溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
作者:Artem Oppermann
這是關于自學習人工智能代理的多部分系列的第一篇文章,或者更準確地稱之為深度強化學習。本系列的目的不僅僅是讓你對這些主題有所了解。相反,我想讓你更深入地理解深度強化學習的最流行和最有效的方法背后的理論、數學和實施。
自學習人工智能代理系列 - 目錄
第一部分:馬爾可夫決策過程(本文)
第二部分:深度Q學習(Q-Learning)
第三部分:深入(雙重)Q學習(Q-Learning)
第四部分:持續行動空間的政策梯度
第五部分:決斗網絡(dueling network)
第六部分:異步角色評論代理
?...

圖1 人工智能學會如何運行和克服障礙馬爾可夫決策過程
目錄
0.簡介
1. Nutshell的增強學習
2.馬爾可夫決策過程
2.1馬爾可夫過程
2.2馬爾可夫獎勵程序
2.3價值函數?
3.貝爾曼方程(Bellman Equation)
3.1馬爾可夫獎勵過程的貝爾曼方程
3.2馬爾可夫決策過程 - 定義
3.3政策
3.4動作價值函數
3.5最優政策
3.6 貝爾曼方程最優性方程
0.簡介
深度強化學習正在興起。近年來,世界各地的研究人員和行業媒體都沒有更多關注深度學習的其他子領域。在深度學習方面取得的最大成就是由于深度的強化學習。來自谷歌公司的Alpha Go在圍棋游戲中擊敗了世界圍棋冠軍(這是幾年前不可能實現的成就),還有DeepMind的人工智能代理,他們自學走路、跑步和克服障礙(圖1-3) 。

圖2. 人工智能代理學會如何運行和克服障礙

圖3. 人工智能代理學會如何運行和克服障礙
其他人工智能代理自從2014年以來在玩雅達利游戲(Atari游戲)中的表現超過了人類水平(圖4)。在我看來,關于所有這一切的最令人驚奇的事實是,這些人工智能代理中沒有一個是由人類明確編程或教導如何解決這些任務。他們通過深度學習和強化學習的力量自學。多部分系列的第一篇文章的目標是提供必要的數學基礎,以便在即將發表的文章中解決人工智能這個子領域中最有希望的領域。
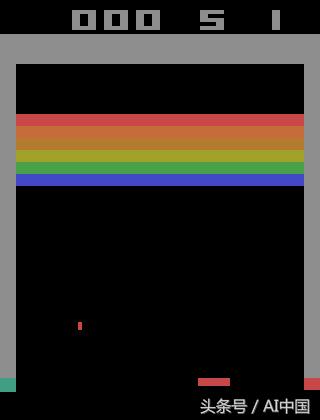
圖4 人工智能代理學習如何玩Atari游戲
1. 深度強化學習
深度強化學習可以概括為構建一個直接從與環境的交互中學習的算法(或人工智能代理)(圖5)。其環境可能是現實世界、計算機游戲、模擬甚至是棋盤游戲,如圍棋或國際象棋。與人類一樣,人工智能代理從其行為的后果中學習,而不是從明確的教導中學習。
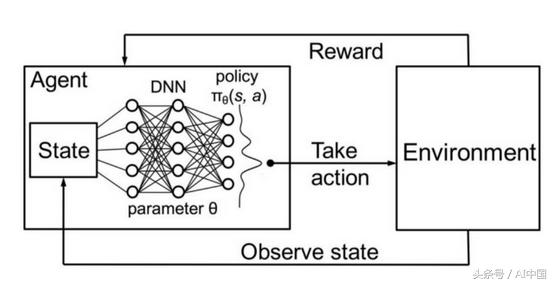
圖5深度強化學習的示意圖
在深度強化學習中,代理由神經網絡表示。神經網絡直接與環境相互作用。它觀察當前的環境狀況,并根據當前狀態和過去的經驗決定采取什么行動(例如向左、向右等)。基于所采取的行動,人工智能代理收到獎勵。獎勵金額決定了解決給定問題所采取行動的質量(例如學習如何行走)。代理的目標是學習在任何特定情況下采取行動,以最大化累積的獎勵。
2.馬爾可夫決策過程
馬爾可夫決策過程(MDP)是離散時間隨機控制過程。馬爾可夫決策過程(MDP)是我們迄今為止為人工智能代理的復雜環境建模的最佳方法。代理旨在解決的每個問題可以被認為是狀態序列S1,S2,S3,... Sn(狀態可以是例如圍棋/象棋板配置)。代理執行操作并從一個狀態移動到另一個狀態。在下文中,將學習確定代理在任何給定情況下必須采取的行動的數學。
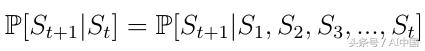
式1 馬可夫性質(Markov property)
2.1馬爾可夫過程
馬爾可夫過程是描述一系列可能狀態的隨機模型,其中當前狀態僅依賴于先前狀態。這也稱為馬可夫性質(Markov property)(式1)。對于強化學習,這意味著人工智能代理的下一個狀態僅取決于最后一個狀態,而不是之前的所有先前狀態。
馬爾可夫過程是一個隨機過程。這意味著從當前狀態s到下一個狀態s'的轉換只能以某個概率Pss'(式2)發生。在馬爾可夫過程中,被告知要離開的代理只會以一定的概率離開(例如0.998)。由可能性很小的環境來決定代理的最終結果。
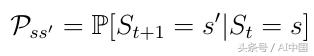
式2從狀態s到狀態s'的轉換概率
Pss'可以被認為是狀態轉移矩陣P中的條目,其定義從所有狀態s到所有后繼狀態s'(等式3)的轉移概率。
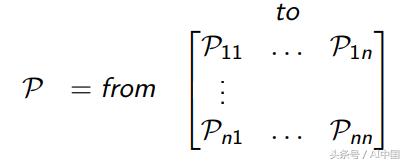
式3轉移概率矩陣
記住:馬爾可夫過程(或馬爾可夫鏈)是一個元組<S,P>。S是一組(有限的)狀態。 P是狀態轉移概率矩陣。
2.2馬爾可夫獎勵程序
馬爾可夫獎勵過程是元組<S,P,R>。這里R是代理希望在狀態s(式4)中獲得的獎勵。該過程的動機是,對于旨在實現某個目標的人工智能代理,例如贏得國際象棋比賽,某些狀態(比賽配置)在戰略和贏得比賽的潛力方面比其他狀態更有希望。
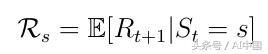
式4 狀態的預期獎勵
感興趣的主要話題是總獎勵Gt(式5),它是代理將在所有狀態的序列中獲得的預期累積獎勵。每個獎勵都由所謂的折扣因子γ∈[0,1]加權。折扣獎勵在數學上是方便的,因為它避免了循環馬爾可夫過程中的無限回報。除了折扣因素,意味著我們未來越多,獎勵變得越不重要,因為未來往往是不確定的。如果獎勵是金融獎勵,立即獎勵可能比延遲獎勵獲得更多利益。除了動物/人類行為表明喜歡立即獎勵。
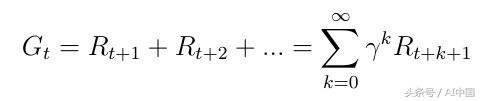
式5所有狀態的總獎勵
2.3價值函數
另一個重要的概念是價值函數v(s)之一。值函數將值映射到每個狀態s。狀態s的值被定義為人工智能代理在狀態s中開始其進展時將獲得的預期總獎勵(式6)。
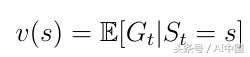
式6價值函數從狀態s開始的預期收益
價值函數可以分解為兩部分:
代理收到的即時獎勵R(t + 1)處于狀態s。
狀態s后的下一個狀態的折扣值v(s(t + 1))。
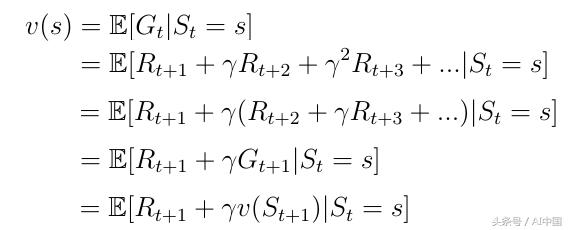
式7分解價值函數

3.貝爾曼方程
3.1馬爾可夫獎勵過程的貝爾曼方程
分解的值函數(式8)也稱為馬爾可夫獎勵過程的貝爾曼方程。該功能可以在節點圖中顯示(圖6)。從狀態s開始導致值v(s)。在狀態s中我們有一定的概率Pss'最終在下一個狀態s'中結束。在這種特殊情況下,我們有兩個可能的下一個狀態為了獲得值v(s),我們必須總結由概率Pss'加權的可能的下一個狀態的值v(s'),并從狀態s中添加即時獎勵。這產生了式9,如果我們在式中執行期望算子E,那么這只不是式8。
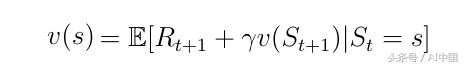
式8分解價值函數
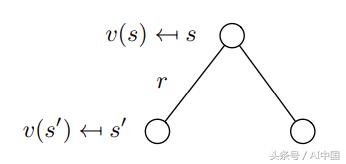
圖6從s到s'的隨機過渡
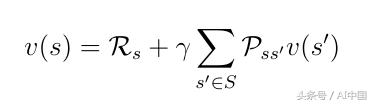
式9執行期望算子E后的貝爾曼方程
3.2馬爾可夫決策過程 - 定義
馬爾可夫決策過程是馬爾可夫獎勵過程的決策。馬爾可夫決策過程由一組元組<S,A,P,R>描述,A是代理可以在狀態s中采取的一組有限的可能動作。因此,現在處于狀態s中的直接獎勵也取決于代理在這種狀態下所采取的行動(等式10)。

式10 預期獎勵取決于狀態的行動
3.3政策
在這一點上,我們將討論代理如何決定在特定狀態下必須采取哪些行動。這由所謂的政策π(式11)決定。從數學角度講,政策是對給定狀態的所有行動的分配。策略確定從狀態s到代理必須采取的操作a的映射。
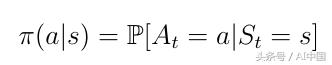
式11作為從s到a的映射的策略
在此記住,直觀地說,策略π可以被描述為代理根據當前狀態選擇某些動作的策略。
該策略導致狀態值函數v(s)的新定義(式12),我們現在將其定義為從狀態s開始的預期返回,然后遵循策略π。
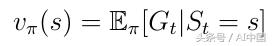
式12狀態價值函數
3.4動作價值函數
除狀態值函數之外的另一個重要功能是所謂的動作價值函數q(s,a)(式13)。動作價值函數是我們通過從狀態s開始,采取動作a然后遵循策略π獲得的預期回報。請注意,對于狀態s,q(s,a)可以采用多個值,因為代理可以在狀態s中執行多個操作。Q(s,a)的計算是通過神經網絡實現的。給定狀態作為輸入,網絡計算該狀態下每個可能動作的質量作為標量(圖7)。更高的質量意味著在給定目標方面采取更好的行動。
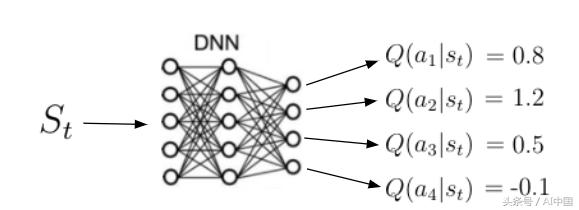
圖7動作價值函數的圖示
記住:動作價值函數告訴我們在特定狀態下采取特定行動有多好。
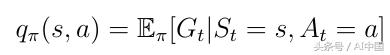
式13 動作價值函數
以前,狀態值函數v(s)可以分解為以下形式:
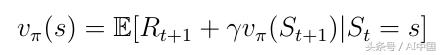
式14分解的狀態價值函數
相同的分解可以應用于動作價值函數:
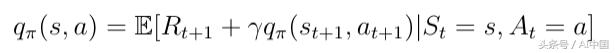
式15分解的狀態價值函數
在這一點上,我們討論v(s)和q(s,a)如何相互關聯。這些函數之間的關系可以在圖中再次可視化:
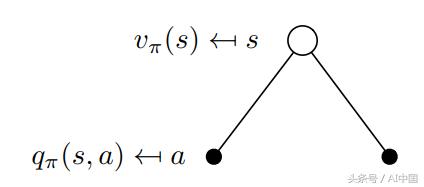
圖8 v(s)和q(s,a)之間關系的可視化
在這個例子中處于狀態s允許我們采取兩種可能的動作a。根據定義,在特定狀態下采取特定動作會給我們動作價值q(s,a)。動作價值函數v(s)是在狀態s(式16)中采取動作a的概率加權的可能q(s,a)的總和(其不是策略π除外)。
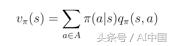
式16狀態價值函數作為動作價值的加權和

現在讓我們考慮圖9中的相反情況。二叉樹的根現在是一個我們選擇采取特定動作的狀態。請記住,馬爾可夫過程是隨機的。采取行動并不意味著你將以100%的確定性結束你想要的目標。嚴格地說,你必須考慮在采取行動后最終進入其他狀態的概率。在采取行動后的這種特殊情況下,你可以最終處于兩個不同的下一個狀態s':
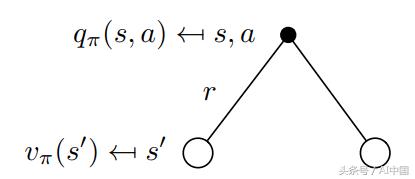
圖9 v(s)和q(s,a)之間關系的可視化
要獲得動作價值,你必須采用由概率Pss'加權的折扣狀態值,以最終處于所有可能的狀態(在這種情況下僅為2)并添加即時獎勵:
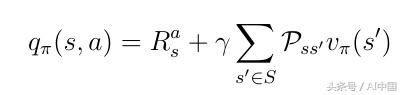
式17 q(s,a)和v(s)之間的關系
現在我們知道了這些函數之間的關系,我們可以從Eq中插入v(s)。從式16插入到式17的q(s,a),我們獲得了式18中,可以注意到,當前q(s,a)和下一個動作價值q(s',a')之間存在遞歸關系。
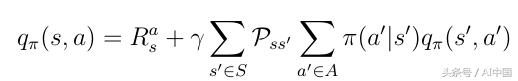
式18 動作價值函數的遞歸性質
這種遞歸關系可以再次在二叉樹中可視化(圖10)。我們從q(s,a)開始,以一定概率Pss'結束在下一個狀態s',我們可以用概率π采取動作a',我們以動作價值q結束(s',一個')。為了獲得q(s,a),我們必須在二叉樹中上升并整合所有概率,如式18所示。

圖10 q(s,a)的遞歸行為的可視化
3.5最優政策
深度強化學習中最重要的主題是找到最優的動作價值函數q *。查找q *表示代理確切地知道任何給定狀態下的動作的質量。此外,代理商可以決定必須采取哪種行動的質量。讓我們定義q *的意思。最佳的動作價值函數是遵循最大化動作價值的策略的函數:
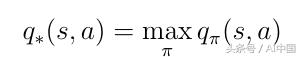
式19最佳行動價值函數的定義
為了找到最好的策略,我們必須在q(s,a)上最大化。最大化意味著我們只選擇q(s,a)具有最高價值的所有可能動作中的動作a。這為最優策略π產生以下定義:
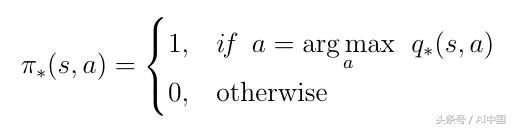
式19最佳行動價值函數的定義
3.6 貝爾曼最優性方程
可以將最優策略的條件插入到式中。式18因此為我們提供了貝爾曼最優性方程:
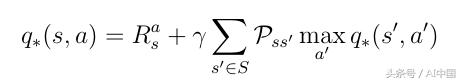
式21 貝爾曼最優性方程
如果人工智能代理可以解決這個等式,那么它基本上意味著解決了給定環境中的問題。代理在任何給定的狀態或情況下都知道關于目標的任何可能行動的質量并且可以相應地表現。
解決貝爾曼最優性方程將成為即將發表的文章的主題。在下面的文章中,我將向你介紹第一種解決深度Q-Learning方程的技術。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





