溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python爬蟲中爬取代理IP的方法是什么,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
在我們爬蟲的過程中,難免會遇到比較惡心的網站(安全性較高),來阻止我們的爬蟲,跑著跑著,就斷掉了!報錯了啊!丟失連接之類的。幸幸苦苦的抓了半天又得從頭來,心累啊!
這就是網站的反爬蟲在起作用了。
一般來說我們會遇到網站反爬蟲策略下面幾點:
限制IP訪問頻率,超過頻率就斷開連接。(這種方法解決辦法就是,降低爬蟲的速度在每個請求前面加上time.sleep;或者不停的更換代理IP,這樣就繞過反爬蟲機制啦!)
后臺對訪問進行統計,如果單個userAgent訪問超過閾值,予以封鎖。(效果出奇的棒!不過誤傷也超級大,一般站點不會使用,不過我們也考慮進去。
還有針對于cookies的 (這個解決辦法更簡單,一般網站不會用)
有些網站會監測你的IP,如果在某一時間段內,你的IP多次訪問網頁,就會封鎖你的IP,過段時間再放出來。
對于第一種限制IP的,我們怎么來防止這種反爬蟲呢?(與本篇博客無關,只是想挑起大家的好奇心)
對咯,就是用代理IP,OK,想要獲取到代理IP,就要找到多個IP,所以我們今天先做第一步,把代理ip網站的所有IP給抓取下來;
我這里找到的一個網站是http://www.66ip.cn/,個人感覺還不錯,反正是用來練手,嘿嘿~~~
步驟1、爬取整個網頁
我們的思路是:先把網頁所有內容爬取下來,然后再提取我們需要的信息。
首先按照慣例我們導入模塊:
# -*- coding:utf-8 -*- import bs4 import urllib from bs4 import BeautifulSoup import urllib2
我們寫一個基本的請求網頁并返回response的函數:
# -*- coding:utf-8 -*- import bs4 import urllib from bs4 import BeautifulSoup import urllib2 #構造網頁請求函數 def gethtml(url): request = urllib2.Request(url) response = urllib2.urlopen(request) html = response.read() return html
哈哈,簡單吧!
這只是基本的,其實學過爬蟲的都知道,很多網站都都會拒絕非瀏覽器的請求的、怎么區分的呢?就是你發起的請求是否包含正常的User-Agent 這玩意兒長啥樣兒?就下面這樣(如果不一樣 請按一下F5)
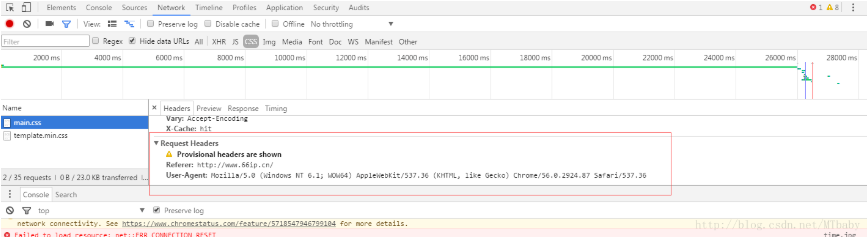
requests的請求的User-Agent 大概是這樣 python-requests/2.3.0 CPython/2.6.6 Windows/7 這個不是正常的User-Agent、所以我們得自己造一個來欺騙服務器(requests又一個headers參數能幫助我們偽裝成瀏覽器哦!不知道的小哥兒 一定是沒有看官方文檔!在這里request官方文檔這樣很不好誒!o(一︿一+)o),讓他以為我們是真的瀏覽器。
所以我們修改一下代碼:
# -*- coding:utf-8 -*-
import bs4
import urllib
from bs4 import BeautifulSoup
import urllib2
#構造網頁請求函數
def gethtml(url):
user_agent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87
Safari/537.36"
headers = {"User-Agent":user_agent}
request = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(request)
html = response.read()
return html好了,接下來就要寫主函數了~~擼起袖子開干!!
步驟2、打開網站,查看IP所處位置
按F12
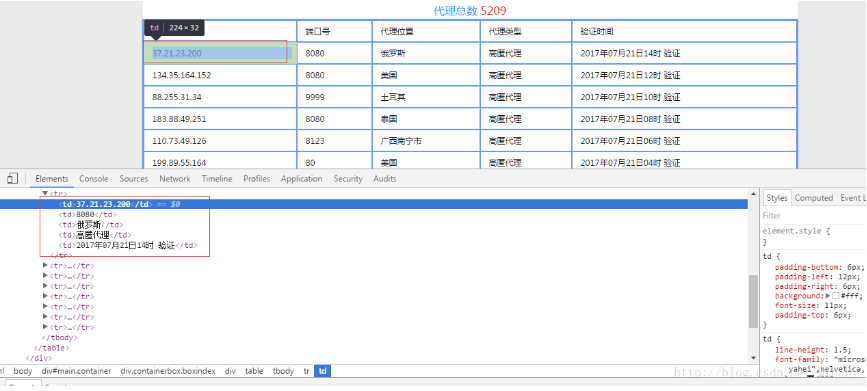
發現所有IP信息都在tr標簽下的td節點中。OK,很好,非常好,非常方便~~
現在我們要做的就是找到這個標簽。
先用BeautifulSoup解析網頁
sp = bs4.BeautifulSoup(html_doc,'html.parser',from_encoding="utf-8")
trs = sp.find_all("tr")
for tr in trs: # tr是每一行
for a in tr.children:
# 發現a的編碼方式是unicode,所以講unicode轉成utf-8字符串
ip_val = a.string.encode('utf-8').strip()
print ip_val好了,上面我們已經打印出來了td標簽里面的所有內容。可是我們這里只想要IP怎么辦呢??
好辦,我們來判斷抓取到的數據是不是IP,大家都知道,IP是有四位整數,通過點(.)來分隔的。恩,找到規律后,我們來定義一個函數來判斷IP。
def is_invalid_ip4(ip):
ip = ip.strip()
# ip4格式:a.b.c.d
its = [v for v in ip.split('.')]
# .分數不對
if len(its) != 4:
return False
# 值不是數字
for v in its:
if not v.isdigit():
return False
return True好了,我們來調用這個函數,修改上面的代碼:
#使用beautifulsoup來解析網頁
sp = bs4.BeautifulSoup(html_doc,'html.parser',from_encoding="utf-8")
trs = sp.find_all("tr")
#先定義一個空列表,用于存放爬取到的ip
iplist = []
for tr in trs:
# tr是每一行
for a in tr.children:
# 發現a的編碼方式是unicode,所以講unicode轉成utf-8字符串
ip_val = a.string.encode('utf-8').strip()
#調用判斷有效ip函數
if is_invalid_ip4(ip_val):
iplist.append(ip_val)
print ip_val
#這里發現ip在tr的第一列,所以我們每次取到第一個數據后跳出
break
print '-'*32#我是分隔符好了,這樣我們就吧爬取到的IP放進了iplist這個列表里。
怎么樣,很簡單吧~~
步驟3、整理代碼
那假如我們想要很多條IP怎么辦,一頁根本不夠啊,OK,統統滿足你——爬取多個網頁的IP,就要不停的請求網頁,那這個網址是變化的怎么辦?
好吧,我又幫你找到規律了,只需要將網址的index改變就可以了。好吧,
完整代碼:
# -*- coding:utf-8 -*-
import bs4
import urllib
from bs4 import BeautifulSoup
import urllib2
import requests
# 網址:http://www.66ip.cn/index.html
#這里看出每一頁的網址由index下標表示,即index是幾就代表第幾頁
#我這里只爬取五個,你隨意啊
def main():
#先定義一個空列表,用于存放爬取到的ip
iplist = []
for i in range(1,5):
#構造url
s = ".html"
url = "http://www.66ip.cn/"
#調用網頁請求函數
cur_url = url + str(i) + s
html_doc = gethtml(cur_url)
#使用beautifulsoup來解析網頁
sp = bs4.BeautifulSoup(html_doc,'html.parser',from_encoding="utf-8")
trs = sp.find_all("tr")
for tr in trs:
# tr是每一行
for a in tr.children:
#發現a的編碼方式是unicode,所以講unicode轉成utf-8字符串
ip_val = a.string.encode('utf-8').strip()
#調用判斷有效ip函數
if is_invalid_ip4(ip_val):
iplist.append(ip_val)
print ip_val
#這里發現ip在tr的第一列,所以我們每次取到第一個數據后跳出
break
print '-'*32#我是分隔符
def is_invalid_ip4(ip):
ip = ip.strip()
# ip4格式:a.b.c.d
its = [v for v in ip.split('.')]
# .分數不對
if len(its) != 4:
return False
# 值不是數字
for v in its:
if not v.isdigit():
return False
return True
#構造網頁請求函數
def gethtml(url):
user_agent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87
Safari/537.36"
headers = {"User-Agent":user_agent}
request = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(request)
html = response.read()
return html
if __name__ == "__main__":
main()完美!!
結果如下:
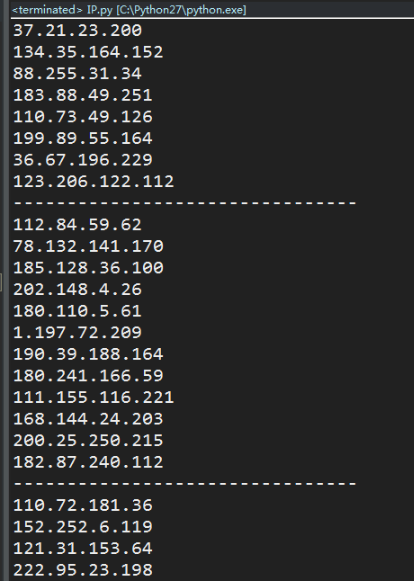
關于Python爬蟲中爬取代理IP的方法是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





