溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“說Python內置函數并不是萬能的原因有哪些”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“說Python內置函數并不是萬能的原因有哪些”吧!
1、內置函數的查找優先級最低
內置函數的名稱并不屬于關鍵字,它們是可以被重新賦值的。
比如下面這個例子:
# 正常調用內置函數 list(range(3)) # 結果:[0, 1, 2] # 定義任意函數,然后賦值給 list def test(n): print("Hello World!") list = test list(range(3)) # 結果:Hello World!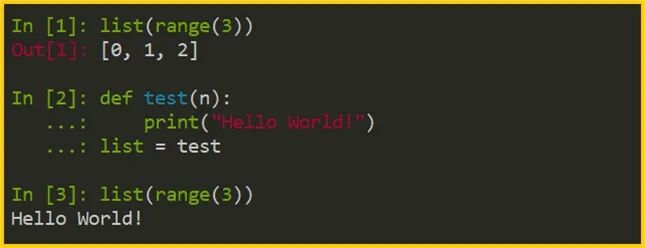
在這個例子中,我們將自定義的 test 賦值給了 list,程序并沒有報錯。這個例子甚至還可以改成直接定義新的同名函數,即"def list(): …"。
這說明了 list 并不是 Python 限定的關鍵字/保留字。
查看官方文檔,可以發現 Python3.9 有35個關鍵字,明細如下:

如果我們將上例的 test 賦值給任意一個關鍵字,例如"pass=test",就會報錯:SyntaxError: invalid syntax。
由此,我們可以從這個角度看出內置函數并不是萬能的:它們的名稱并不像關鍵字那般穩固不變,雖然它們處在系統內置作用域里,但是卻可以被用戶局部作用域的對象所輕松攔截掉!
因為解釋器查找名稱的順序是“局部作用域->全局作用域->內置作用域”,因此內置函數其實是處在最低優先級。
對于新手來說,這有一定的可能會發生意想不到的情況(內置函數有 69 個,要全記住是有難度的)。
那么,為什么 Python 不把所有內置函數的名稱都設為不可復寫的關鍵字呢?
一方面原因是它想控制關鍵字的數量,另一方面可能是想留給用戶更多的自由。內置函數只是解釋器的推薦實現而已,開發者可以根據需要,實現出與內置函數同名的函數。
不過,這樣的場景極少,而且開發者一般會定義成不同名的函數,以 Python 標準庫為例,ast模塊有 literal_eval() 函數(對標 eval() 內置函數)、pprint 模塊有 pprint() 函數(對標 print() 內置函數)、以及itertools模塊有 zip_longest() 函數(對標 zip() 內置函數)……
2、內置函數可能不是最快的
由于內置函數的名稱并非保留的關鍵字,以及它處于名稱查找的末位順序,所以內置函數有可能不是最快的。
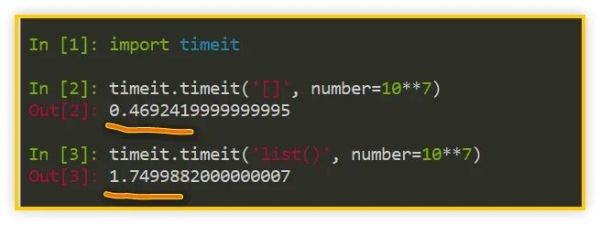
上篇文章展示了 [] 比 list() 快 2~3 倍的事實,其實這還可以推廣到 str()、tuple()、set()、dict() 等等內置類型中,都是字面量用法稍稍快于內置類型用法。
對于這些內置類型,當我們調用 xxx() 時,可以簡單理解成正在做類的實例化。在面向對象語言中,類先實例化再使用,這是再正常不過的。
但是,這樣的做法有時也顯得繁瑣。為了方便使用,Python 給一些常用的內置類型提供了字面量表示法,也就是""、[]、()、{} 等等,表示字符串、列表、元組和字典等數據類型。

文檔出處:https://docs.python.org/3/reference/lexical_analysis.html#delimiters
一般而言,所有編程語言都必須有一些字面量表示,但基本都局限在數字類型、字符串、布爾類型以及 null 之類的基礎類型。
Python 中還增加了幾種數據結構類型的字面量,所以是更為方便的,同時這也解釋了為什么內置函數可能不是最快的。
一般而言,同樣的完備功能,內置函數總是比我們自定義的函數要快,因為解釋器可以做一些底層的優化,例如 len() 內置函數肯定比用戶定義的 x.len() 函數快。
有些人據此形成了“內置函數總是更快”的認識誤區。
解釋器內置函數相對于用戶定義函數,前者接近于走后門;而字面量表示法相對于內置函數,前者是在走更快的后門。
也就是說,在有字面量表示法的情況下,某些內置函數/內置類型并不是最快的!
感謝各位的閱讀,以上就是“說Python內置函數并不是萬能的原因有哪些”的內容了,經過本文的學習后,相信大家對說Python內置函數并不是萬能的原因有哪些這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





