溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Python 中怎么利用Pandas處理復雜的Excel數據,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
問題緣起
pandas read_excel函數在讀取Excel工作表方面做得很好。但是,如果數據不是從頭開始,不是從單元格A1開始的連續表格,則結果會不是很好。比如下面一個銷售表,使用read_excel讀取:
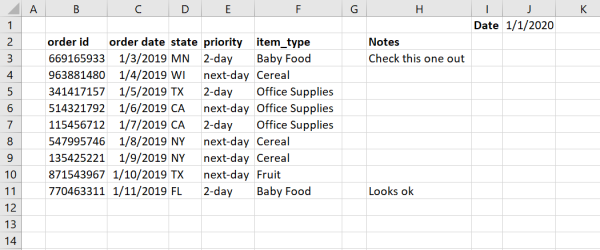
讀取的結果如下所示:
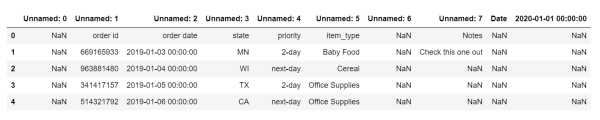
結果中標題表頭變成了Unnamed,而且還會額外增加很多職位NaN列,字段為空的列的值也會被轉換為NaN,這顯然不是我們所期望的。
header和usecols參數
對這樣的非標準格式的表格,我們可以使用read_excel()的header和usecols參數來控制選擇的需要讀取的列。
import pandas as pd from pathlib import Path src_file = 'sales.xlsx'
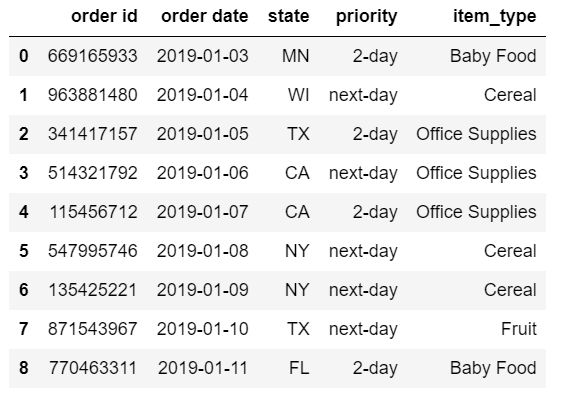
結果的DataFrame包含了我們期望的數據。
代碼中使用header和usecols參數設定了用于顯示標題的列和需要讀取的字段:
header參數為一個整數,從0開始索引,其為選擇的行,比如1表示Excel中的第2行。
usecols參數設定選擇的Excel列范圍范圍(A-…),例如,B:F表示讀取B到F列。
在某些情況下,可能希望將列定義為數字列表。比如,可以定義整數列數:
df = pd.read_excel(src_file, header=1, usecols=[1,2,3,4,5])
這對對大型數據集(例如,每3列或僅偶數列)要遵循一定的數字模式,則這個參數方法會很有用。
usecols還可以設定從列名列表讀取。比如上面的例子也可以這樣寫:
df = pd.read_excel( src_file, header=1, usecols=['item_type', 'order id', 'order date', 'state', 'priority'])
列順序支持自由選擇,這種命名列列表的方式實際中很有用。
usecols支持一個回調函數column_check,可通過該函數對數據進行處理。
下面是一個簡單的示例:
def column_check(x): if 'unnamed' in x.lower(): return False if 'priority' in x.lower(): return False if 'order' in x.lower(): return True return True
df = pd.read_excel(src_file, header=1, usecols=column_check)
column_check按名稱解析每列,每列通過定義True或False,來選擇是否讀取。
usecols也可以使用lambda表達式。下面的示例中定義的需要顯示的字段列表。為了進行比較,通過將名稱轉換為小寫來規范化。
cols_to_use = ['item_type', 'order id', 'order date', 'state', 'priority'] df = pd.read_excel(src_file, header=1, usecols=lambda x: x.lower() in cols_to_use)
回調函數為我們提供了許多靈活性,可以處理Excel文件的實際混亂情況。
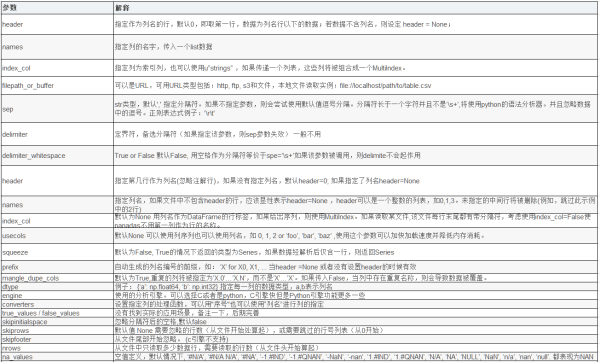
關于read_exce函數更多參數可以查看官方文檔,下面是一個總結表格:
結合openpyxl
在某些情況下,數據甚至可能在Excel中變得更加復雜。在下面示例中,我們有一個ship_cost要讀取的表。如果必須使用這樣的文件,那么只用pandas函數和選項也很難做到。在這種情況下,可以直接使用openpyxl解析文件并將數據轉換為pandas DataFrame。比如要讀取下面示例的數據:
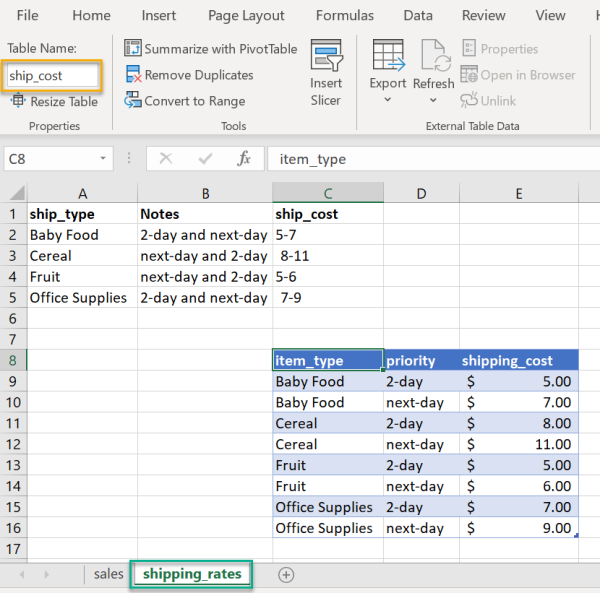
from openpyxl import load_workbook import pandas as pd from pathlib import Path src_file = ' sales1.xlsx'
加載整個工作簿:
cc = load_workbook(filename = src_file)
查看所有工作表:
cc.sheetnames
['sales', 'shipping_rates']
要訪問特定的工作表:
sheet = cc['shipping_rates']
要查看所有命名表的列表:
sheet.tables.keys()
dict_keys(['ship_cost'])
該鍵對應于Excel中分配給表的名稱。這樣就可以設定要讀取的Excel范圍:
lookup_table = sheet.tables['ship_cost']
lookup_table.ref
'C8:E16'
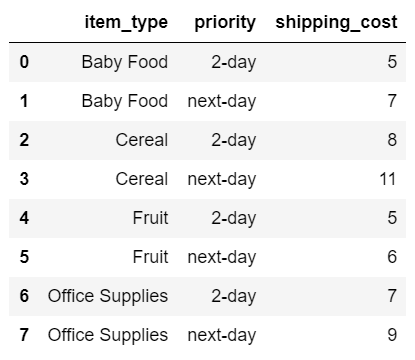
這樣就獲得了要加載的數據范圍。最后將其轉換為pandas DataFrame即可。遍歷每一行并轉換為DataFrame:
data = sheet[lookup_table.ref] rows_list = [] for row in data: cols = [] for col in row: cols.append(col.value) rows_list.append(cols) df = pd.DataFrame(data=rows_list[1:], index=None, columns=rows_list[0])
結果數據框:
上述內容就是Python 中怎么利用Pandas處理復雜的Excel數據,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





