溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

本周熱門學術研究
對于機器人應用來說,回答目標是什么以及目標在哪這一問題,并提供一種空間和語義不確定性的衡量標準,是目標檢測需要優先解決的問題。
日前,由Google支持的澳大利亞研究委員會旗下的機器人卓越視覺中心開啟了第一場關于概率目標檢測的挑戰賽。計算機和機器人視覺的挑戰要求參與者檢測視頻數據中的對象,并提供空間和語義不確定性的準確估計。

圖1:示例圖片來自用來產生挑戰測試數據的模擬環境,第一排和左下圖是用于測試序列的環境,右下圖是用于驗證序列。
這場挑戰沒有設置門檻,人工智能社區中對目標檢測有興趣的人都可以參加,這是一場很不錯的挑戰。挑戰的測試數據集包含來自18個模擬室內視頻序列中的56,000多張圖像,將在用于挑戰的公共服務器中進行評估,該服務器僅在公開比賽階段開放。參與者將獲得名次并共享5000澳元獎金。
這一新的挑戰是對概率目標檢測的介紹,將現有的目標檢測任務提升到高端機器人應用中的空間和語義不確定性。總的來說,它將提高機器人應用在物體檢測方面的技術水平。
更多細節:
https://nikosuenderhauf.github.io/roboticvisionchallenges/object-detection
原文:
https://arxiv.org/abs/1903.07840
研究人員設計了一種系統,該系統可以使用單個輸入圖像從期望的視點為特定對象生成一組圖像,供移動操作機器人使用。
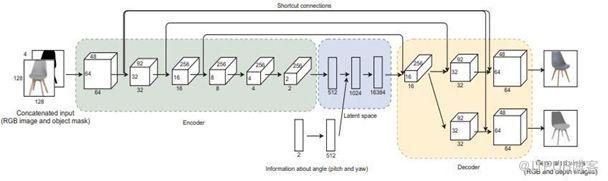
所提出的方法是一種深層神經網絡,訓練它從多個視角“想象”物體的外觀。它將對象的單個RGB圖像作為輸入,并返回一組RGB和深度圖像(位深度圖像),從而消除了傳統、耗時的掃描。
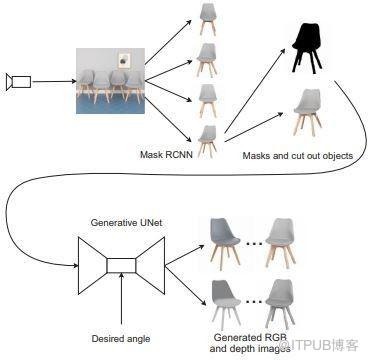
雖然深層神經網絡已經實現了單視角重建,但由于重建過程計算量大,很難直接獲得重建對象的精準細節。該方法采用基于CNN模型的目標檢測器從自然環境中提取目標,由神經網絡生成一組RGB和深度圖像(位深度圖像,目前Ps軟件中的位深度為16位)。該方法已在生成圖像和真實圖像上進行了測試,證明其是非常有效的。
基于圖像生成具有為重建物體提供更好的空間分辨率的潛力。因此,該方法在移動操作機器人領域中是有必要的。這種方法有可能幫助機器人更好地理解一個物體的空間屬性,而不需要做一個完整的掃描。
原文:
https://arxiv.org/abs/1903.06814
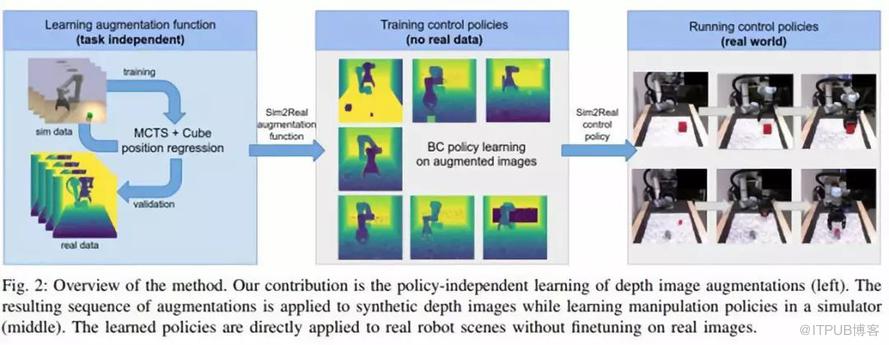
由于實際數據和合成數據之間存在著領域差距,而且很難將在模擬器中學習到的策略傳輸到真實場景中。在過去,領域隨機化(隨機領域數據生成,domain randomization)通過使用隨機變換(如隨機對象形狀和紋理)增強合成數據來解決這一挑戰。
近年來,研究人員對領域隨機化的研究做出了新的貢獻,對Sim2Real遷移的增強技術進行了優化,使其能夠在沒有真實圖像的情況下實現與領域無關的策略學習。
他們設計了一種利用目標定位進行深度圖像增強的高效搜索方法。在策略學習過程中,利用生成的隨機變換序列來增強合成深度圖像。
為了評估這種遷移的程度,研究人員提出了一種目標位置估計的委托任務,這種任務只需要很少的真實數據。新方法大大提高了在真實機器人上評估操作任務的準確性。
該方法在模擬環境中促進了操作策略的有效學習。這是非常有益的,因為模擬器可以促進可伸縮性,并在模型訓練期間提供對底層空間的訪問。此外,新的方法不需要真實圖像來實現策略學習,可以應用于各種操作任務。
原文:
https://arxiv.org/abs/1903.07740
研究人員提出了一種DC-SPP-YOLO方法來提高YOLOv2目標的檢測精度。DC-SPP方法通過優化基礎網絡的連接結構來改進YOLOv2,并引入了多尺度局部區域特征提取。因此,這個提出的新方法比YOLOv2更精確。
它達到了接近YOLOv2的目標檢測速度,并且比傳統的目標檢測方法如反卷積單鏡頭檢測器(DSSD)、標度可轉移檢測網絡(STDN)和YOLOv3更高。
DC-SPP-YOLO特別利用YOLOv2基礎網絡中卷積層的連接來加強特征提取,使消失梯度問題最小化。在此基礎上,提出了一種改進的空間金字塔池,并將多尺度局部區域特征串聯起來,使網絡能夠更全面地學習目標特征。
基于一種新的損失函數訓練DC-SPP-YOLO模型,該損失函數由均方誤差和交叉熵組成,能更準確地實現目標檢測。實驗結果表明,DC-SPP-YOLO在PASCAL VOC和UA-DETRAC數據集上的mAP均大于YOLOv2。
潛在用途及影響
通過加強特征提取,利用多尺度局部區域特征,DC-SPP-YOLO實現了優于YOLOv2的實時目標檢測精度。在安全監控、醫療診斷、自動駕駛等方面,該方法可用于實現更精確的、最先進的計算機視覺應用。
詳情請見:
https://arxiv.org/abs/1903.08589
最近的研究提出了一種“智能”的深度學習半自動分割方法,能夠在醫學圖像中對感興趣的區域進行交互描述。這種提出的方法采用了一種FCNN的架構來執行交互式二維醫學圖像分割。
那么它是如何使用交互的?網絡被訓練成每次只分割一個感興趣的區域,并考慮到用戶以單擊一次或多次鼠標的形式輸入的內容。該模型還被訓練去使用原始2D圖像和一個“引導信號”作為輸入。然后它會輸出特定分割對象的二進制掩碼。研究人員已經證明了它可以被用于在腹部CT中分割各種器官。這種新方法提供了非常準確的結果,可以根據用戶的選擇以快速、智能和自發的方式進行糾正。
潛在用途及影響
該方法可以快速地提供高端的二維分割結果。它也有潛力解決緊迫的臨床挑戰,并可用于提高分割精度的眾多醫學成像應用,如腫瘤定位、手術規劃、診斷、手術內導航、虛擬手術模擬、組織體積測量等。其他應用包括可視化、放射治療規劃、3D打印、圖像分類、自然語言處理等等。
原文:
https://arxiv.org/abs/1903.08205
其他爆款論文
利用3D點云增強可穿戴機器人的環境分類。
原文:
https://arxiv.org/abs/1903.06846v1
用于道路駕駛圖像實時語義分割的預訓練模型。
原文:
https://arxiv.org/abs/1903.08469
第一種基于事件的運動分割數據集學習方法和事件相機的學習管道。
原文:
https://arxiv.org/abs/1903.07520
即插即用的磁共振成像(MRI)。
原文:
https://arxiv.org/abs/1903.08616
AI新聞
谷歌在德國作曲家巴赫生日當天發布了AI涂鴉來紀念他。
詳情請見:First ever AI doodle that allows users to make music.
https://www.newsweek.com/google-doodle-bach-birthday-when-march-21-22-1366826
結合計算密集型的人工智能應用程序和最近發布的新人工智能服務器。
詳情請見:AI Server Enabled with NVIDIA GPUs for edge computing
https://www.marketwatch.com/press-release/inspur-releases-edge-computing-ai-server-enabled-with-nvidia-gpus-2019-03-19?mod=mw_quote_news
真的有可能創造出類似人類的人工智能嗎?
詳情請見:How to create AI that is more human

Christopher Dossman是Wonder Technologies的首席數據科學家,在北京生活5年。他是深度學習系統部署方面的專家,在開發新的AI產品方面擁有豐富的經驗。除了卓越的工程經驗,他還教授了1000名學生了解深度學習基礎。
LinkedIn:
https://www.linkedin.com/in/christopherdossman/
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





