溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關怎么利用Python爬蟲爬取代理IP,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
功能1: 爬取西拉ip代理官網上的代理ip
環境:python3.8+pycharm
庫:requests,lxml
分析網頁源碼:
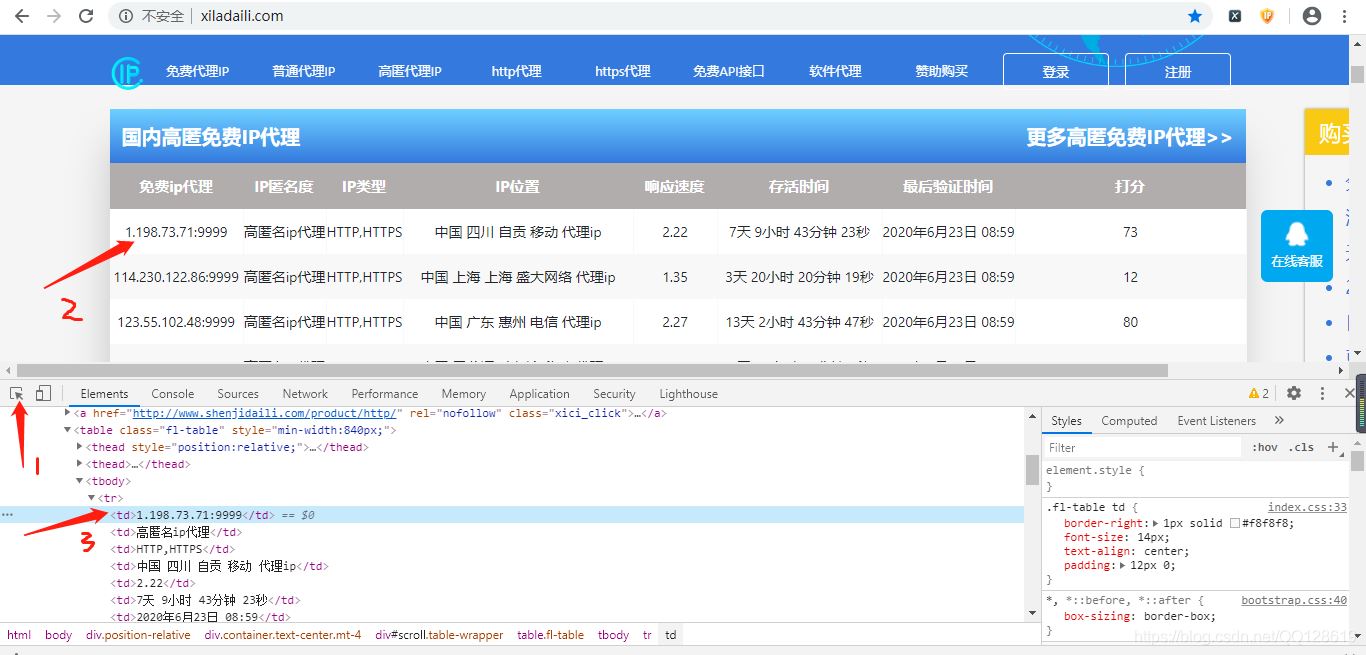
選中div元素后右鍵找到Copy再深入子菜單找到Copy Xpath點擊一下就復制到XPath
我們復制下來的Xpth內容為:/html/body/div/div[3]/div[2]/table/tbody/tr[50]/td[1]
雖然可以查出來ip,但不利于程序自動爬取所有IP,利用谷歌XpathHelp測試一下

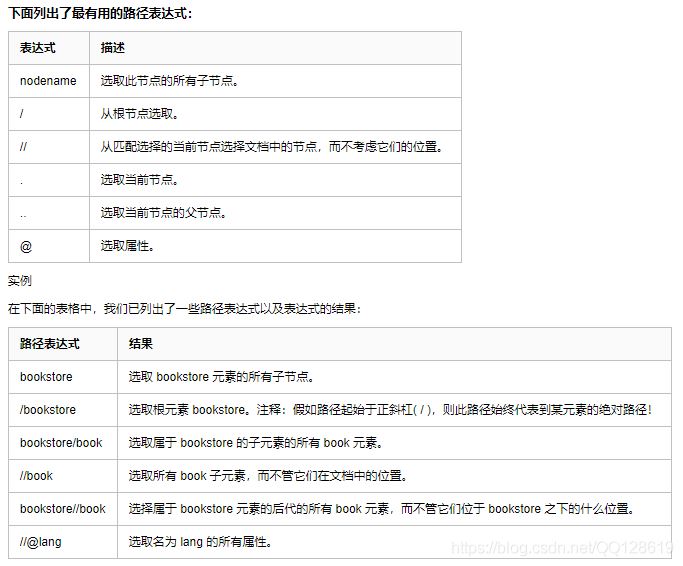
從上圖可以看出,只匹配到了一個Ip,我們稍作修改,即可達到目的
,有關xpath規則,可以參考下表;


經過上面的規則學習后,我們修改為://*[@class=‘mt-0 mb-2 table-responsive']/table/tbody/tr/td[1],再利用xpthhelp工具驗證一下:
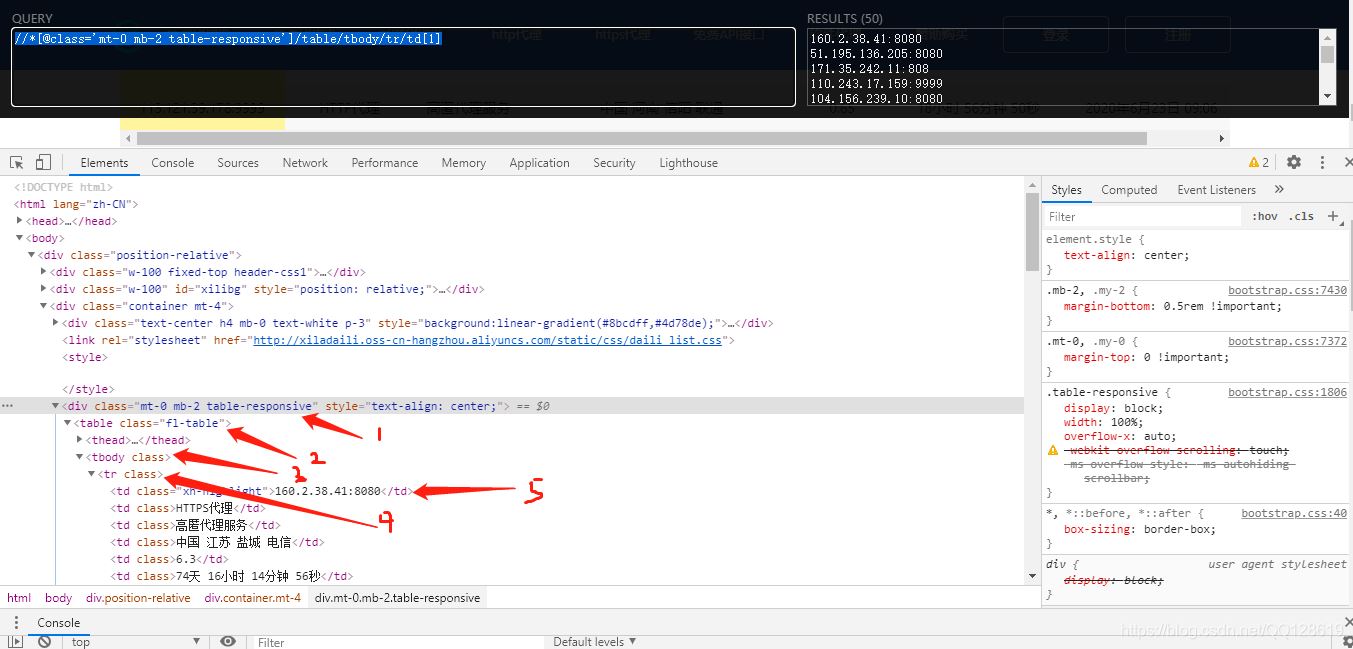
這樣我們就可以爬取整個頁面的Ip地址了,為了方便爬取更多的IP,我們繼續往下翻頁,找到翻頁按鈕:
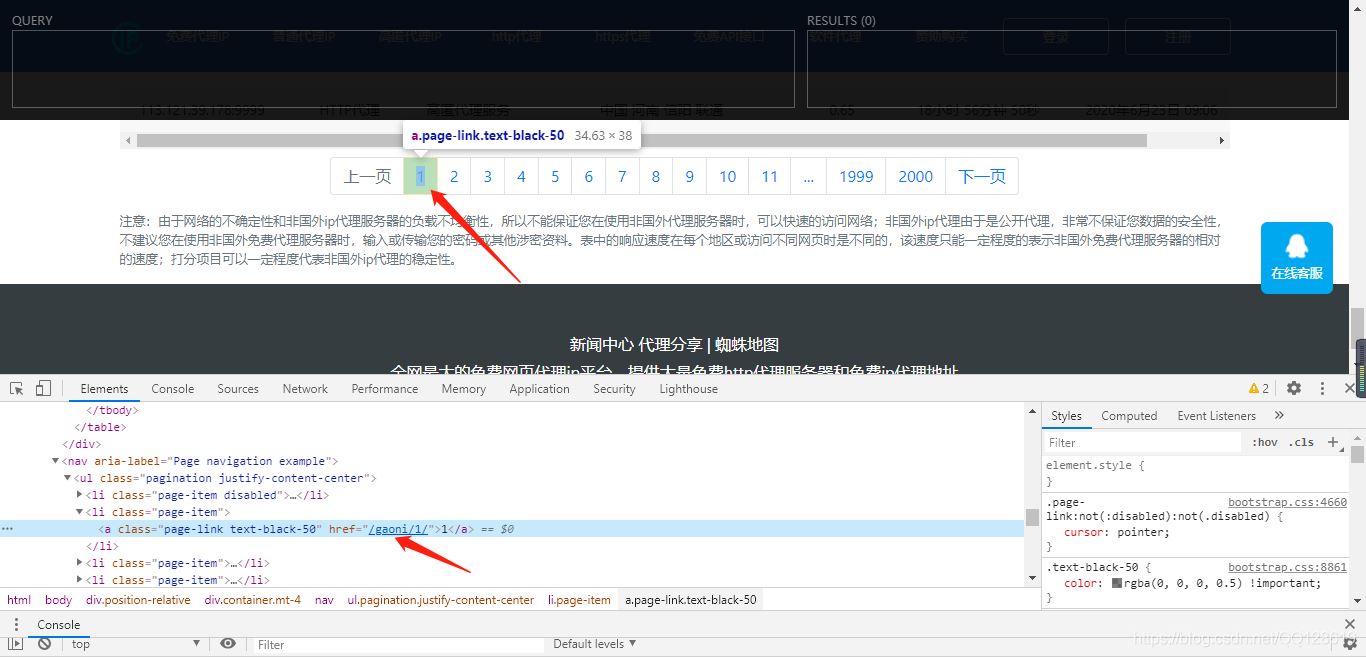
找規律,發現每翻一頁,a標簽下的href連接地址加1即可,python程序可以利用for循環解決翻頁問題即可。
為了提高IP代理的質量,我們爬取評分高的IP來使用。找到評分欄下的Xpath路徑,這里不再做詳細介紹,思路參考上面找IP地址的思路,及XPath規則,過程參考下圖:
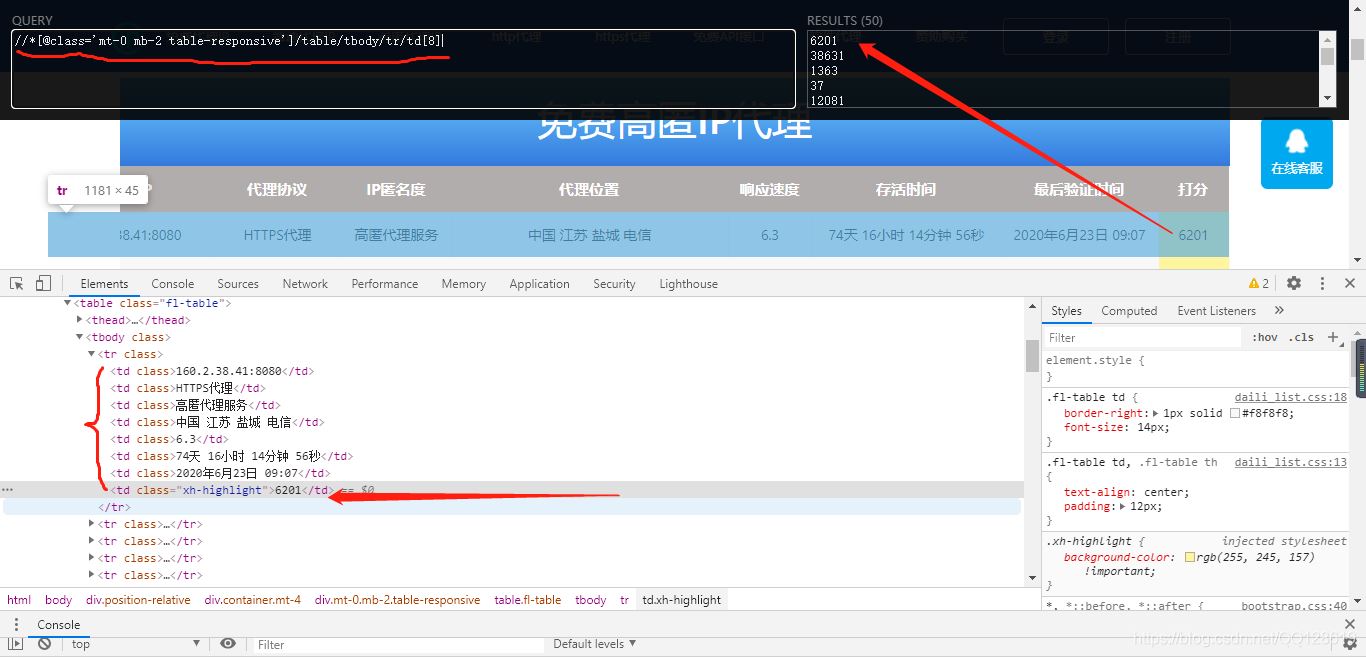
Python代碼實現
代碼可復制粘貼直接使用,如果出現報錯,修改一下cookie。這里使用代理ip爬取,防止IP被封。當然這里的代碼還是基礎的,有空可以寫成代理池,多任務去爬。當然還可以使用其它思路去實現,這里只做入門介紹。當有了這些代理IP后,我們可以用文件保存,或者保存到數據庫中,根據實際使用情況而定,這里不做保存,只放到列表變量中保存。
import requests
from lxml import etree
import time
class XiLaIp_Spider:
def __init__(self):
self.url = 'http://www.xiladaili.com/gaoni/'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'cookie': 'td_cookie=1539882751; csrftoken=lymOXQp49maLMeKXS1byEMMmsavQPtOCOUwy6WIbfMNazZW80xKKA8RW2Zuo6ssy; Hm_lvt_31dfac66a938040b9bf68ee2294f9fa9=1592547159; Hm_lvt_9bfa8deaeafc6083c5e4683d7892f23d=1592535959,1592539254,1592612217; Hm_lpvt_9bfa8deaeafc6083c5e4683d7892f23d=1592612332',
}
self.proxy = '116.196.85.150:3128'
self.proxies = {
"http": "http://%(proxy)s/" % {'proxy': self.proxy},
"https": "http://%(proxy)s/" % {'proxy': self.proxy}
}
self.list1 = []
def get_url(self):
file = open('Ip_Proxy.txt', 'a', encoding='utf-8')
ok_file = open('OkIp_Proxy.txt', 'a', encoding='utf-8')
for index in range(50):
time.sleep(3)
try:
res = requests.get(url=self.url if index == 0 else self.url + str(index) + "/", headers=self.headers,
proxies=self.proxies, timeout=10).text
except:
continue
data = etree.HTML(res).xpath("//*[@class='mt-0 mb-2 table-responsive']/table/tbody/tr/td[1]")
# '//*[@id="scroll"]/table/tbody/tr/td[1]'
score_data = etree.HTML(res).xpath("//*[@class='mt-0 mb-2 table-responsive']/table/tbody/tr/td[8]")
for i, j in zip(data, score_data):
# file.write(i.text + '\n')
score = int(j.text)
# 追加評分率大于十萬的ip
if score > 100000:
self.list1.append(i.text)
set(self.list1)
file.close()
ok_ip = []
for i in self.list1:
try:
# 驗證代理ip是否有效
res = requests.get(url='https://www.baidu.com', headers=self.headers, proxies={'http': 'http://' + i},
timeout=10)
if res.status_code == 200:
# ok_file.write(i + '\n')
ok_ip.append(i)
except:
continue
ok_file.close()
return ok_ip
def run(self):
return self.get_url()
dl = XiLaIp_Spider()
dl.run()上述就是小編為大家分享的怎么利用Python爬蟲爬取代理IP了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





