溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“如何掌握阻塞隊列”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“如何掌握阻塞隊列”吧!
什么是隊列
隊列是一種 先進先出的特殊線性表,簡稱 FIFO。特殊之處在于只允許在一端插入,在另一端刪除
進行插入操作的端稱為隊尾,進行刪除操作的端稱為隊頭。隊列中沒有元素時,稱為空隊列
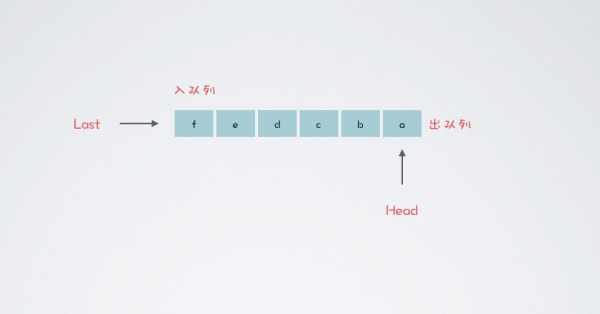
隊列在程序設計中使用非常的多,包括一些中間件底層數據結構就是隊列(基礎內容沒有過多講解)
什么是阻塞隊列
隊列就隊列唄,阻塞隊列又是什么鬼
阻塞隊列是在隊列的基礎上額外添加兩個操作的隊列,分別是:
支持阻塞的插入方法:隊列容量滿時,插入元素線程會被阻塞,直到隊列有多余容量為止
支持阻塞的移除方法:當隊列中無元素時,移除元素的線程會被阻塞,直到隊列有元素可被移除
文章以 LinkedBlockingQueue 為例,講述隊列之間實現的不同點,為方便小伙伴閱讀,LinkedBlockingQueue 取別名 LBQ
因為是源碼解析文章,建議小伙伴們在 PC 端觀看。當然,如果屏足夠大當我沒說~
阻塞隊列繼承關系
阻塞隊列是一個抽象的叫法,阻塞隊列底層數據結構 可以是數組,可以是單向鏈表,亦或者是雙向鏈表...
LBQ 是一個以 單向鏈表組成的隊列,下圖為 LBQ 上下繼承關系圖
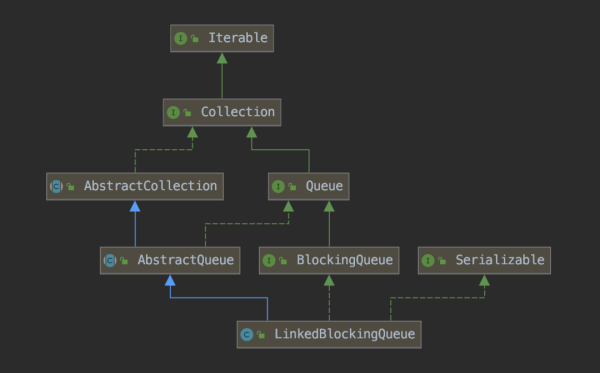
從圖中得知,LBQ 實現了 BlockingQueue 接口,BlockingQueue 實現了 Queue 接口
Queue 接口分析
我們以自上而下的方式,先分析一波 Queue 接口里都定義了哪些方法
// 如果隊列容量允許,立即將元素插入隊列,成功后返回 // ?如果隊列容量已滿,則拋出異常 boolean add(E e); // 如果隊列容量允許,立即將元素插入隊列,成功后返回 // ?如果隊列容量已滿,則返回 false // 當使用有界隊列時,offer 比 add 方法更何時 boolean offer(E e); // 檢索并刪除隊列的頭節點,返回值為刪除的隊列頭節點 // ?如果隊列為空則拋出異常 E remove(); // 檢索并刪除隊列的頭節點,返回值為刪除的隊列頭節點 // ?如果隊列為空則返回 null E poll(); // 檢查但不刪除隊列頭節點 // ?如果隊列為空則拋出異常 E element(); // 檢查但不刪除隊列頭節點 // ?如果隊列為空則返回 null E peek();
總結一下 Queue 接口的方法,分為三個大類:
新增元素到隊列容器中:add、offer
從隊列容器中移除元素:remove、poll
查詢隊列頭節點是否為空:element、peek
從接口 API 的程序健壯性考慮,可以分為兩大類:
健壯 API:offer、poll、peek
非健壯 API:add、remove、element
接口 API 并無健壯可言,這里說的健壯界限指得是,使用了非健壯性的 API 接口,程序會出錯的幾率大了點,所以我們 更應該關注的是如何捕獲可能出現的異常,以及對應異常處理
BlockingQueue 接口分析
BlockingQueue 接口繼承自 Queue 接口,所以有些語義相同的 API 接口就沒有放上來解讀
// 將指定元素插入隊列,如果隊列已滿,等待直到有空間可用;通過 throws 異常得知,可在等待時打斷 // ?相對于 Queue 接口而言,是一個全新的方法 void put(E e) throws InterruptedException; // 將指定元素插入隊列,如果隊列已滿,在等待指定的時間內等待騰出空間;通過 throws 異常得知,可在等待時打斷 // ?相當于是 offer(E e) 的擴展方法 boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException; // 檢索并除去此隊列的頭節點,如有必要,等待直到元素可用;通過 throws 異常得知,可在等待時打斷 E take() throws InterruptedException; // 檢索并刪除此隊列的頭,如果有必要使元素可用,則等待指定的等待時間;通過 throws 異常得知,可在等待時打斷 // ?相當于是 poll() 的擴展方法 E poll(long timeout, TimeUnit unit) throws InterruptedException; // 返回隊列剩余容量,如果為無界隊列,返回 Integer.MAX_VALUE int remainingCapacity(); // 如果此隊列包含指定的元素,則返回 true public boolean contains(Object o); // 從此隊列中刪除所有可用元素,并將它們添加到給定的集合中 int drainTo(Collection<? super E> c); // 從此隊列中最多移除給定數量的可用元素,并將它們添加到給定的集合中 int drainTo(Collection<? super E> c, int maxElements);
可以看到 BlockingQueue 接口中個性化的方法還是挺多的。本文的豬腳 LBQ 就是實現自 BlockingQueue 接口
源碼解析
變量分析LBQ 為了保證并發添加、移除等操作,使用了 JUC 包下的 ReentrantLock、Condition 控制
// take, poll 等移除操作需要持有的鎖 private final ReentrantLock takeLock = new ReentrantLock(); // 當隊列沒有數據時,刪除元素線程被掛起 private final Condition notEmpty = takeLock.newCondition(); // put, offer 等新增操作需要持有的鎖 private final ReentrantLock putLock = new ReentrantLock(); // 當隊列為空時,添加元素線程被掛起 private final Condition notFull = putLock.newCondition();
ArrayBlockingQueue(ABQ)內部元素個數字段為什么使用的是 int 類型的 count 變量?不擔心并發么
鴻蒙官方戰略合作共建——HarmonyOS技術社區
因為 ABQ 內部使用的一把鎖控制入隊、出隊操作,同一時刻只會有單線程執行 count 變量修改
LBQ 使用的兩把鎖,所以會出現兩個線程同時修改 count 數值,如果像 ABQ 使用 int 類型,兩個流程同時執行修改 count 個數,會造成數據不準確,所以需要使用并發原子類修飾
如果不太明白為什么要用原子類統計數量,猛戳這里
接下來從結構體入手,知道它是由什么元素組成,每個元素是做啥使的。如果數據結構還不錯的小伙伴,應該可以猜出來
// 綁定的容量,如果無界,則為 Integer.MAX_VALUE private final int capacity; // 當前隊列中元素個數 private final AtomicInteger count = new AtomicInteger(); // 當前隊列的頭節點 transient Node<E> head; // 當前隊列的尾節點 private transient Node<E> last;
看到 head 和 last 元素,是不是對 LBQ 就有個大致的雛形了,這個時候還差一個結構體 Node
static class Node<E> { // 節點存儲的元素 E item; // 當前節點的后繼節點 LinkedBlockingQueue.Node<E> next; Node(E x) { item = x; } }構造器分析這里畫一張圖來理解下 LBQ 默認構造方法是如何初始化隊列的
public LinkedBlockingQueue() { this(Integer.MAX_VALUE); } public LinkedBlockingQueue(int capacity) { if (capacity <= 0) throw new IllegalArgumentException(); this.capacity = capacity; last = head = new Node<E>(null); }可以看出,默認構造方法會將容量設置為 Integer.MAX_VALUE,也就是大家常說的無界隊列
內部其實調用的是重載的有參構造,方法內部設置了容量大小,以及初始化了 item 為空的 Node 節點,把 head last 兩節點進行一個關聯
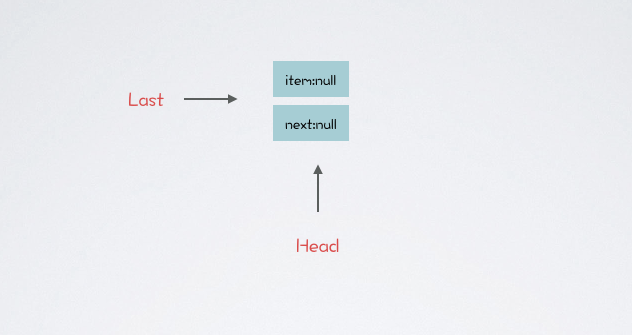
初始化的隊列 head last 節點指向的 Node 中 item、next 都為空,此時添加一條記錄,隊列會發生什么樣的變化
節點入隊
需要添加的元素會被封裝為 Node 添加到隊列中, put 入隊方法語義,如果隊列元素已滿,阻塞當前插入線程,直到隊列中有空缺位置被喚醒
public void put(E e) throws InterruptedException { if (e == null) throw new NullPointerException(); int c = -1; Node<E> node = new Node<E>(e); // 將需要添加的數據封裝為 Node final ReentrantLock putLock = this.putLock; // 獲取添加操作的鎖 final AtomicInteger count = this.count; // 獲取隊列實際元素數量 putLock.lockInterruptibly(); // 運行可被中斷加鎖 API try { while (count.get() == capacity) { // 如果隊列元素數量 == 隊列最大值,則將線程放入條件隊列阻塞 notFull.await(); } enqueue(node); // 執行入隊流程 c = count.getAndIncrement(); // 獲取值并且自增,舉例:count = 0,執行后結果值 count+1 = 2,返回 0 if (c + 1 < capacity) // 如果自增過的隊列元素 +1 小于隊列容器最大數量,喚醒一條被阻塞在插入等待隊列的線程 notFull.signal(); } finally { putLock.unlock(); // 解鎖操作 } if (c == 0) // 當隊列中有一條數據,則喚醒消費組線程進行消費 signalNotEmpty(); }入隊方法整體流程比較清晰,做了以下幾件事:
隊列已滿,則將當前線程阻塞
隊列中如果有空缺位置,將數據封裝的 Node 執行入隊操作
如果 Node 執行入隊操作后,隊列還有空余位置,則喚醒等待隊列中的添加線程
如果數據入隊前隊列沒有元素,入隊成功后喚醒消費阻塞隊列中的線程
繼續看一下入隊方法 LBQ#enqueue 都做了什么操作
private void enqueue(Node<E> node) { last = last.next = node; }代碼比較簡單,先把 node 賦值為當前 last 節點的 next 屬性,然后再把 last 節點指向 node,就完成了節點入隊操作
假設 LBQ 的范型是 String 字符串,首先插入元素 a,隊列如下圖所示:
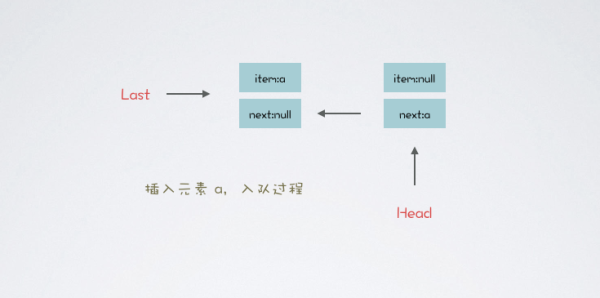
什么?一條數據不過癮?沒有什么是再來一條解決不了的,元素 b 入隊如下:
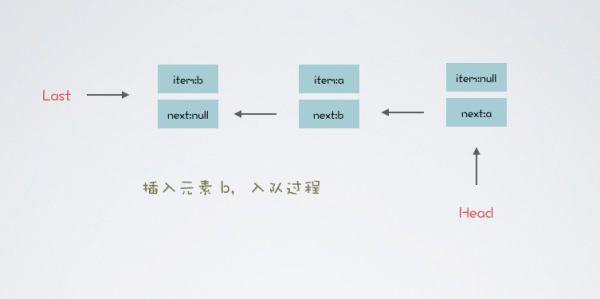
隊列入隊如上圖所示,head 中 item 永為空,last 中 next 永為空
LBQ#offer 也是入隊方法,不同的是:如果隊列元素已滿,則直接返回 false,不阻塞線程
節點出隊
LBQ#take 出隊方法,如果隊列中元素為空,阻塞當前出隊線程,直到隊列中有元素為止
public E take() throws InterruptedException { E x; int c = -1; final AtomicInteger count = this.count; // 獲取當前隊列實際元素個數 final ReentrantLock takeLock = this.takeLtakeLocock; // 獲取 takeLock 鎖實例 takeLock.lockInterruptibly(); // 獲取 takeLock 鎖,獲取不到阻塞過程中,可被中斷 try { while (count.get() == 0) { // 如果當前隊列元素 == 0,當前獲取節點線程加入等待隊列 notEmpty.await(); } x = dequeue(); // 當前隊列元素 > 0,執行頭節點出隊操作 c = count.getAndDecrement(); // 獲取當前隊列元素個數,并將數量 - 1 if (c > 1) // 當隊列中還有還有元素時,喚醒下一個消費線程進行消費 notEmpty.signal(); } finally { takeLock.unlock(); // 釋放鎖 } if (c == capacity) // 移除元素之前隊列是滿的,喚醒生產者線程添加元素 signalNotFull(); return x; // 返回頭節點 }出隊操作整體流程清晰明了,和入隊操作執行流程相似
隊列已滿,則將當前出隊線程阻塞
隊列中如果有元素可消費,執行節點出隊操作
如果節點出隊后,隊列中還有可出隊元素,則喚醒等待隊列中的出隊線程
如果移除元素之前隊列是滿的,喚醒生產者線程添加元素
LBQ#dequeue 出隊操作相對于入隊操作稍顯復雜一些
private E dequeue() { Node<E> h = head; // 獲取隊列頭節點 Node<E> first = h.next; // 獲取頭節點的后繼節點 h.next = h; // help GC head = first; // 相當于把頭節點的后繼節點,設置為新的頭節點 E x = first.item; // 獲取到新的頭節點 item first.item = null; // 因為頭節點 item 為空,所以 item 賦值為 null return x; }出隊流程中,會將原頭節點自己指向自己本身,這么做是為了幫助 GC 回收當前節點,接著將原 head 的 next 節點設置為新的 head,下圖為一個完整的出隊流程
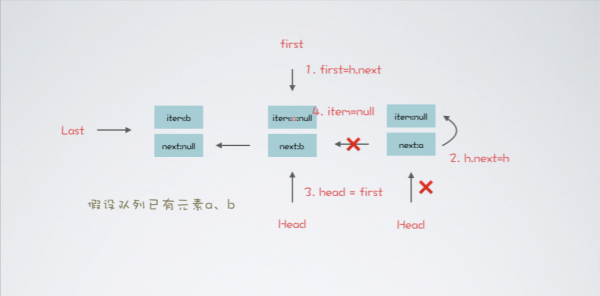
出隊流程圖如上,流程中沒有特別注意的點。另外一個 LBQ#poll 出隊方法,如果隊列中元素為空,返回 null,不會像 take 一樣阻塞
節點查詢
因為 element 查找方法在父類 AbstractQueue 里實現的,LBQ 里只對 peek 方法進行了實現,節點查詢就用 peek 做代表了
peek 和 element 都是獲取隊列頭節點數據,兩者的區別是,前者如果隊列為空返回 null,后者拋出相關異常
public E peek() { if (count.get() == 0) // 隊列為空返回 null return null; final ReentrantLock takeLock = this.takeLock; takeLock.lock(); // 獲取鎖 try { LinkedBlockingQueue.Node<E> first = head.next; // 獲取頭節點的 next 后繼節點 if (first == null) // 如果后繼節點為空,返回 null,否則返回后繼節點的 item return null; else return first.item; } finally { takeLock.unlock(); // 解鎖 } }看到這里,能夠得到結論,雖然 head 節點 item 永遠為 null,但是 peek 方法獲取的是 head.next 節點 item
節點刪除
刪除操作需要獲得兩把鎖,所以關于獲取節點、節點出隊、節點入隊等操作都會被阻塞
public boolean remove(Object o) { if (o == null) return false; fullyLock(); // 獲取兩把鎖 try { // 從頭節點開始,循環遍歷隊列 for (Node<E> trail = head, p = trail.next; p != null; trail = p, p = p.next) { if (o.equals(p.item)) { // item == o 執行刪除操作 unlink(p, trail); // 刪除操作 return true; } } return false; } finally { fullyUnlock(); // 釋放兩把鎖 } }鏈表刪除操作,一般而言都是循環逐條遍歷,而這種的 遍歷時間復雜度為 O(n),最壞情況就是遍歷了鏈表全部節點
看一下 LBQ#remove 中 unlink 是如何取消節點關聯的
void unlink(Node<E> p, Node<E> trail) { p.item = null; // 以第一次遍歷而言,trail 是頭節點,p 為頭節點的后繼節點 trail.next = p.next; // 把頭節點的后繼指針,設置為 p 節點的后繼指針 if (last == p) // 如果 p == last 設置 last == trail last = trail; // 如果刪除元素前隊列是滿的,刪除后就有了空余位置,喚醒生產線程 if (count.getAndDecrement() == capacity) notFull.signal(); }remove 方法和 take 方法是有相似之處,如果 remove 方法的元素是頭節點,效果和 take 一致,頭節點元素出隊
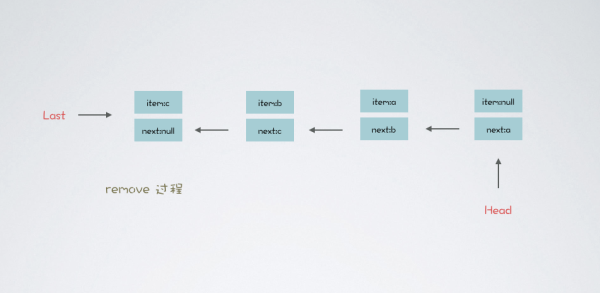
為了更好的理解,我們刪除中間元素。畫兩張圖理解下其中原委,代碼如下:
public static void main(String[] args) { BlockingQueue<String> blockingQueue = new LinkedBlockingQueue(); blockingQueue.offer("a"); blockingQueue.offer("b"); blockingQueue.offer("c"); // 刪除隊列中間元素 blockingQueue.remove("b"); }執行完上述代碼中三個 offer 操作,隊列結構圖如下:
執行刪除元素 b 操作后隊列結構如下圖:
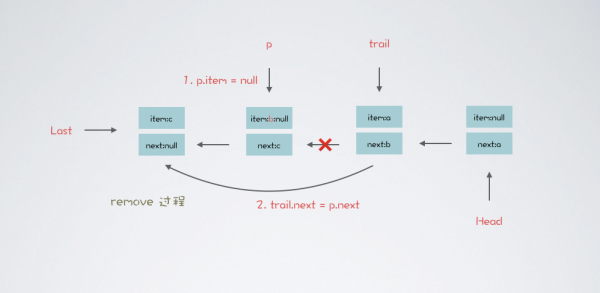
如果 p 節點就是 last 尾節點,則把 p 的前驅節點設置為新的尾節點。刪除操作大致如此
應用場景
上文說了阻塞隊列被大量業務場景所應用,這里例舉兩個實際工作中的例子幫助大家理解
生產者-消費者模式
生產者-消費者模式是一個典型的多線程并發寫作模式,生產者和消費者中間需要一個容器來解決強耦合關系,生產者向容器放數據,消費者消費容器數據
生產者-消費者實現有多種方式
Object 類中的 wait、notify、notifyAll
Lock 中 Condition 的 await、signal、signalAll
BlockingQueue
阻塞隊列實現生產者-消費者模型代碼如下:
@Slf4j public class BlockingQueueTest { private static final int MAX_NUM = 10; private static final BlockingQueue<String> QUEUE = new LinkedBlockingQueue<>(MAX_NUM); public void produce(String str) { try { QUEUE.put(str); log.info(" ??? 隊列放入元素 :: {}, 隊列元素數量 :: {}", str, QUEUE.size()); } catch (InterruptedException ie) { // ignore } } public String consume() { String str = null; try { str = QUEUE.take(); log.info(" ??? 隊列移出元素 :: {}, 隊列元素數量 :: {}", str, QUEUE.size()); } catch (InterruptedException ie) { // ignore } return str; } public static void main(String[] args) { BlockingQueueTest queueTest = new BlockingQueueTest(); for (int i = 0; i < 5; i++) { int finalI = i; new Thread(() -> { String str = "元素-"; while (true) { queueTest.produce(str + finalI); } }).start(); } for (int i = 0; i < 5; i++) { new Thread(() -> { while (true) { queueTest.consume(); } }).start(); } } }線程池應用
阻塞隊列在線程池中的具體應用屬于是生產者-消費者的實際場景
線程池在 Java 應用里的重要性不言而喻,這里簡要說下線程池的運行原理
線程池線程數量小于核心線程數執行新增核心線程操作
線程池線程數量大于或等于核心線程數時,將任務存放阻塞隊列
滿足線程池中線程數大于或等于核心線程數并且阻塞隊列已滿, 線程池創建非核心線程
重點在于第二點,當線程池核心線程都在運行任務時,會把任務存放阻塞隊列中。線程池源碼如下:
if (isRunning(c) && workQueue.offer(command)) {}看到使用的 offer 方法,通過上面講述,如果阻塞隊列已滿返回 false。那何時進行消費隊列中的元素呢。涉及線程池中線程執行過程原理,這里簡單說明
線程池內線程執行任務有兩種方式,一種是創建核心線程時 自帶 的任務,另一種就是從阻塞隊列獲取
當核心線程執行一次任務后,其實和非核心線程就沒什么區別了
線程池獲取阻塞隊列任務使用了兩種 API,分別是 poll 和 take
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
Q:為啥要用兩個 API?一個不香么?
A:take 是為了要維護線程池內核心線程的重要手段,如果獲取不到任務,線程被掛起,等待下一次任務添加
至于帶時間的 pool 則是為了回收非核心線程準備的
結言LBQ 阻塞隊列到這里就講解完成了,總結下文章所講述的 LBQ 基本特征
LBQ 是基于鏈表實現的阻塞隊列,可以進行讀寫并發執行
LBQ 隊列容量可以自己設置,如果不設置默認 Integer 最大值,也可以稱為無界隊列
感謝各位的閱讀,以上就是“如何掌握阻塞隊列”的內容了,經過本文的學習后,相信大家對如何掌握阻塞隊列這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





