溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了JS應用程序中怎么執行語音識別,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
語音識別是計算機科學和計算語言學的一個跨學科子領域。它可以識別口語并將其翻譯成文本,它也被稱為自動語音識別(ASR),計算機語音識別或語音轉文本(STT)。
機器學習(ML)是人工智能(AI)的一種應用,它使系統能夠自動學習并從經驗中進行改進,而無需進行明確的編程。機器學習在本世紀提供了大多數語音識別方面的突破。如今,語音識別技術無處不在,例如Apple Siri,Amazon Echo和Google Nest。
語音識別以及語音響應(也稱為語音合成或文本到語音(TTS))由Web speech API提供支持。
在本文中,我們重點介紹JavaScript應用程序中的語音識別。另一篇文章介紹了語音合成。
SpeechRecognition 是識別服務的控制器接口,在Chrome中稱為 webkitSpeechRecognition。SpeechRecognition 處理從識別服務發送的 SpeechRecognitionEvent。SpeechRecognitionEvent.results 返回一個SpeechRecognitionResultList 對象,該對象表示當前會話的所有語音識別結果。
可以使用以下幾行代碼來初始化 SpeechRecognition:
// 創建一個SpeechRecognition對象
const recognition = new webkitSpeechRecognition();
// 配置設置以使每次識別都返回連續結果
recognition.continuous = true;
// 配置應返回臨時結果的設置
recognition.interimResults = true;
// 正確識別單詞或短語時的事件處理程序
recognition.onresult = function (event) {
console.log(event.results);
};ognition.start() 開始語音識別,而 ognition.stop() 停止語音識別,它也可以中止( recognition.abort)。
當頁面正在訪問您的麥克風時,地址欄中將顯示一個麥克風圖標,以顯示該麥克風已打開并且正在運行。
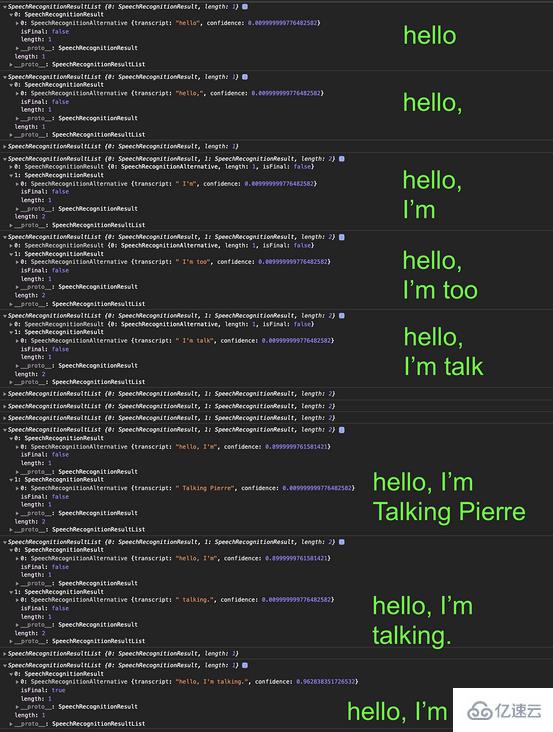
我們用句子對頁面說。“hello comma I'm talking period.” onresult 在我們說話時顯示所有臨時結果。
這是此示例的HTML代碼:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Speech Recognition</title>
<script>
window.onload = () => {
const button = document.getElementById('button');
button.addEventListener('click', () => {
if (button.style['animation-name'] === 'flash') {
recognition.stop();
button.style['animation-name'] = 'none';
button.innerText = 'Press to Start';
content.innerText = '';
} else {
button.style['animation-name'] = 'flash';
button.innerText = 'Press to Stop';
recognition.start();
}
});
const content = document.getElementById('content');
const recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
recognition.onresult = function (event) {
let result = '';
for (let i = event.resultIndex; i < event.results.length; i++) {
result += event.results[i][0].transcript;
}
content.innerText = result;
};
};
</script>
<style>
button {
background: yellow;
animation-name: none;
animation-duration: 3s;
animation-iteration-count: infinite;
}
@keyframes flash {
0% {
background: red;
}
50% {
background: green;
}
}
</style>
</head>
<body>
<button id="button">Press to Start</button>
<div id="content"></div>
</body>
</html>第25行創建了 SpeechRecognition 對象,第26和27行配置了 SpeechRecognition 對象。
當一個單詞或短語被正確識別時,第28-34行設置一個事件處理程序。
第19行開始語音識別,第12行停止語音識別。
在第12行,單擊該按鈕后,它可能仍會打印出一些消息。這是因為 Recognition.stop() 嘗試返回到目前為止捕獲的SpeechRecognitionResult。如果您希望它完全停止,請改用 ognition.abort()。
您會看到動畫按鈕的代碼(第38-51行)比語音識別代碼長。這是該示例的視頻剪輯:https://youtu.be/5V3bb5YOnj0
以下是瀏覽器兼容性表:

網絡語音識別依賴于瀏覽器自己的語音識別引擎。在Chrome中,此引擎在云中執行識別。因此,它僅可在線運行。
有一些開源語音識別庫,以下是基于npm趨勢的這些庫的列表:
Annyang是一個JavaScript語音識別庫,用于通過語音命令控制網站。它建立在SpeechRecognition Web API之上。在下一節中,我們將舉例說明annyang的工作原理。
artyom.js是一個JavaScript語音識別和語音合成庫。它建立在Web語音API的基礎上,除語音命令外,它還提供語音響應。
Mumble是一個JavaScript語音識別庫,用于通過語音命令控制網站。它建立在SpeechRecognition Web API之上,這類似于annyang的工作方式。
Julius是面向語音相關研究人員和開發人員的高性能,占用空間小的大詞匯量連續語音識別(LVCSR)解碼器軟件。它可以在從微型計算機到云服務器的各種計算機和設備上執行實時解碼。Julis是使用C語言構建的,而julius.js是Julius自以為是JavaScript的移植版。
voice-commands.js是一個JavaScript語音識別庫,用于通過語音命令控制網站。它建立在SpeechRecognition Web API之上,這類似于annyang的工作方式。
Annyang初始化一個 SpeechRecognition 對象,該對象定義如下:
var SpeechRecognition = root.SpeechRecognition || root.webkitSpeechRecognition || root.mozSpeechRecognition || root.msSpeechRecognition || root.oSpeechRecognition;
有一些API可以啟動或停止annyang:
annyang.start:使用選項(自動重啟,連續或暫停)開始監聽,例如 annyang.start({autoRestart:true,Continuous:false})。
annyang.abort:停止收聽(停止SpeechRecognition引擎或關閉麥克風)。
annyang.pause:停止收聽(無需停止SpeechRecognition引擎或關閉麥克風)。
annyang.resume:開始收聽時不帶任何選項。
這是此示例的HTML代碼:
<!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Annyang</title> <script src="//cdnjs.cloudflare.com/ajax/libs/annyang/2.6.1/annyang.min.js"></script> <script> window.onload = () => { const button = document.getElementById('button'); button.addEventListener('click', () => { if (button.style['animation-name'] === 'flash') { annyang.pause(); button.style['animation-name'] = 'none'; button.innerText = 'Press to Start'; content.innerText = ''; } else { button.style['animation-name'] = 'flash'; button.innerText = 'Press to Stop'; annyang.start(); } }); const content = document.getElementById('content'); const commands = { hello: () => { content.innerText = 'You said hello.'; }, 'hi *splats': (name) => { content.innerText = `You greeted to ${name}.`; }, 'Today is :day': (day) => { content.innerText = `You said ${day}.`; }, '(red) (green) (blue)': () => { content.innerText = 'You said a primary color name.'; }, }; annyang.addCommands(commands); }; </script> <style> button { background: yellow; animation-name: none; animation-duration: 3s; animation-iteration-count: infinite; } @keyframes flash { 0% { background: red; } 50% { background: green; } } </style> </head> <body> <button id="button">Press to Start</button> <div id="content"></div> </body> </html>
第7行添加了annyang源代碼。
第20行啟動annyang,第13行暫停annyang。
Annyang提供語音命令來控制網頁(第26-42行)。
第27行是一個簡單的命令。如果用戶打招呼,頁面將回復“您說‘你好’。”
第30行是帶有 splats 的命令,該命令會貪婪地捕獲命令末尾的多詞文本。如果您說“hi,愛麗絲e”,它的回答是“您向愛麗絲致意。”如果您說“嗨,愛麗絲和約翰”,它的回答是“您向愛麗絲和約翰打招呼。”
第33行是一個帶有命名變量的命令。一周的日期被捕獲為 day,在響應中被呼出。
第36行是帶有可選單詞的命令。如果您說“黃色”,則將其忽略。如果您提到任何一種原色,則會以“您說的是原色名稱”作為響應。
從第26行到第39行定義的所有命令都在第41行添加到annyang中。
... ...
我們已經了解了JavaScript應用程序中的語音識別,Chrome對Web語音API提供了最好的支持。我們所有的示例都是在Chrome瀏覽器上實現和測試的。
在探索Web語音API時,這里有一些提示:如果您不想在日常生活中傾聽,請記住關閉語音識別應用程序。
JS是JavaScript的簡稱,它是一種直譯式的腳本語言,其解釋器被稱為JavaScript引擎,是瀏覽器的一部分,主要用于web的開發,可以給網站添加各種各樣的動態效果,讓網頁更加美觀。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“JS應用程序中怎么執行語音識別”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





