') #print(h4[0].get_text().replace('\n', '')) title = h4[0].get_text().replace('\n', '').replace(',', ',') p = lis[j].find_all('p') #print(p[0].get_text()) article = p[0].get_text().replace(',', ',') a = lis[j].find_all('a', {'class': 'account'}) #print(a[0].get_text()) name = a[0].get_text() span = lis[j].find_all('span', {'class': 's2'}) cmp = re.findall("\d{10}", span[0].get_text()) #print(time.strftime("%Y-%m-%d", time.localtime(int(cmp[0]))) + '\n') date = time.strftime("%Y-%m-%d", time.localtime(int(cmp[0]))) with open('sg_articles.csv', 'a+', encoding='utf-8-sig') as f: f.write(title + ',' + article + ',' + name + ',' + date + '\n') print('第' + str(i) + '頁成功') except Exception as e: print('第' + str(i) + '頁失敗') failed_list.append(i) continue # 獲取失敗頁碼 print(failed_list) def main(): get_message() if __name__ == '__main__': main()***成功獲取數據。


04 數據可視化
1 微信文章發布數量***0
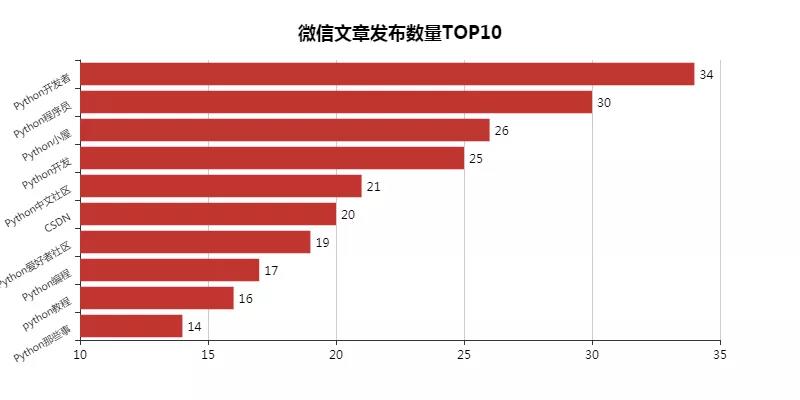
這里對搜索過來的微信文章進行排序,發現了這十位Python大佬。
這里其實特想知道他們是團隊運營,還是個人運營。不過不管了,先關注去。
這個結果可能也與我用Python這個關鍵詞去搜索有關,一看公眾號名字都是帶有Python的(CSDN例外)。
from pyecharts import Bar import pandas as pd df = pd.read_csv('sg_articles.csv', header=None, names=["title", "article", "name", "date"]) list1 = [] for j in df['date']: # 獲取文章發布年份 time = j.split('-')[0] list1.append(time) df['year'] = list1 # 選取發布時間為2018年的文章,并對其統計 df = df.loc[df['year'] == '2018'] place_message = df.groupby(['name']) place_com = place_message['name'].agg(['count']) place_com.reset_index(inplace=True) place_com_last = place_com.sort_index() dom = place_com_last.sort_values('count', ascending=False)[0:10] attr = dom['name'] v1 = dom['count'] bar = Bar("微信文章發布數量***0", title_pos='center', title_top='18', width=800, height=400) bar.add("", attr, v1, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0, is_label_show=True, is_legend_show=False, label_pos='right', is_yaxis_inverse=True, is_splitline_show=False) bar.render("微信文章發布數量***0.html")2 微信文章發布時間分布
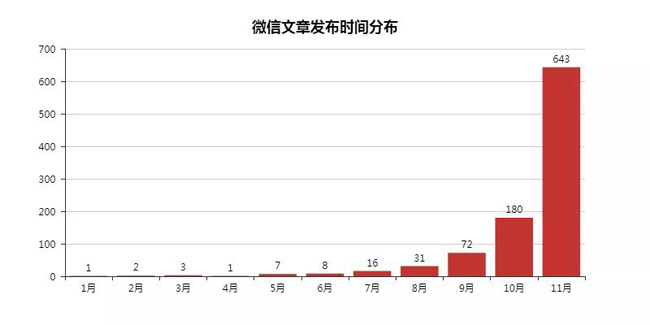
因為這里發現搜索到的文章會有2018年以前的,這里予以刪除,并且驗證剩下文章的發布時間。
畢竟信息講究時效性,如果我搜索獲取的都是老掉牙的信息,就沒什么意思了,更何況還是在一直在變化的互聯網行業。
import numpy as np import pandas as pd from pyecharts import Bar df = pd.read_csv('sg_articles.csv', header=None, names=["title", "article", "name", "date"]) list1 = [] list2 = [] for j in df['date']: # 獲取文章發布年份及月份 time_1 = j.split('-')[0] time_2 = j.split('-')[1] list1.append(time_1) list2.append(time_2) df['year'] = list1 df['month'] = list2 # 選取發布時間為2018年的文章,并對其進行月份統計 df = df.loc[df['year'] == '2018'] month_message = df.groupby(['month']) month_com = month_message['month'].agg(['count']) month_com.reset_index(inplace=True) month_com_last = month_com.sort_index() attr = ["{}".format(str(i) + '月') for i in range(1, 12)] v1 = np.array(month_com_last['count']) v1 = ["{}".format(int(i)) for i in v1] bar = Bar("微信文章發布時間分布", title_pos='center', title_top='18', width=800, height=400) bar.add("", attr, v1, is_stack=True, is_label_show=True) bar.render("微信文章發布時間分布.html")3 標題、文章開頭詞云
from wordcloud import WordCloud, ImageColorGenerator import matplotlib.pyplot as plt import pandas as pd import jieba df = pd.read_csv('sg_articles.csv', header=None, names=["title", "article", "name", "date"]) text = '' # for line in df['article'].astype(str):(前文詞云代碼) for line in df['title']: text += ' '.join(jieba.cut(line, cut_all=False)) backgroud_Image = plt.imread('python_logo.jpg') wc = WordCloud( background_color='white', mask=backgroud_Image, font_path='C:\Windows\Fonts\STZHONGS.TTF', max_words=2000, max_font_size=150, random_state=30 ) wc.generate_from_text(text) img_colors = ImageColorGenerator(backgroud_Image) wc.recolor(color_func=img_colors) plt.imshow(wc) plt.axis('off') # wc.to_file("文章.jpg")(前文詞云代碼) wc.to_file("標題.jpg") print('生成詞云成功!')到此,關于“Python數據可視化舉例分析”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





