溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

集智導讀:
本文會為大家展示機器學習專家 Mike Shi 如何用 50 行 Python 代碼創建一個 AI,使用增強學習技術,玩耍一個保持桿子平衡的小游戲。所用環境為標準的 OpenAI Gym,只使用 Numpy 來創建 agent。
各位看官好,我(作者 Mike Shi——譯者注)將在本文教大家如何用 50 行 Python 代碼,教會 AI 玩一個簡單的平衡游戲。我們會用到標準的 OpenAI Gym 作為測試環境,僅用 Numpy 創建我們的 AI,別的不用。
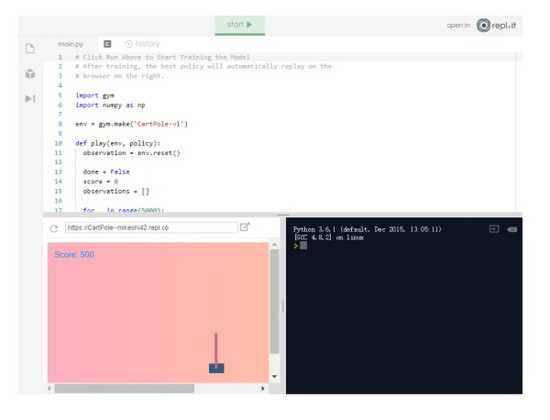
這個小游戲就是經典的 Cart Pole 任務,它是 OpenAI Gym 中一個經典的傳統增強學習任務。游戲玩法如下方動圖所示,就是盡力保持這根桿子始終豎直向上。桿子由于重力原因,會出現傾斜,到了一定程度就會倒下,AI 的任務就是在此時向左或向右移動桿子,不讓它倒下。這就跟我們在手指尖上樹立一支鉛筆玩“金雞獨立”一樣,只不過我們這里是個一維的簡單游戲(但是還是很有挑戰性的)。
你可能好奇最終實現怎樣的結果,可以在repl.it 上查看 demo:
https:// repl.it/@MikeShi42/Cart Pole
增強學習速覽
如果這是你第一次接觸機器學習或增強學習,別擔心,我下面介紹一些基礎知識,這樣你就可以了解本文使用的術語了:)。如果已經熟悉了,大可跳過這部分,直接看看編寫 AI 的部分。
增強學習(RL)是一個研究領域:教 agent(我們的算法/機器)執行某些任務/動作,但明確告訴它該怎樣做。把它想象成一個嬰兒,以隨機的方式伸腿,如果寶寶偶然間走運站立起來,我們會給它一個糖果作為獎勵。同樣,Agent 的目標就是在其生命周期內得到最多的獎勵,而且我們會根據是否和要完成的任務相符來決定獎勵的類型。對于嬰兒站立的例子,站立時獎勵 1,否則為0。
增強學習 agent 的一個著名例子是 AlphaGo,其中的 agent 已經學會了如何玩圍棋以最大化其獎勵(贏得游戲)。在本教程中,我們將創建一個 agent,或者說 AI,可以向左或向右移動小車,讓桿子保持平衡。
狀態
狀態是目前游戲的樣子。我們通常處理游戲的多種數字表示。在乒乓球比賽中,它可能是每個球拍的垂直位置和 x,y 坐標和球的速度。在我們這個游戲中,我們的狀態由 4 個數字組成:底部小車的位置,小車的速度,桿的位置(以角度表示)和桿的角速度。這 4 個數字都是給定的數組(或向量)。這個很重要,理解狀態是一個數字數組意味著我們可以對它進行一些數學運算來決定我們根據狀態采取什么行動。

策略
策略是一種函數,其輸入是游戲的狀態(例如棋盤的位置,或小車和桿的位置),輸出 agent應該在該位置采取的動作(例如,將小車向左邊移動)。在 agent 采取我們選擇的操作后,游戲將使用下一個狀態進行更新,我們會再次將其納入策略以做出決策。這種情況一直持續到游戲結束。策略非常重要,也是我們一直追求的,因為代表了 agent 背后的決策能力。
點積
兩個數組(向量)之間的點積簡單地將第一個數組的每個元素乘以第二個數組的對應元素,并將它們全部加在一起。假設我們想找到數組 A 和 B 的點積,只需計算是 A [0] * B [0] + A [1] * B [1] ......我們將使用這種運算將狀態(一個數組)乘以另一個數組(我們的策略)。
創建我們的策略
為了完成這個推車平衡游戲,我們希望讓我們的 agent(或者說 AI)學習策略贏得比賽或獲得最大獎勵。
對于我們今天要開發的 agent,我們將策略表示為 4 個數字的數組,分別代表狀態的各個部分的“重要性”(小車位置,桿子的位置等)然后我們會計算狀態和策略數組的點積,得到一個數字。根據數字是正數還是負數,我們將向左或向右推動小車。
如果這聽起來有點抽象,那么我們選擇一個具體的例子,看看會發生什么。
假設小車在游戲中居中并且靜止,桿子向右傾斜且可能倒向右邊。它看起來像這樣:

相關狀態可能如下所示:
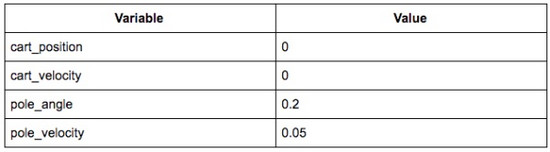
那么狀態數組將是 [0,0,0.2,0.05]。
從直覺上,我們要把小車推向右邊,將支桿拉直。我從訓練中得到了一個很好的策略,其策略數據如下:[ - 0.116,0.332,0.207 0.352]。我們快速計算一下,看看該策略會輸出怎樣的動作。
這里,我們將狀態數組 [0,0,0.2,0.05] 和上述策略數組結合計算點積。如果數字是正數,我們將車推向右邊,如果數字是負數,我們向左推。

結果為正,意味著策略會向右推動小車,符合我們的預期。
現在比較明顯了,我們需要 4 個像上面這樣的神奇數字來幫我們解決問題。那么我們該如何獲得這些數字?如果我們只是隨機挑選它們會怎樣?AI 的效果會怎樣?我們來一起看代碼!
啟動你的編輯器!
首先在repl.it 上打開一個 Python 實例。Repl.it 能讓我們快速啟動大量不同編程環境的云實例,并在任何地方都能訪問的強大云 IDE 中編輯代碼!

安裝軟件包
我們首先安裝這個項目所需的兩個軟件包:numpy 幫助進行數值計算;OpenAI Gym 作為我們代理的模擬器。
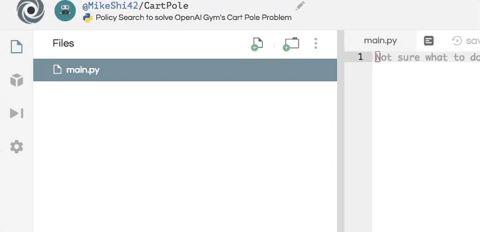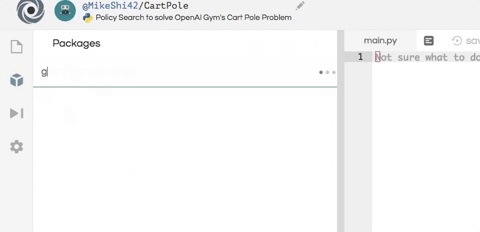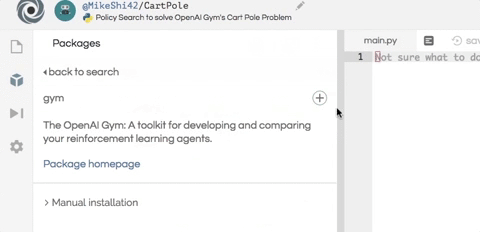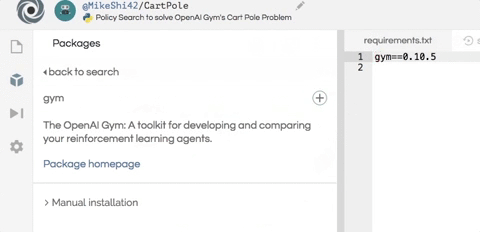
只需在編輯器左側的包搜索工具中輸入 gym 和 numpy,然后單擊加號按鈕即可安裝包。
創建基礎框架
我們首先將我們剛剛安裝的兩個依賴項導入到main.py 腳本中,并設置一個新的 gym 環境:
import gymimport numpy as npenv = gym.make('CartPole-v1')
接下來,我們定義一個名為“play”的函數,為該函數提供一個環境和一個策略數組,在環境中計算策略數組并返回分數,以及每個時步的游戲快照(用于觀察)。我們將使用分數來判斷策略的效果以及查看每個時步的游戲快照來判斷策略的表現。這樣我們就可以測試不同的策略,看看它們在游戲中的表現如何!
首先我們理解函數的定義,然后將游戲重置為開始狀態。
def play(env, policy): observation = env.reset()
接下來,我們將初始化一些變量以跟蹤游戲是否已經結束,包括策略的總分以及游戲中每個步驟的快照(供觀察)。
done = False score = 0 observations = []
現在我們多次運行游戲,直到 gym 告訴我們游戲已經完成。
for _ in range(5000): observations += [observation.tolist()] # 記錄用于正則化的觀察值,并回放 if done: # 如果模擬在最后一次迭代中結束,則退出循環 break # 根據策略矩陣選擇一種行為 outcome = np.dot(policy, observation) action = 1 if outcome > 0 else 0 # 創建行為,記錄反饋 observation, reward, done, info = env.step(action) score += reward return score, observations
上面的大部分代碼主要是玩游戲的過程以及記錄的結果。實際上,我們的策略代碼只需要兩行:
outcome = np.dot(policy, observation) action = 1 if outcome > 0 else 0
我們在這里所做的只是策略數組和狀態數組之間的點積運算,就像我們之前在具體例子中所示的那樣。然后我們根據結果是正還是負,選擇 1 或 0(左或右)的動作。
到目前為止,我們的main.py 應如下所示:
import gymimport numpy as npenv = gym.make('CartPole-v1')def play(env, policy):
observation = env.reset()
done = False score = 0
observations = [] for _ in range(5000):
observations += [observation.tolist()]
# 如果模擬在最后一次迭代中結束,則退出循環
if done: # 如果模擬在最后一次迭代中結束,則退出循環 break
# 根據策略矩陣選擇一種行為
outcome = np.dot(policy, observation)
action = 1 if outcome > 0 else 0
# 創建行為,記錄反饋
observation, reward, done, info = env.step(action)
score += reward
return score, observations
現在,我們開始玩游戲,尋找我們的最佳策略!
第一局游戲
由于我們有了能夠玩游戲的函數,并且能告訴我們的策略有多好,那么下面就創建一些策略,看看它們的效果怎樣。
如果我們首先只想嘗試隨機策略呢?能達到怎樣的效果?我們使用 numpy 來生成我們的策略,它是一個 4 元素數組或 1x4 矩陣。它會選擇 0 到 1 之間的 4 個數字作為我們的策略。
policy = np.random.rand(1,4)
根據該策略和我們上面創建的環境,我們可以用它們來玩游戲,獲得一個分數。
score, observations = play(env, policy)print('Policy Score', score)
點擊運行,執行我們的腳本,然后會輸出我們的策略得分:
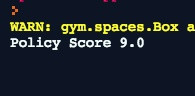
游戲的最大得分是 500 分,你的策略有可能達不到這個水平。如果達到了,恭喜你!絕對是你的大日子!只是看一個數字并沒有特別大的意義。如果能看到我們的 agent 是如何玩游戲的,那就太好了,下一步我們就會設置它!
查看我們的agent
要查看我們的 agent,我們會使用 Flask 設置一個輕量級服務器,以便我們可以在瀏覽器中查看代理的性能。Flask 是一個輕量級的 Python HTTP 服務器框架,可以為我們的 HTML UI 和數據伺服。這部分我就一筆帶過了,因為渲染和 HTTP 服務器背后的細節對訓練我們的 agent 并不重要。
我們首先將 Flask 安裝為 Python 包,就像我們在前面安裝 gym 和 Numpy 一樣。
接著,在我們腳本的底部,我們將創建一個 Flask 服務器。它將在端點 / data 上顯示游戲的每一幀的記錄,并在/上托管UI。
from flask import Flaskimport jsonapp = Flask(__name__, static_folder='.')@app.route("/data")def data():
return json.dumps(observations)@app.route('/')def root():
return app.send_static_file('./index.html')
app.run(host='0.0.0.0', port='3000')
另外,我們需要添加兩個文件。一個是項目的空白 Python 文件。這是repl.it 如何檢測 repl 是處于 eval 模式還是項目模式的專用術語。只需使用新文件按鈕添加空白 Python 腳本即可。
之后我們還想創建一個用于渲染 UI 的 index.html。這里不再深入講解,只需將此 index.html 上傳到你的repl.it 項目即可。
現在你應該有一個如下所示的項目目錄:
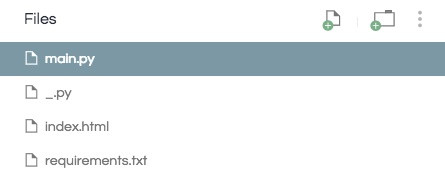
現在有了這兩個新文件,當我們運行 repl 時,它應該能演示我們的策略。有了這個,我們嘗試找到最佳策略!

策略搜索
在我們的第一局游戲中,我們只是隨機選擇了一個策略,但是如果我們選擇了一批策略,并且只保留那個表現最好的策略呢?
我們回到發布策略的部分,這次不是僅生成一個,而是編寫一個循環來生成多個策略,并跟蹤每個策略的執行情況,最終僅保存最佳策略。
首先我們創建一個名為 max 的元組,它將存儲我們迄今為止看到的最佳策略的得分,觀察值和策略數組。
max = (0, [], [])
接著我們會生成和評估 10 個策略,并將最優策略保存在 max 中。
for _ in range(10):
policy = np.random.rand(1,4)
score, observations = play(env, policy)
if score > max[0]:
max = (score, observations, policy)print('Max Score', max[0])
我們還要讓 /data 端點返回最優策略的回放。
該端點:
@app.route("/data")def data():return json.dumps(observations)
應該改為:
@app.route("/data")def data():return json.dumps(max[1])
你的main.py 應該如下所示:
import gymimport numpy as npenv = gym.make('CartPole-v1')def play(env, policy):
observation = env.reset() done = False score = 0
observations = [] for _ in range(5000):
observations += [observation.tolist()]
if done:
break
outcome = np.dot(policy, observation)
action = 1 if outcome > 0 else 0
observation, reward, done, info = env.step(action) score += reward return score, observationsmax = (0, [], [])for _ in range(10): policy = np.random.rand(1,4) score, observations = play(env, policy) if score > max[0]:
max = (score, observations, policy)print('Max Score', max[0])from flask import Flaskimport jsonapp = Flask(__name__, static_folder='.')@app.route("/data")def data(): return json.dumps(max[1])@app.route('/')def root():
return app.send_static_file('./index.html')
app.run(host='0.0.0.0', port='3000')
如果我們現在運行 repl,應該會得到最多為 500 分的分數,如果沒有達到這個結果,那就再運行 repl 一遍。另外我們可以看到策略幾乎完美地讓推車上的桿子保持平衡。
不是那么快
不過實際上或許沒有這么好,因為我們在第一部分稍微有一點作弊。首先,我們只是在 0 到 1 的范圍內隨機創建了策略數組。這恰好可行,但是如果我們修改一下運算符,就會看到 agent 出現災難性的失敗。你自己可以試試將 action = 1 if outcome > 0 else 0 改成 action = 1 if outcome < 0 else 0。
但是效果仍然不穩定,因為如果我們恰好選擇少于而不是大于 0,我們永遠找不到最優的策略。為了解決這個問題,我們實際上應該生成對負數同樣適用的策略。雖然這為我們的工作增加了難度,但我們再也不必通過將我們的特定算法擬合特定游戲來“作弊”了。不然,如果我們試圖在 OpenAIgym 以外的其他環境中運行算法時,算法肯定會失敗。
要做到這一點,我們不再使用 policy = np.random.rand(1,4),而是改為 policy = np.random.rand(1,4) - 0.5。這樣我們策略中的每個數字都在 -0.5 到 0.5 之間,而不是 0 到 1。但是因為這樣難度更高,我們還想搜索更多的策略。在上面的 for 循環中,不是迭代 10 個策略,而是通過讓代碼改為讀取 for _ in range(100): 來嘗試 100 個策略。此外也鼓勵大家嘗試首先只迭代 10 個策略,看看現在用負數來獲得好的策略的難度如何。
現在我們的main.py 應該如下所示:
import gym
import numpy as np
env = gym.make('CartPole-v1')
def play(env, policy):
observation = env.reset()
done = False
score = 0
observations = []
for _ in range(5000):
observations += [observation.tolist()]
if done:
break
outcome = np.dot(policy, observation)
action = 1 if outcome > 0 else 0
observation, reward, done, info = env.step(action)
score += reward
return score, observations
max = (0, [], [])
# 修改接下來兩行!
for _ in range(100):
policy = np.random.rand(1,4) - 0.5
score, observations = play(env, policy)
if score > max[0]:
max = (score, observations, policy)
print('Max Score', max[0])
from flask import Flask
import json
app = Flask(__name__, static_folder='.')
@app.route("/data")
def data():
return json.dumps(max[1])
@app.route('/')
def root():
return app.send_static_file('./index.html')
app.run(host='0.0.0.0', port='3000')
如果現在運行 repl,無論我們使用的值是否大于或小于 0,我們仍然可以為游戲找到一個好的策略。
但是等等,這還沒完!即使我們的策略可以運行一次就達到最高分 500,但每次都能做到嗎?當我們生成 100 個策略,并選擇出在單一運行中表現最佳的策略時,該策略可能只是走運而已,甚至它可能是一個非常糟糕的策略,只是恰好運行效果很好。這是因為游戲本身具有隨機性因素(起始位置每次都不同),因此策略可能只適用于一個起始位置,換成其他起始位置就不行了。
因此,為了解決這個問題,我們需要評估策略在多次試驗中的表現。現在,我們使用之前找到的最優策略,看看它在 100 次試驗中的表現如何。
scores = []for _ in range(100): score, _ = play(env, max[2])
scores += [score] print('Average Score (100 trials)', np.mean(scores))
這里我們將該策略運行 100次,并且每次都記錄它的得分。然后我們使用 numpy 計算平均分數并將其打印到我們的終端。沒有嚴格的已發布的“已解決”定義,但它應該只有少數幾個點。你可能會注意到最好的政策實際上可能實際上是低于平均水平。但是,我會把解決方案留給你決定!
當然,對于何為“最優”并沒有嚴格的定義,但是至少比最高分 500 來說不應太差。你可能注意到最優策略有時是低于平均水平的,但是最終的最優策略如何,還是要靠大家根據自己的實際情況來定奪。
結語
恭喜!至此我們成功創建了一個 AI,能夠很好地玩耍這個簡單的平衡游戲。不過,仍然有很多需要改進的地方:
以上所述是小編給大家介紹的使用50行Python代碼從零開始實現一個AI平衡小游戲,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對億速云網站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





