溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關利用Python爬蟲實現爬取網站中的數據并存入MySQL數據庫中,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
實驗環境
1.安裝Python 3.7
2.安裝requests, bs4,pymysql 模塊
2.編寫代碼
# 51cto 博客頁面數據插入mysql數據庫
# 導入模塊
import re
import bs4
import pymysql
import requests
# 連接數據庫賬號密碼
db = pymysql.connect(host='172.171.13.229',
user='root', passwd='abc123',
db='test', port=3306,
charset='utf8')
# 獲取游標
cursor = db.cursor()
def open_url(url):
# 連接模擬網頁訪問
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/57.0.2987.98 Safari/537.36'}
res = requests.get(url, headers=headers)
return res
# 爬取網頁內容
def find_text(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
# 博客名
titles = []
targets = soup.find_all("a", class_="tit")
for each in targets:
each = each.text.strip()
if "置頂" in each:
each = each.split(' ')[0]
titles.append(each)
# 閱讀量
reads = []
read1 = soup.find_all("p", class_="read fl on")
read2 = soup.find_all("p", class_="read fl")
for each in read1:
reads.append(each.text)
for each in read2:
reads.append(each.text)
# 評論數
comment = []
targets = soup.find_all("p", class_='comment fl')
for each in targets:
comment.append(each.text)
# 收藏
collects = []
targets = soup.find_all("p", class_='collect fl')
for each in targets:
collects.append(each.text)
# 發布時間
dates=[]
targets = soup.find_all("a", class_='time fl')
for each in targets:
each = each.text.split(':')[1]
dates.append(each)
# 插入sql 語句
sql = """insert into blog (blog_title,read_number,comment_number, collect, dates)
values( '%s', '%s', '%s', '%s', '%s');"""
# 替換頁面 \xa0
for titles, reads, comment, collects, dates in zip(titles, reads, comment, collects, dates):
reads = re.sub('\s', '', reads)
comment = re.sub('\s', '', comment)
collects = re.sub('\s', '', collects)
cursor.execute(sql % (titles, reads, comment, collects,dates))
db.commit()
pass
# 統計總頁數
def find_depth(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
depth = soup.find('li', class_='next').previous_sibling.previous_sibling.text
return int(depth)
# 主函數
def main():
host = "https://blog.51cto.com/13760351"
res = open_url(host) # 打開首頁鏈接
depth = find_depth(res) # 獲取總頁數
# 爬取其他頁面信息
for i in range(1, depth + 1):
url = host + '/p' + str(i) # 完整鏈接
res = open_url(url) # 打開其他鏈接
find_text(res) # 爬取數據
# 關閉游標
cursor.close()
# 關閉數據庫連接
db.close()
if __name__ == '__main__':
main()3..MySQL創建對應的表
CREATE TABLE `blog` ( `row_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵', `blog_title` varchar(52) DEFAULT NULL COMMENT '博客標題', `read_number` varchar(26) DEFAULT NULL COMMENT '閱讀數量', `comment_number` varchar(16) DEFAULT NULL COMMENT '評論數量', `collect` varchar(16) DEFAULT NULL COMMENT '收藏數量', `dates` varchar(16) DEFAULT NULL COMMENT '發布日期', PRIMARY KEY (`row_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;

4.運行代碼,查看效果:
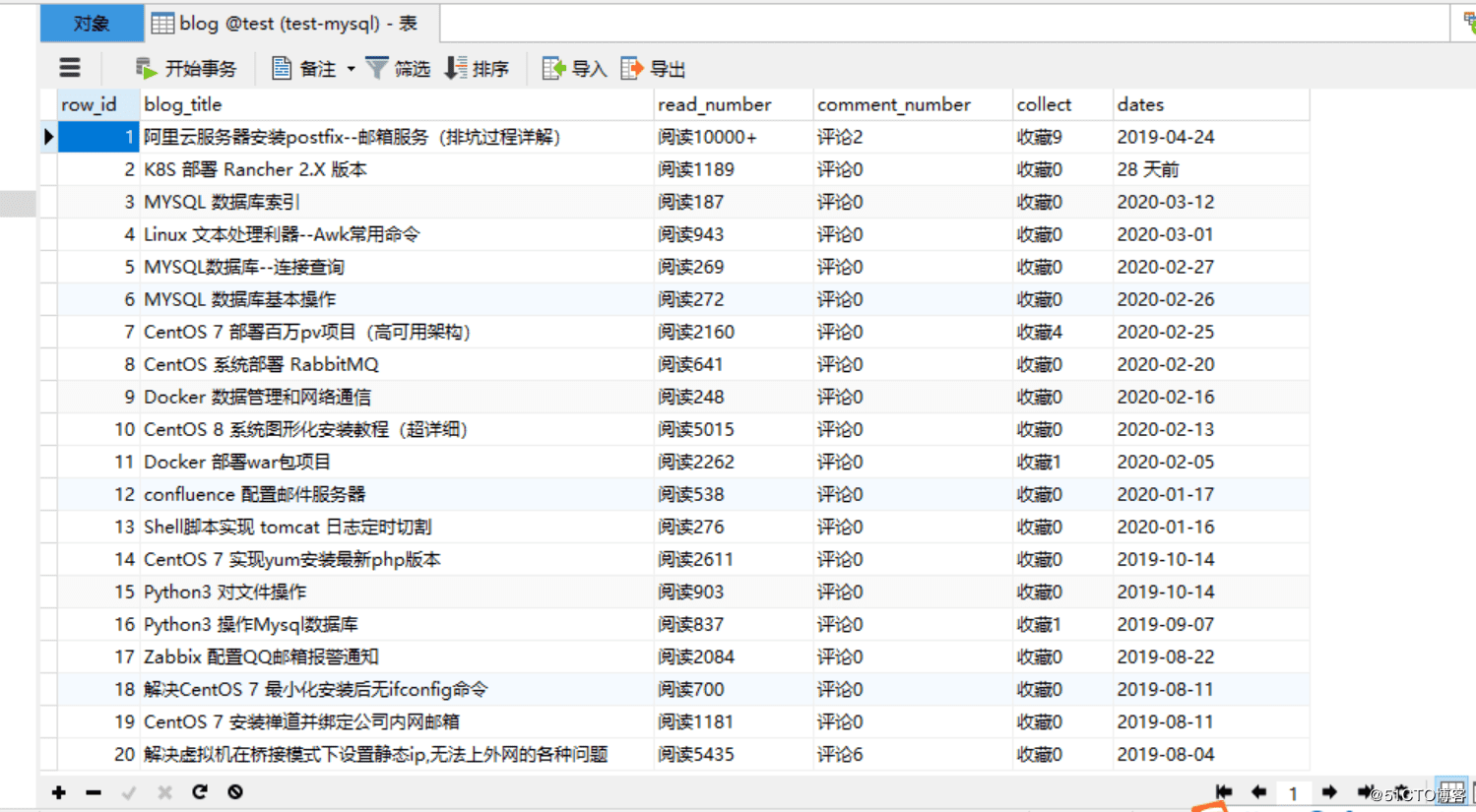
改進版:
改進內容:
1.數據庫里面的某些字段只保留數字即可
2.默認爬取的內容都是字符串,存放數據庫的某些字段,最好改為整型,方便后面數據庫操作
1.代碼如下:
import re
import bs4
import pymysql
import requests
# 連接數據庫
db = pymysql.connect(host='172.171.13.229',
user='root', passwd='abc123',
db='test', port=3306,
charset='utf8')
# 獲取游標
cursor = db.cursor()
def open_url(url):
# 連接模擬網頁訪問
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/57.0.2987.98 Safari/537.36'}
res = requests.get(url, headers=headers)
return res
# 爬取網頁內容
def find_text(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
# 博客標題
titles = []
targets = soup.find_all("a", class_="tit")
for each in targets:
each = each.text.strip()
if "置頂" in each:
each = each.split(' ')[0]
titles.append(each)
# 閱讀量
reads = []
read1 = soup.find_all("p", class_="read fl on")
read2 = soup.find_all("p", class_="read fl")
for each in read1:
reads.append(each.text)
for each in read2:
reads.append(each.text)
# 評論數
comment = []
targets = soup.find_all("p", class_='comment fl')
for each in targets:
comment.append(each.text)
# 收藏
collects = []
targets = soup.find_all("p", class_='collect fl')
for each in targets:
collects.append(each.text)
# 發布時間
dates=[]
targets = soup.find_all("a", class_='time fl')
for each in targets:
each = each.text.split(':')[1]
dates.append(each)
# 插入sql 語句
sql = """insert into blogs (blog_title,read_number,comment_number, collect, dates)
values( '%s', '%s', '%s', '%s', '%s');"""
# 替換頁面 \xa0
for titles, reads, comment, collects, dates in zip(titles, reads, comment, collects, dates):
reads = re.sub('\s', '', reads)
reads=int(re.sub('\D', "", reads)) #匹配數字,轉換為整型
comment = re.sub('\s', '', comment)
comment = int(re.sub('\D', "", comment)) #匹配數字,轉換為整型
collects = re.sub('\s', '', collects)
collects = int(re.sub('\D', "", collects)) #匹配數字,轉換為整型
dates = re.sub('\s', '', dates)
cursor.execute(sql % (titles, reads, comment, collects,dates))
db.commit()
pass
# 統計總頁數
def find_depth(res):
soup = bs4.BeautifulSoup(res.text, 'html.parser')
depth = soup.find('li', class_='next').previous_sibling.previous_sibling.text
return int(depth)
# 主函數
def main():
host = "https://blog.51cto.com/13760351"
res = open_url(host) # 打開首頁鏈接
depth = find_depth(res) # 獲取總頁數
# 爬取其他頁面信息
for i in range(1, depth + 1):
url = host + '/p' + str(i) # 完整鏈接
res = open_url(url) # 打開其他鏈接
find_text(res) # 爬取數據
# 關閉游標
cursor.close()
# 關閉數據庫連接
db.close()
#主程序入口
if __name__ == '__main__':
main()2.創建對應表
CREATE TABLE `blogs` ( `row_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵', `blog_title` varchar(52) DEFAULT NULL COMMENT '博客標題', `read_number` int(26) DEFAULT NULL COMMENT '閱讀數量', `comment_number` int(16) DEFAULT NULL COMMENT '評論數量', `collect` int(16) DEFAULT NULL COMMENT '收藏數量', `dates` varchar(16) DEFAULT NULL COMMENT '發布日期', PRIMARY KEY (`row_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
3.運行代碼,驗證
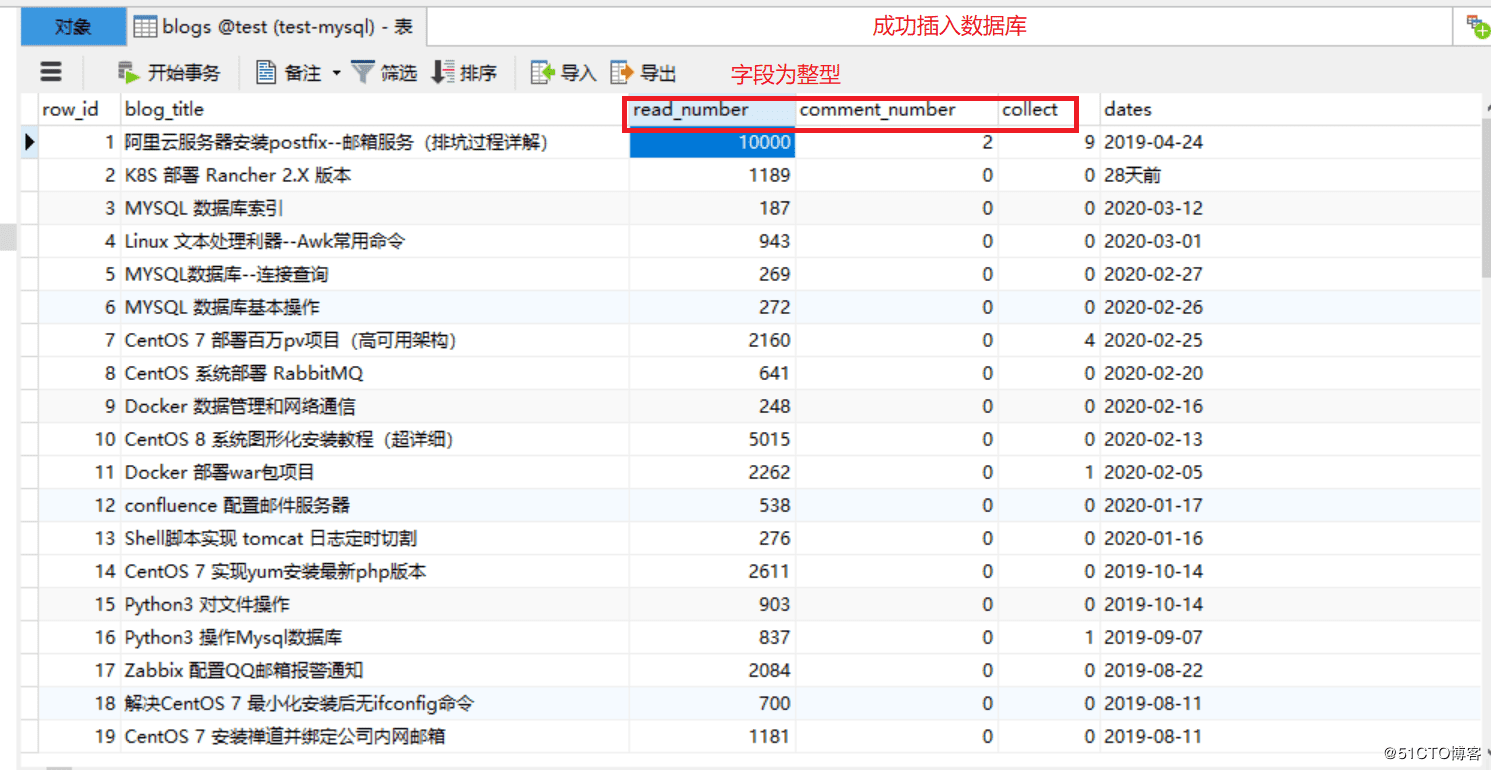
升級版
為了能讓小白就可以使用這個程序,可以把這個項目打包成exe格式的文件,讓其他人,使用電腦就可以運行代碼,這樣非常方便!
1.改進代碼:
#末尾修改為:
if __name__ == '__main__':
main()
print("\n\t\t所有數據已成功存放數據庫!!! \n")
time.sleep(5)2.安裝打包模塊pyinstaller(cmd安裝)
pip install pyinstaller -i https://pypi.tuna.tsinghua.edu.cn/simple/
3.Python代碼打包
1.切換到需要打包代碼的路徑下面
2.在cmd窗口運行 pyinstaller -F test03.py (test03為項目名稱)
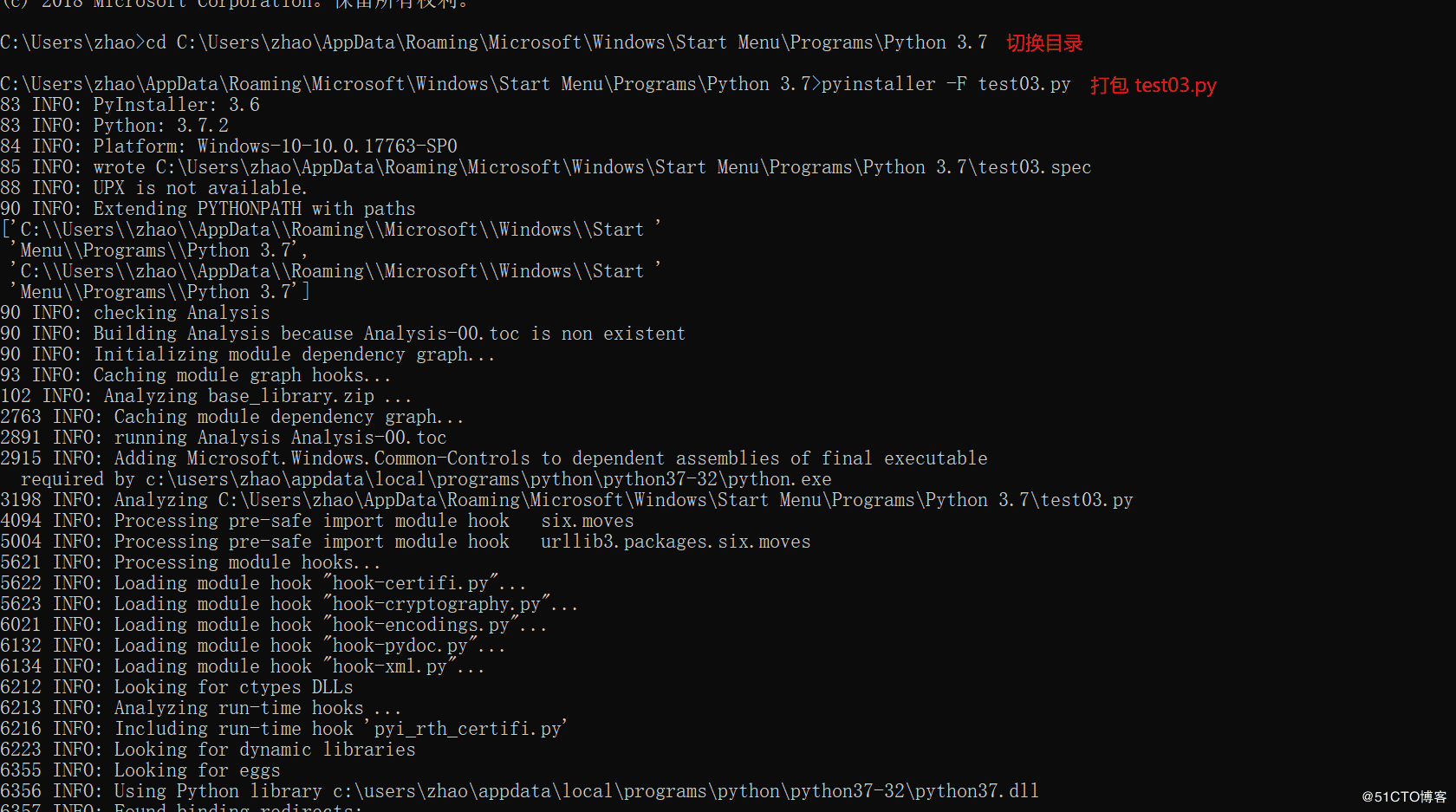
4.查看exe包
在打包后會出現dist目錄,打好包就在這個目錄里面

5.運行exe包,查看效果
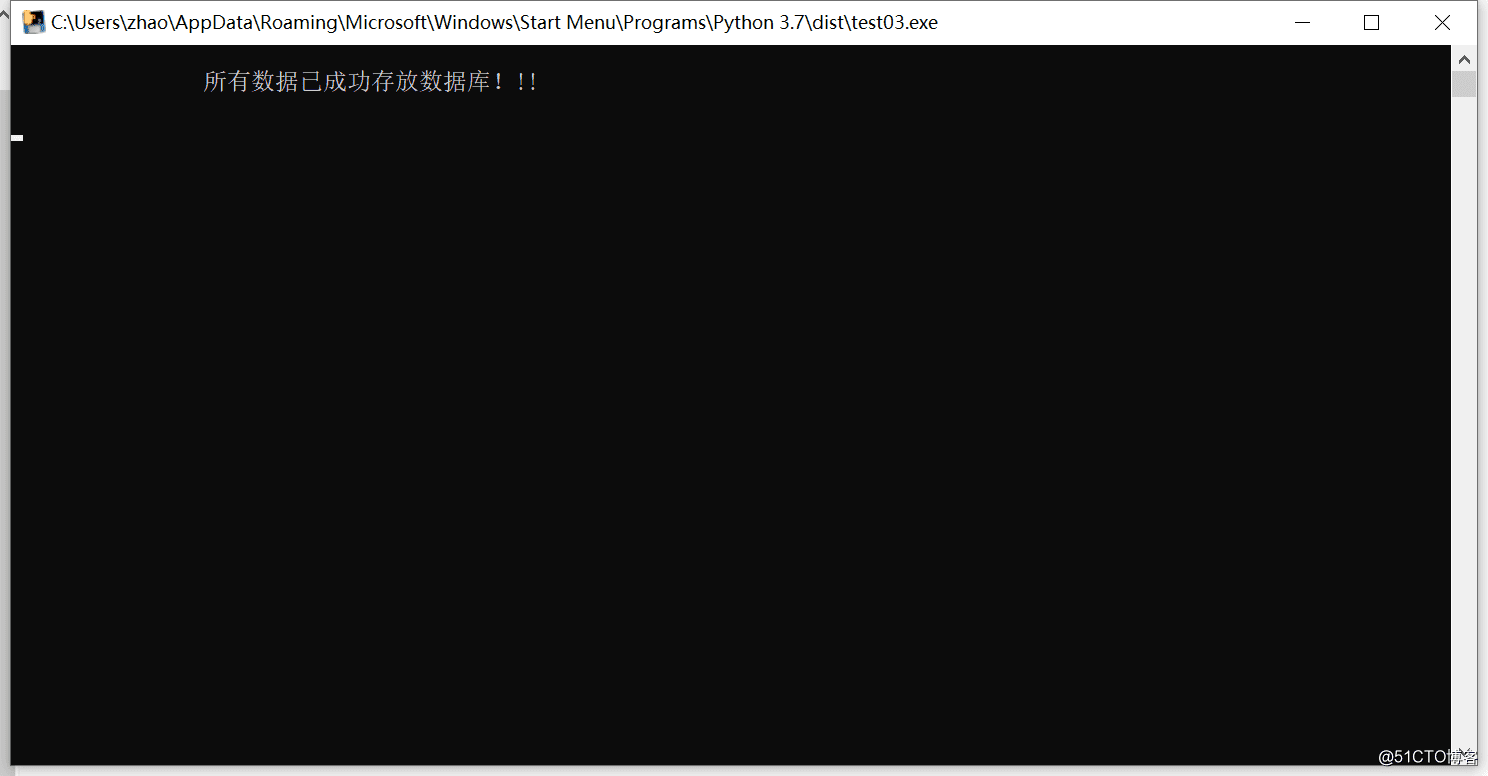
檢查數據庫
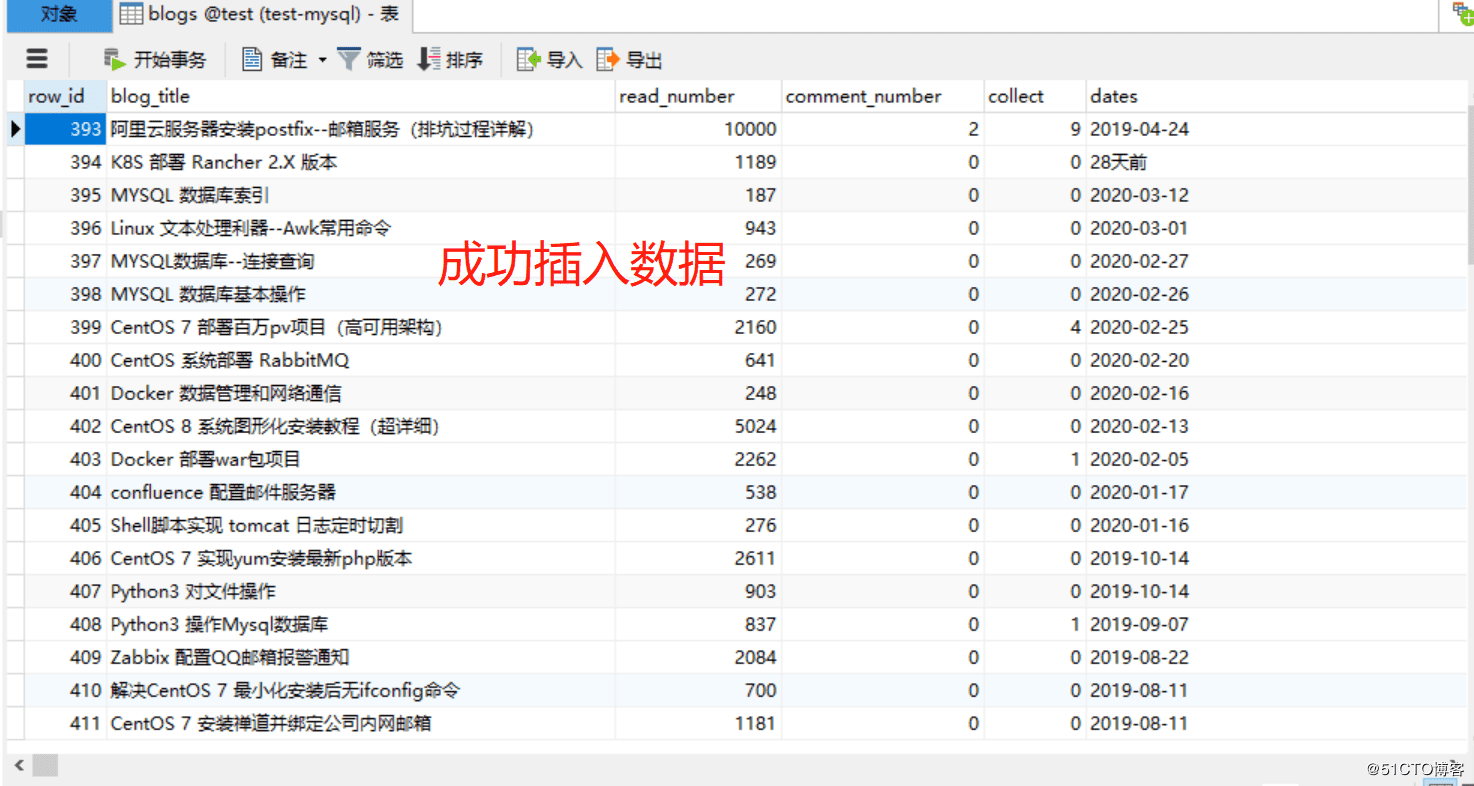
看完上述內容,你們對利用Python爬蟲實現爬取網站中的數據并存入MySQL數據庫中有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





