溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下Namespace機制怎么理解的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
Namespace
Linux Namespace 是 Linux 提供的一種內核級別環境隔離的方法。這種隔離機制和 chroot 很類似,chroot 是把某個目錄修改為根目錄,從而無法訪問外部的內容。Linux Namesapce 在此基礎之上,提供了對 UTS、IPC、Mount、PID、Network、User 等的隔離機制,如下所示。
| 分類 | 系統調用參數 | 相關內核版本 |
|---|---|---|
| Mount Namespaces | CLONE_NEWNS | Linux 2.4.19 |
| UTS Namespaces | CLONE_NEWUTS | Linux 2.6.19 |
| IPC Namespaces | CLONE_NEWIPC | Linux 2.6.19 |
| PID Namespaces | CLONE_NEWPID | Linux 2.6.19 |
| Network Namespaces | CLONE_NEWNET | 始于Linux 2.6.24 完成于 Linux 2.6.29 |
| User Namespaces | CLONE_NEWUSER | 始于 Linux 2.6.23 完成于 Linux 3.8) |
★ Linux Namespace 官方文檔:Namespaces in operation”
namespace 有三個系統調用可以使用:
clone() --- 實現線程的系統調用,用來創建一個新的進程,并可以通過設計上述參數達到隔離。
unshare() --- 使某個進程脫離某個 namespace
setns(int fd, int nstype) --- 把某進程加入到某個 namespace
下面使用這幾個系統調用來演示 Namespace 的效果,更加詳細地可以看 DOCKER基礎技術:LINUX NAMESPACE(上)、 DOCKER基礎技術:LINUX NAMESPACE(下)。
UTS Namespace
UTS Namespace 主要是用來隔離主機名的,也就是每個容器都有自己的主機名。我們使用如下的代碼來進行演示。注意:假如在容器內部沒有設置主機名的話會使用主機的主機名的;假如在容器內部設置了主機名但是沒有使用 CLONE_NEWUTS 的話那么改變的其實是主機的主機名。
#define _GNU_SOURCE #include <sys/types.h> #include <sys/wait.h> #include <sys/mount.h> #include <stdio.h> #include <sched.h> #include <signal.h> #include <unistd.h> #define STACK_SIZE (1024 * 1024) static char container_stack[STACK_SIZE]; char* const container_args[] = { "/bin/bash", NULL }; int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); sethostname("container_dawn", 15); execv(container_args[0], container_args); printf("Something's wrong!\n"); return 1; } int main() { printf("Parent [%5d] - start a container!\n", getpid()); int container_id = clone(container_main, container_stack + STACK_SIZE, CLONE_NEWUTS | SIGCHLD, NULL); waitpid(container_id, NULL, 0); printf("Parent - container stopped!\n"); return 0; }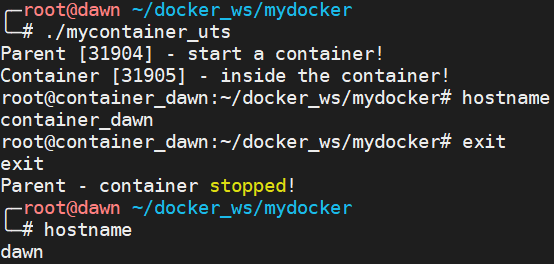
PID Namespace
每個容器都有自己的進程環境中,也就是相當于容器內進程的 PID 從 1 開始命名,此時主機上的 PID 其實也還是從 1 開始命名的,就相當于有兩個進程環境:一個主機上的從 1 開始,另一個容器里的從 1 開始。
為啥 PID 從 1 開始就相當于進程環境的隔離了呢?因此在傳統的 UNIX 系統中,PID 為 1 的進程是 init,地位特殊。它作為所有進程的父進程,有很多特權。另外,其還會檢查所有進程的狀態,我們知道如果某個進程脫離了父進程(父進程沒有 wait 它),那么 init 就會負責回收資源并結束這個子進程。所以要想做到進程的隔離,首先需要創建出 PID 為 1 的進程。
但是,【kubernetes 里面的話】
int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); sethostname("container_dawn", 15); execv(container_args[0], container_args); printf("Something's wrong!\n"); return 1; } int main() { printf("Parent [%5d] - start a container!\n", getpid()); int container_id = clone(container_main, container_stack + STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | SIGCHLD, NULL); waitpid(container_id, NULL, 0); printf("Parent - container stopped!\n"); return 0; }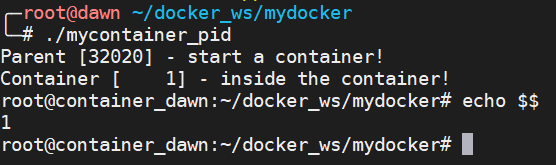
如果此時你在子進程的 shell 中輸入 ps、top 等命令,我們還是可以看到所有進程。這是因為,ps、top 這些命令是去讀 /proc 文件系統,由于此時文件系統并沒有隔離,所以父進程和子進程通過命令看到的情況都是一樣的。
IPC Namespace
常見的 IPC 有共享內存、信號量、消息隊列等。當使用 IPC Namespace 把 IPC 隔離起來之后,只有同一個 Namespace 下的進程才能相互通信,因為主機的 IPC 和其他 Namespace 中的 IPC 都是看不到了的。而這個的隔離主要是因為創建出來的 IPC 都會有一個唯一的 ID,那么主要對這個 ID 進行隔離就好了。
想要啟動 IPC 隔離,只需要在調用 clone 的時候加上 CLONE_NEWIPC 參數就可以了。
int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); sethostname("container_dawn", 15); execv(container_args[0], container_args); printf("Something's wrong!\n"); return 1; } int main() { printf("Parent [%5d] - start a container!\n", getpid()); int container_id = clone(container_main, container_stack + STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWIPC | SIGCHLD, NULL); waitpid(container_id, NULL, 0); printf("Parent - container stopped!\n"); return 0; }Mount Namespace 可以讓容器有自己的 root 文件系統。需要注意的是,在通過 CLONE_NEWNS 創建 mount namespace 之后,父進程會把自己的文件結構復制給子進程中。所以當子進程中不重新 mount 的話,子進程和父進程的文件系統視圖是一樣的,假如想要改變容器進程的視圖,一定需要重新 mount(這個是 mount namespace 和其他 namespace 不同的地方)。
另外,子進程中新的 namespace 中的所有 mount 操作都只影響自身的文件系統(注意這邊是 mount 操作,而創建文件等操作都是會有所影響的),而不對外界產生任何影響,這樣可以做到比較嚴格地隔離(當然這邊是除 share mount 之外的)。
下面我們重新掛載子進程的 /proc 目錄,從而可以使用 ps 來查看容器內部的情況。
int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); sethostname("container_dawn", 15); if (mount("proc", "/proc", "proc", 0, NULL) !=0 ) { perror("proc"); } execv(container_args[0], container_args); printf("Something's wrong!\n"); return 1; } int main() { printf("Parent [%5d] - start a container!\n", getpid()); int container_id = clone(container_main, container_stack + STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | SIGCHLD, NULL); waitpid(container_id, NULL, 0); printf("Parent - container stopped!\n"); return 0; }
★ 這里會有個問題就是在退出子進程之后,當再次使用 ps -elf 的時候會報錯,如下所示
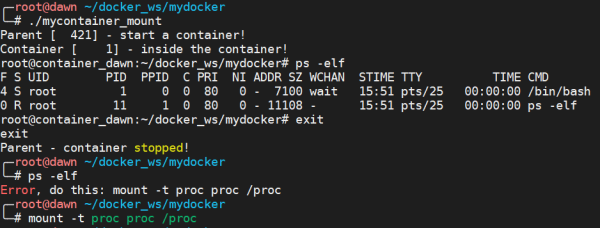
這是因為 /proc 是 share mount,對它的操作會影響所有的 mount namespace,可以看這里:http://unix.stackexchange.com/questions/281844/why-does-child-with-mount-namespace-affect-parent-mounts”
上面僅僅重新 mount 了 /proc 這個目錄,其他的目錄還是跟父進程一樣視圖的。一般來說,容器創建之后,容器進程需要看到的是一個獨立的隔離環境,而不是繼承宿主機的文件系統。接下來演示一個山寨鏡像,來模仿 Docker 的 Mount Namespace。也就是給子進程實現一個較為完整的獨立的 root 文件系統,讓這個進程只能訪問自己構成的文件系統中的內容(想想我們平常使用 Docker 容器的樣子)。
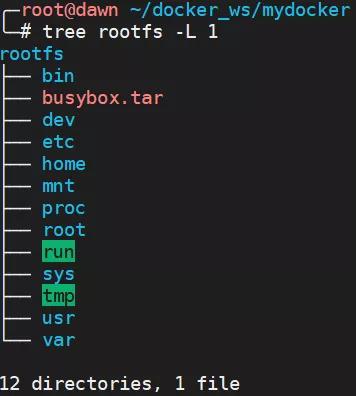
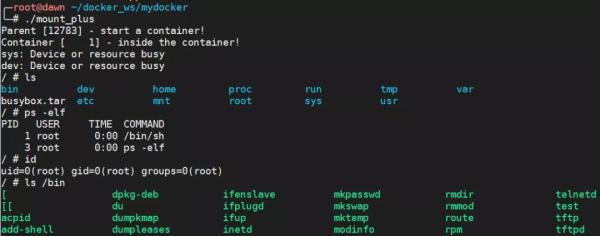
首先我們使用 docker export 將 busybox 鏡像導出成一個 rootfs 目錄,這個 rootfs 目錄的情況如圖所示,已經包含了 /proc、/sys 等特殊的目錄。
之后我們在代碼中將一些特殊目錄重新掛載,并使用 chroot() 系統調用將進程的根目錄改成上文的 rootfs 目錄。
char* const container_args[] = { "/bin/sh", NULL }; int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); sethostname("container_dawn", 15); if (mount("proc", "rootfs/proc", "proc", 0, NULL) != 0) { perror("proc"); } if (mount("sysfs", "rootfs/sys", "sysfs", 0, NULL)!=0) { perror("sys"); } if (mount("none", "rootfs/tmp", "tmpfs", 0, NULL)!=0) { perror("tmp"); } if (mount("udev", "rootfs/dev", "devtmpfs", 0, NULL)!=0) { perror("dev"); } if (mount("devpts", "rootfs/dev/pts", "devpts", 0, NULL)!=0) { perror("dev/pts"); } if (mount("shm", "rootfs/dev/shm", "tmpfs", 0, NULL)!=0) { perror("dev/shm"); } if (mount("tmpfs", "rootfs/run", "tmpfs", 0, NULL)!=0) { perror("run"); } if ( chdir("./rootfs") || chroot("./") != 0 ){ perror("chdir/chroot"); } // 改變根目錄之后,那么 /bin/bash 是從改變之后的根目錄中搜索了 execv(container_args[0], container_args); perror("exec"); printf("Something's wrong!\n"); return 1; } int main() { printf("Parent [%5d] - start a container!\n", getpid()); int container_id = clone(container_main, container_stack + STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | SIGCHLD, NULL); waitpid(container_id, NULL, 0); printf("Parent - container stopped!\n"); return 0; }最后,查看實現效果如下圖所示。
實際上,Mount Namespace 是基于 chroot 的不斷改良才被發明出來
的,chroot 可以算是 Linux 中第一個 Namespace。那么上面被掛載在容器根目錄上、用來為容器鏡像提供隔離后執行環境的文件系統,就是所謂的容器鏡像,也被叫做 rootfs(根文件系統)。需要明確的是,rootfs 只是一個操作系統所包含的文件、配置和目錄,并不包括操作系統內核。
User Namespace
容器內部看到的 UID 和 GID 和外部是不同的了,比如容器內部針對 dawn 這個用戶顯示的是 0,但是實際上這個用戶在主機上應該是 1000。要實現這樣的效果,需要把容器內部的 UID 和主機的 UID 進行映射,需要修改的文件是 /proc/
ID-INSIDE-NS ID-OUTSIDE-NS LENGTH
ID-INSIDE-NS :表示在容器內部顯示的 UID 或 GID
ID-OUTSIDE-NS:表示容器外映射的真實的 UID 和 GID
LENGTH:表示映射的范圍,一般為 1,表示一一對應
比如,下面就是將真實的 uid=1000 的映射為容器內的 uid =0:
$ cat /proc/8353/uid_map 0 1000 1
再比如,下面則表示把 namesapce 內部從 0 開始的 uid 映射到外部從 0 開始的 uid,其最大范圍是無符號 32 位整型(下面這條命令是在主機環境中輸入的)。
$ cat /proc/$$/uid_map 0 0 4294967295
默認情況,設置了 CLONE_NEWUSER 參數但是沒有修改上述兩個文件的話,容器中默認情況下顯示為 65534,這是因為容器找不到真正的 UID,所以就設置了最大的 UID。如下面的代碼所示:
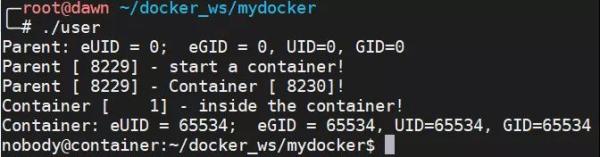
#define _GNU_SOURCE #include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/wait.h> #include <sys/mount.h> #include <sys/capability.h> #include <stdio.h> #include <sched.h> #include <signal.h> #include <unistd.h> #define STACK_SIZE (1024 * 1024) static char container_stack[STACK_SIZE]; char* const container_args[] = { "/bin/bash", NULL }; int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); printf("Container: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n", (long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid()); printf("Container [%5d] - setup hostname!\n", getpid()); //set hostname sethostname("container",10); execv(container_args[0], container_args); printf("Something's wrong!\n"); return 1; } int main() { const int gid=getgid(), uid=getuid(); printf("Parent: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n", (long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid()); printf("Parent [%5d] - start a container!\n", getpid()); int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWUSER | SIGCHLD, NULL); printf("Parent [%5d] - Container [%5d]!\n", getpid(), container_pid); printf("Parent [%5d] - user/group mapping done!\n", getpid()); waitpid(container_pid, NULL, 0); printf("Parent - container stopped!\n"); return 0; }當我以 dawn 這個用戶執行的該程序的時候,那么會顯示如下圖所示的效果。使用 root 用戶的時候是同樣的:

接下去,我們要開始來實現映射的效果了,也就是讓 dawn 這個用戶在容器中顯示為 0。代碼是幾乎完全拿耗子叔的博客上的,鏈接可見文末:
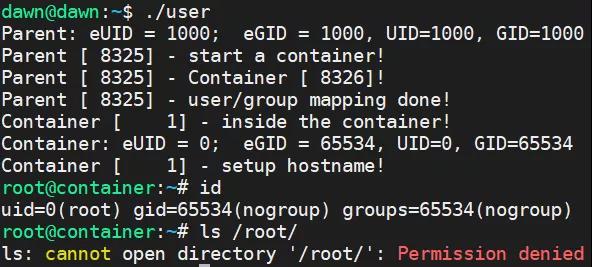
int pipefd[2]; void set_map(char* file, int inside_id, int outside_id, int len) { FILE* mapfd = fopen(file, "w"); if (NULL == mapfd) { perror("open file error"); return; } fprintf(mapfd, "%d %d %d", inside_id, outside_id, len); fclose(mapfd); } void set_uid_map(pid_t pid, int inside_id, int outside_id, int len) { char file[256]; sprintf(file, "/proc/%d/uid_map", pid); set_map(file, inside_id, outside_id, len); } int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); printf("Container: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n", (long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid()); /* 等待父進程通知后再往下執行(進程間的同步) */ char ch; close(pipefd[1]); read(pipefd[0], &ch, 1); printf("Container [%5d] - setup hostname!\n", getpid()); //set hostname sethostname("container",10); //remount "/proc" to make sure the "top" and "ps" show container's information mount("proc", "/proc", "proc", 0, NULL); execv(container_args[0], container_args); printf("Something's wrong!\n"); return 1; } int main() { const int gid=getgid(), uid=getuid(); printf("Parent: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n", (long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid()); pipe(pipefd); printf("Parent [%5d] - start a container!\n", getpid()); int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWUSER | SIGCHLD, NULL); printf("Parent [%5d] - Container [%5d]!\n", getpid(), container_pid); //To map the uid/gid, // we need edit the /proc/PID/uid_map (or /proc/PID/gid_map) in parent set_uid_map(container_pid, 0, uid, 1); printf("Parent [%5d] - user/group mapping done!\n", getpid()); /* 通知子進程 */ close(pipefd[1]); waitpid(container_pid, NULL, 0); printf("Parent - container stopped!\n"); return 0; }實現的最終效果如圖所示,可以看到在容器內部將 dawn 這個用戶 UID 顯示為了 0(root),但其實這個容器中的 /bin/bash 進程還是以一個普通用戶,也就是 dawn 來運行的,只是顯示出來的 UID 是 0,所以當查看 /root 目錄的時候還是沒有權限。
User Namespace 是以普通用戶運行的,但是別的 Namespace 需要 root 權限,那么當使用多個 Namespace 該怎么辦呢?我們可以先用一般用戶創建 User Namespace,然后把這個一般用戶映射成 root,那么在容器內用 root 來創建其他的 Namespace。
Network Namespace
隔離容器中的網絡,每個容器都有自己的虛擬網絡接口和 IP 地址。在 Linux 中,可以使用 ip 命令創建 Network Namespace(Docker 的源碼中,它沒有使用 ip 命令,而是自己實現了 ip 命令內的一些功能)。
下面就使用 ip 命令來講解一下 Network Namespace 的構建,以 bridge 網絡為例。bridge 網絡的拓撲圖一般如下圖所示,其中 br0 是 Linux 網橋。
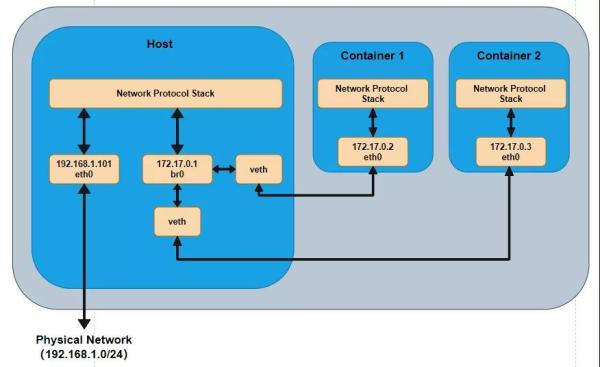
在使用 Docker 的時候,如果啟動一個 Docker 容器,并使用 ip link show 查看當前宿主機上的網絡情況,那么你會看到有一個 docker0 還有一個 veth**** 的虛擬網卡,這個 veth 的虛擬網卡就是上圖中 veth,而 docker0 就相當于上圖中的 br0。
那么,我們可以使用下面這些命令即可創建跟 docker 類似的效果(參考自耗子叔的博客,鏈接見文末參考,結合上圖加了一些文字)。
## 1. 首先,我們先增加一個網橋 lxcbr0,模仿 docker0 brctl addbr lxcbr0 brctl stp lxcbr0 off ifconfig lxcbr0 192.168.10.1/24 up #為網橋設置IP地址 ## 2. 接下來,我們要創建一個 network namespace ,命名為 ns1 # 增加一個 namesapce 命令為 ns1 (使用 ip netns add 命令) ip netns add ns1 # 激活 namespace 中的 loopback,即127.0.0.1(使用 ip netns exec ns1 相當于進入了 ns1 這個 namespace,那么 ip link set dev lo up 相當于在 ns1 中執行的) ip netns exec ns1 ip link set dev lo up ## 3. 然后,我們需要增加一對虛擬網卡 # 增加一對虛擬網卡,注意其中的 veth 類型。這里有兩個虛擬網卡:veth-ns1 和 lxcbr0.1,veth-ns1 網卡是要被安到容器中的,而 lxcbr0.1 則是要被安到網橋 lxcbr0 中的,也就是上圖中的 veth。 ip link add veth-ns1 type veth peer name lxcbr0.1 # 把 veth-ns1 按到 namespace ns1 中,這樣容器中就會有一個新的網卡了 ip link set veth-ns1 netns ns1 # 把容器里的 veth-ns1 改名為 eth0 (容器外會沖突,容器內就不會了) ip netns exec ns1 ip link set dev veth-ns1 name eth0 # 為容器中的網卡分配一個 IP 地址,并激活它 ip netns exec ns1 ifconfig eth0 192.168.10.11/24 up # 上面我們把 veth-ns1 這個網卡按到了容器中,然后我們要把 lxcbr0.1 添加上網橋上 brctl addif lxcbr0 lxcbr0.1 # 為容器增加一個路由規則,讓容器可以訪問外面的網絡 ip netns exec ns1 ip route add default via 192.168.10.1 ## 4. 為這個 namespace 設置 resolv.conf,這樣,容器內就可以訪問域名了 echo "nameserver 8.8.8.8" > conf/resolv.conf
上面基本上就相當于 docker 網絡的原理,只不過:
Docker 不使用 ip 命令而是,自己實現了 ip 命令內的一些功能。
Docker 的 resolv.conf 沒有使用這樣的方式,而是將其寫到指定的 resolv.conf 中,之后在啟動容器的時候將其和 hostname、host 一起以只讀的方式加載到容器的文件系統中。
docker 使用進程的 PID 來做 network namespace 的名稱。
同理,我們還可以使用如下的方式為正在運行的 docker 容器增加一個新的網卡
ip link add peerA type veth peer name peerB brctl addif docker0 peerA ip link set peerA up ip link set peerB netns ${container-pid} ip netns exec ${container-pid} ip link set dev peerB name eth2 ip netns exec ${container-pid} ip link set eth2 up ip netns exec ${container-pid} ip addr add ${ROUTEABLE_IP} dev eth2Namespace 情況查看
Cgroup 的操作接口是文件系統,位于 /sys/fs/cgroup 中。假如想查看 namespace 的情況同樣可以查看文件系統,namespace 主要查看 /proc/
我們以上面的 [PID Namespace 程序](#PID Namespace) 為例,當這個程序運行起來之后,我們可以看到其 PID 為 11702。
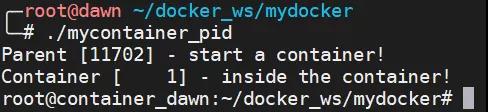
之后,我們保持這個子進程運行,然后打開另一個 shell,查看這個程序創建的子進程的 PID,也就是容器中運行的進程在主機中的 PID。
最后,我們分別查看 /proc/11702/ns 和 /proc/11703/ns 這兩個目錄的情況,也就是查看這兩個進程的 namespace 情況。可以看到其中 cgroup、ipc、mnt、net、user 都是同一個 ID,而 pid、uts 是不同的 ID。如果兩個進程的 namespace 編號相同,那么表示這兩個進程位于同一個 namespace 中,否則位于不同 namespace 中。
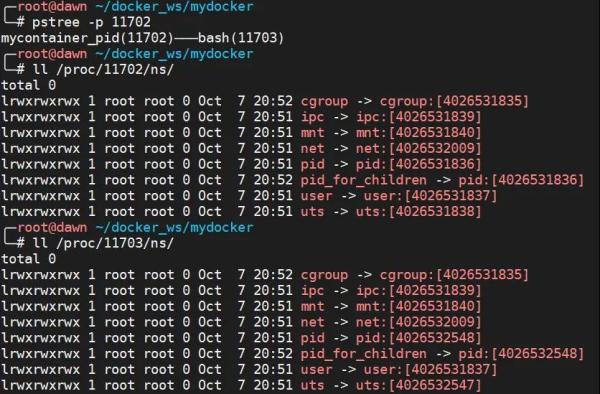
如果可以查看 ns 的情況之外,這些文件一旦被打開,只要 fd 被占用著,即使 namespace 中所有進程都已經結束了,那么創建的 namespace 也會一直存在。比如可以使用 mount --bind /proc/11703/ns/uts ~/uts,讓 11703 這個進程的 UTS Namespace 一直存在。
總結
Namespace 技術實際上修改了應用進程看待整個計算機“視圖”,即它的”視圖“已經被操作系統做了限制,只能”看到“某些指定的內容,這僅僅對應用進程產生了影響。但是對宿主機來說,這些被隔離了的進程,其實還是進程,跟宿主機上其他進程并無太大區別,都由宿主機統一管理。只不過這些被隔離的進程擁有額外設置過的 Namespace 參數。那么 Docker 項目在這里扮演的,更多是旁路式的輔助和管理工作。如下左圖所示
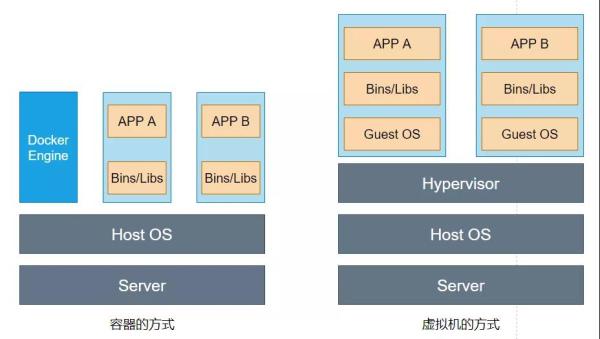
因此,相比虛擬機的方式,容器會更受歡迎。這是假如使用虛擬機的方式作為應用沙盒,那么必須要由 Hypervisor 來負責創建虛擬機,這個虛擬機是真實存在的,并且里面必須要運行一個完整的 Guest OS 才能執行用戶的應用進程。這樣就導致了采用虛擬機的方式之后,不可避免地帶來額外的資源消耗和占用。根據實驗,一個運行著 CentOS 的 KVM 虛擬機啟動后,在不做優化的情況下,虛擬機就需要占用 100-200 MB 內存。此外,用戶應用運行在虛擬機中,它對宿主機操作系統的調用就不可避免地要經過虛擬機軟件的攔截和處理,這本身就是一層消耗,尤其對資源、網絡和磁盤 IO 的損耗非常大。
而假如使用容器的方式,容器化之后應用本質還是宿主機上的一個進程,這也就意味著因為虛擬機化帶來的性能損耗是不存在的;而另一方面使用 Namespace 作為隔離手段的容器并不需要單獨的 Guest OS,這就使得容器額外的資源占用幾乎可以忽略不計。
總得來說,“敏捷”和“高性能”是容器相對于虛擬機最大的優勢,也就是容器能在 PaaS 這種更加細粒度的資源管理平臺上大行其道的重要原因。
但是!基于 Linux Namespace 的隔離機制相比于虛擬化技術也有很多不足之處,其中最主要的問題就是隔離不徹底。
首先,容器只是運行在宿主機上的一種特殊進程,那么容器之間使用的還是同一個宿主機上的操作系統。盡管可以在容器里面通過 mount namesapce 單獨掛載其他不同版本的操作系統文件,比如 centos、ubuntu,但是這并不能改變共享宿主機內核的事實。這就意味著你要在 windows 上運行 Linux 容器,或者在低版本的 Linux 宿主機上運行高版本的 Linux 容器都是行不通的。
而擁有虛擬機技術和獨立 Guest OS 的虛擬機就要方便多了。
其次,在 Linux 內核中,有很多資源和對象都是不能被 namespace 化的,比如時間。假如你的容器中的程序使用 settimeofday(2) 系統調用修改了時間,整個宿主機的時間都會被隨之修改。
相比虛擬機里面可以隨意折騰的自由度,在容器里部署應用的時候,“什么能做,什么不能做” 是用戶必須考慮的一個問題。之外,容器給應用暴露出來的攻擊面是相當大的,應用“越獄”的難度也比虛擬機低很多。雖然,實踐中可以使用 Seccomp 等技術對容器內部發起的所有系統調用進行過濾和甄別來進行安全加固,但這種方式因為多了一層對系統調用的過濾,也會對容器的性能產生影響。因此,在生產環境中沒有人敢把運行在物理機上的 Linux 容器直接暴露到公網上。
另外,容器是一個“單進程”模型。容器的本質是一個進程,用戶的應用進程實際上就是容器里 PID=1 的進程,而這個進程也是后續創建的所有進程的父進程。這也就意味著,在一個容器中,你沒辦法同時運行兩個不同的應用,除非能事先找到一個公共的 PID=1 的程序來充當兩者的父進程,比如使用 systemd 或者 supervisord。容器的設計更多是希望容器和應用同生命周期的,而不是容器還在運行,而里面的應用早已經掛了。
以上就是“Namespace機制怎么理解”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





