溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
概要:FireEye是通過AI提高測試效率,并降低AI自動化測試使用門檻的工具集,一經部署,就可以不用再修改腳本實現模型的使用和更新。本篇文章將具體介紹AI自動化測試過程中用到工程結構、模型選型和重訓練的技術細節等。
目前從功能上分為:頁面異常、控件異常、文本異常,測試結果頁面如下圖所示:

當測試同學發現部分測試出的數據并不符合預期,可以通過頁面標注并使用重訓練功能實時更新模型,不斷提高模型準確率,減少開發人員重新去介入模型的調整和部署。

工程結構如圖所示:
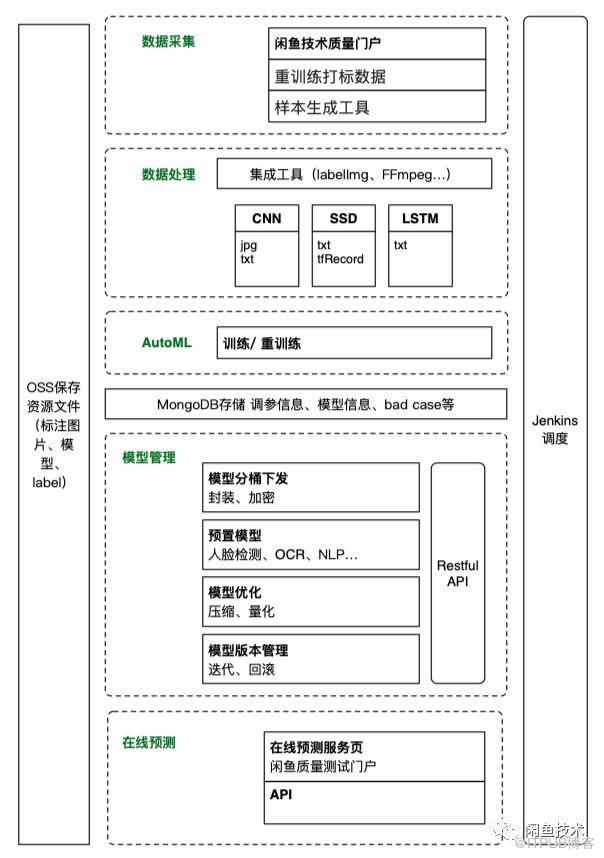
這個工程中,訓練數據的來源有3方面,樣本生成工具生成的模擬樣本、閑魚技術質量門戶持續搜集的真實用戶截屏圖片,還有一個是FireEye的前端頁面用戶手動打標的重訓練數據,數據采集之后,由集成的工具將其轉換為所需要的數據類型:JPG、PNG、TXT等,并將其中的資源文件上傳至OSS資源管理,當用戶觸發了重訓練命令,會由Jenkins通知服務端的重訓練腳本開始重新訓練,重訓練后的模型保存在云端,可以通過API提供給FireEye以及其他業務場景使用。
我們在針對不同的識別場景對模型的選型也有不同,其中
1, 頁面異常是檢測頁面是否整體空白或圖片中間有很大的錯誤提示圖片,因為這類異常結構簡單特征明顯,所以用CNN做聚類就可以準確區分出這一類的case。
2, 控件異常是找到頁面中有異常特征的控件,如識別截屏里面包含了圖片的打底圖,說明有圖片加載異常,識別出有loading控件,可能用戶在這個場景長時間卡住,識別出有error的HUD表示異常提示。我們在工程中選用SSD做物體檢測,原因是異常控件在一個頁面中可能存在多個,使用SSD模型可以識別出異常控件的類型以及在頁面的位置和異常的數量。
3, (具體介紹)文本異常檢測是通過OCR逐行識別出頁面中的文本,然后判斷文本的語義是否正常,模型部分選用的是LSTM,RNN的本質是一個數據推斷(inference)機器,它可以尋找兩個時間序列之間的關聯,只要數據足夠多,就可以得到從x(t)到y(t)的概率分布函數, 從而達到推斷和預測的目的,而LSTM(Long Short Term Memory Networks)長短時間記憶網絡,是RNN的一個變種,避免長期依賴和梯度消失,爆炸等問題,使得LSTM已經成為處理擁有長期依賴問題的序列數據問題的首要方法之一(語言模型、機器翻譯等領域)。
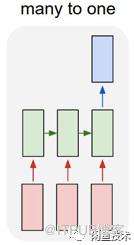
文本異常的處理是通過一句話判斷是否為異常文本,輸入是有時序的一串字符,輸出是否異常,符合RNN的5種架構中的many-to-one類型,這是我們選用LSTM的原因。
實際的檢測效果如下:
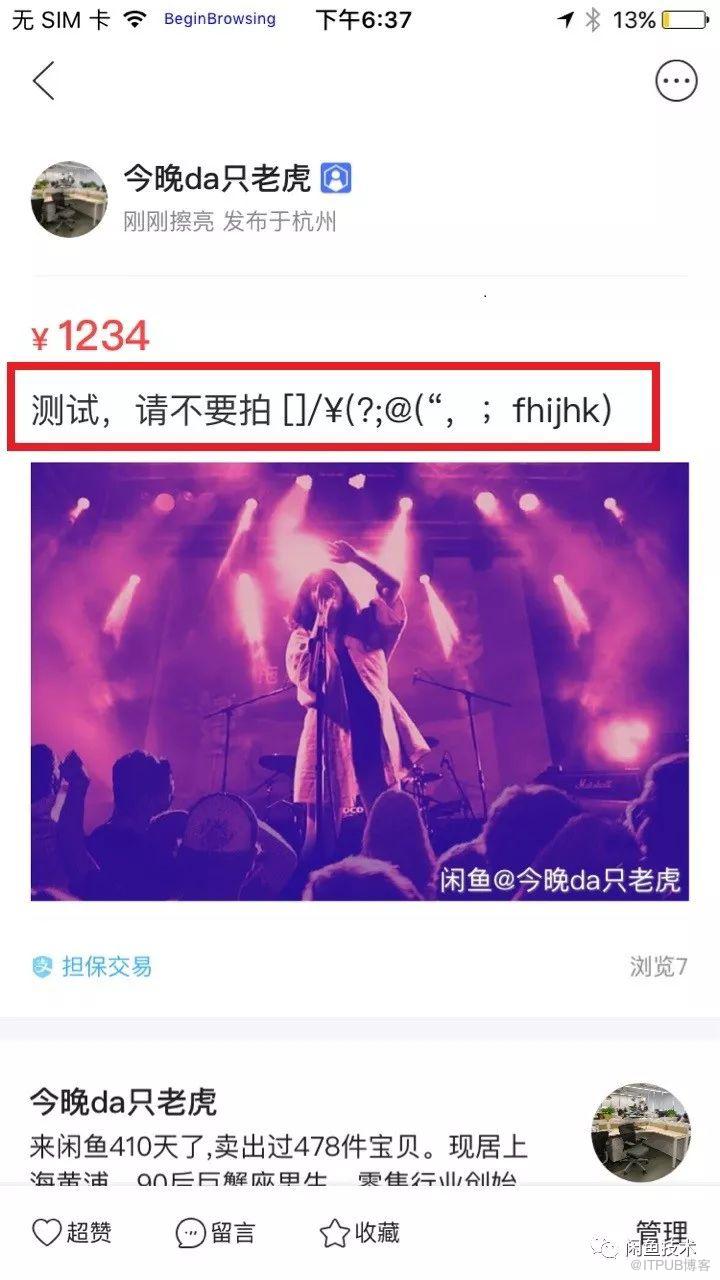
識別結果(其中第三行被識別出包含亂碼):

方案的實現上我們使用的是,Keras提供的LSTM層來構造網絡,然后構建以閑魚APP里的標題、詳情、評論等作為正樣本,口字碼、拼音碼、符號碼、錕拷碼、代碼等作為負樣本的訓練數據,使用nltk的分詞器分詞輸入訓練得到模型,通過OCR提取頁面文字輸入頁面識別輸入模型判斷。
部分代碼:
1,首先統計數據中有多少個不同的詞,每句話由多少個詞組成
maxlen = 0 #句子最大長度
word_freqs = collections.Counter() #詞頻
num_recs = 0 # 樣本數
with open('./train.txt','r+') as f:
for line in f:
label, sentence = line.strip().split("t")
words = nltk.word_tokenize(sentence.lower()
if len(words) > maxlen:
maxlen = len(words)
for word in words:
word_freqs[word] += 1
num_recs += 1目前項目里的亂碼識別主要是針對英文和字符類型,所以使用的是nltk庫做分詞,如果是主要對中文處理,使用結巴分詞效果更好,或者用NLTK庫中Sinica(中央研究院)提供的繁體中文語料庫,from nltk.corpus import sinica_treebank 這樣導入
2,建立兩個表,word2index和 index2word,用于單詞和數字轉換,把句子轉換成數字序列,長度統一到 MAXSENTENCELENGTH,不夠的填0,多出的截掉
MAX_FEATURES = 2000
MAX_SENTENCE_LENGTH = 40
vocab_size = min(MAX_FEATURES, len(word_freqs) + 2
word2index = {x[0]: i+2 for i, x in rate(word_freqs.most_common(MAX_FEATURES)}
word2index["PAD"] = 0
word2index["UNK"] = 1
index2word = {v:k for k, v in word2index.items()}
X = np.empty(num_recs,dtype=list)
y = np.zeros(num_recs)
i=0
with open('./train.txt','r+') as f:
for line in f:
label, sentence = line.strip().split("t")
words = nltk.word_tokenize(sentence.lower()
seqs = []
for word in words:
if word in word2index:
seqs.append(word2index[word])
else:
seqs.append(word2index["UNK"])
X[i] = seqs
y[i] = int(label)
i += 1
X = sequence.pad_sequences(X, maxlen=MAX_SENTENCE_LENGTH) ,
Xtrain, Xtest, ytrain, ytest = train_test_split(X, y, test_size=0.2, random_state=42)
EMBEDDING_SIZE = 128
HIDDEN_LAYER_SIZE = 643,模型訓練,損失函數用 binary_crossentropy,優化方法用 adam,最后導出h6模型。
model = Sequential()
model.add(Embedding(vocab_size, EMBEDDING_SIZE,input_length=MAX_SENTENCE_LENGTH)
model.add(LSTM(HIDDEN_LAYER_SIZE, dropout=0.2, recurrent_dropout=0.2)
model.add(Dense(1)
model.add(Activation("sigmoid")
model.compile(loss="binary_crossentropy", optimizer="adam",metrics=["accuracy"])
BATCH_SIZE = 32
NUM_EPOCHS = 10
model.fit(Xtrain, ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS,validation_data=(Xtest, ytest)
model.save("garbled.h6");"4,OCR識別頁面文字內容,導入模型中進行預測。(目前使用是谷歌OCR,中文識別的精度還不夠)
在工程開始初期從真實用戶收集的數據很少,需要大量的樣本提供訓練,為了能大量生成訓練和測試樣本并且不影響APP的線上統計數據,開發了一個通用的native的mock庫可以截取控件加載數據隨機生成mock的數據,用來配合Facebook-WDA截取圖片獲得樣本: 1,mock所有UIImage,隨機加載1萬個樣本數據里的圖片url;
2,mock所有UILabel和UITextField,隨機從樣本庫中生成語句和數字,內容數與原有數據相仿;
3,通過Facebook-WDA工具腳本控制APP,隨機點擊進入不同頁面,滑動,截圖,判斷是否到底部,再隨機跳轉到別的頁面…這樣來獲得大量樣本;
打標一直以來是使用AI困擾大家的一件耗時耗力的步驟,FireEye提供重訓練功能的同時提供了相關工具:
其中頁面異常的識別的CNN模型和識別文本異常的LSTM模型重訓練,可以通過用戶在網頁上的對結果進行勾選,輸入正確的結果來完成標注工作,操作比較簡單,最復雜繁瑣的是SSD模型的打標,普遍的做法是使用labelImg工具,先準確的框選目標物體輸入標簽名,然后導出包含物體位置和標簽信息的CSV文件,FireEye將這個功能集成到了重訓練的系統中,用戶可以通過在頁面上劃線或者畫框標出物體大致的位置,位置會傳到后端腳本自動裁剪提取前景,得到更精準的物體實際定位并生成CSV文件,其中畫框標記的具體實現如下:
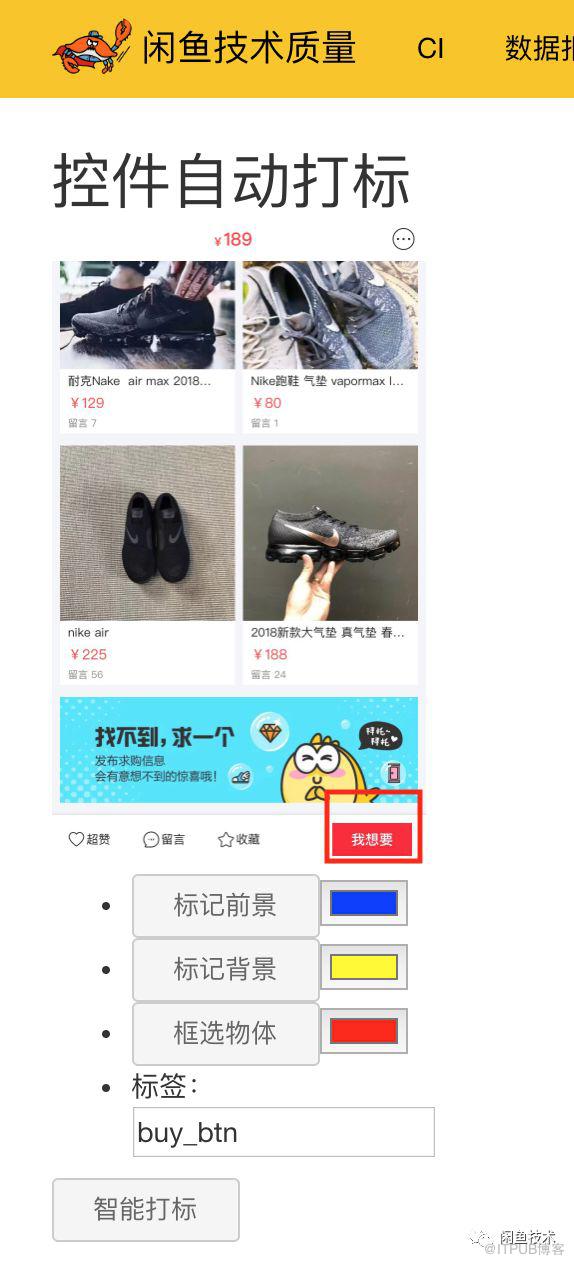
1,前端頁面打標
下圖是使用框選物體來標記右下角的按鈕,我們不需要框出準確的位置:
2,調用Python腳本,使用OpenCV的grabcut來實現前景提取
img=cv2.imread('tmp2.png')
mask=np.zeros((img.shape[:2]),np.uint8)
bgdModel=np.zeros((1,65),np.float64)
fgdModel=np.zeros((1,65),np.float64)
cv2.grabCut(img,mask,rect,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_RECT)
mask2=np.where((mask==2)|(mask==0),0,1).astype('uint8')下圖是grabcut提取前景后識別出的mask圖,右下角有部分裁剪后留下的雜點

3,得到前景二值化,查找連通區域,找到最大面積,通過把小面積區域用fillConvexPoly方法填充覆蓋,得到
img=img*mask2[:,:,np.newaxis] gray_temp = mask2.copy() #copy the gray image because function binary, contours, hierarchy = cv2.findContours(gray_temp, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE) cv2.drawContours(img, contours, -1, (0, 255, 255), 2) area = [] for i in xrange(len(contours)): area.append(cv2.contourArea(contours[i])) max_idx = np.argmax(area) for i in xrange(len(contours)): if i != max_idx: cv2.fillConvexPoly(mask2, contours[i], 0)

4,再獲得外接矩形,得到準確的標記位置并輸出CSV文件。
FireEye目標是打造一個精簡易用的自動化測試工具集,可以很方便快捷的部署和調整,后面工程的重心會是AutoML的模型自動調參,識別布局異常,以及通過頁面元素(控件、文本等)的綜合分析,區分業務場景,理解用戶操作路徑是否正確等方面,歡迎有興趣的小伙伴一起探討學習。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





