溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
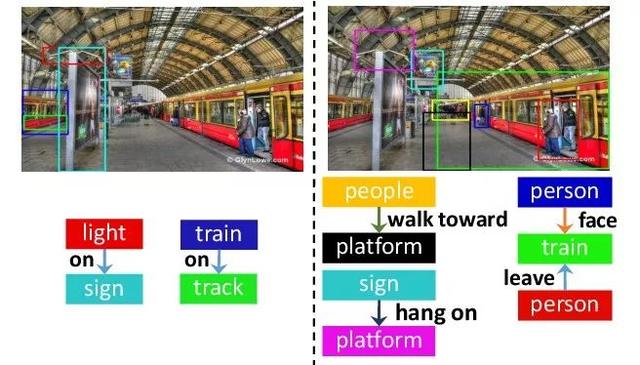
【導讀】本文提出視覺相關的對象關系在語義理解上有更高的價值。在視覺關系學習表達中,我們需要關注于視覺相關關系,而避免對于視覺無關的信息學習。由于現有數據中存在大量的非視覺的先驗信息,方法上很容易學到簡單的位置關系或單一固定關系,而不具備進一步推測學習語義信息的能力。從而導致現有關系數據的表征并不能明顯提升語義相關任務性能。來 新智元AI朋友圈 和AI大咖們一起討論吧。
本文提出視覺相關的對象關系在語義理解上有更高的價值。在視覺關系學習表達中,我們需要關注于視覺相關關系,而避免對于視覺無關的信息學習。由于現有數據中存在大量的非視覺的先驗信息,方法上很容易學到簡單的位置關系或單一固定關系,而不具備進一步推測學習語義信息的能力。從而導致現有關系數據的表征并不能明顯提升語義相關任務性能。而本文提出明確了視覺關系學習中什么是值得學習的,什么是需要學習的。并且通過實驗,也驗證了所提出的視覺相關關系數據可以有效的提升特征的語義理解能力。
數據及項目網站:
論文:
引文:
在計算機視覺的研究中,感知任務(如分類、檢測、分割等)旨在準確表示單個物體對象信息;認知任務(如看圖說話、問答系統等)旨在深入理解整體場景的語義信息。而從單個物體對象到整體場景,視覺關系表征兩個物體之間的交互,連接多個物體構成整體場景。關系數據可以作為物體感知任務和語義認知任務之間的橋梁和紐帶,具有很高的研究價值。
考慮到關系數據在語義上的這種紐帶的作用,對象關系數據應當有效的推進計算機視覺方法對于場景語義理解上的能力。構建從單物體感知,到關系語義理解,到整體場景認知,由微觀到宏觀,由局部到整體的層次化的視覺理解能力。
但現有關系數據中,由于大量先驗偏置信息的存在,導致關系數據的特征并不能有效的利用在語義理解中。其中,位置關系如``on'', ``at''等將關系的推理退化為對象檢測任務,而單一固定的關系,如``wear'',``has''等,由于數據中主體客體組合搭配固定,此類關系將關系推理退化為簡單演繹推理。因此這些關系數據的大量存在,導致關系特征的學習更多傾向于對單物體感知,而非真正的對場景語義的理解,從而無法使關系數據發揮的作用。同時,這種語義上的、學習上的先驗偏置,無法通過常規的基于頻率或規則的方法篩選剔除,這導致上述數據端的問題阻礙了關系語義理解上的發展與研究,使得視覺對象關系的研究與語義理解的目標漸行漸遠。
本文首先提出視覺相關假設和視覺相關關系判別網絡來構建具有更高語義價值的數據集。我們認為,許多關系數據不需要理解圖像,僅僅通過單物體感知上的標簽信息(如bounding box, class)就可以推斷的是關系學習中應避免的,即非視覺相關關系。而在關系數據中,對于視覺相關關系的學習與理解,將逼迫網絡通過圖像上的視覺信息,推理得到關系語義信息,而不是依賴基于單物體感知的能力,擬合先驗偏置的標簽。
在我們的方法中,我們設計了一個視覺相關判別網絡,通過網絡自主的學習,分辨那些僅通過一些標簽信息即可推斷的非視覺相關關系,從而保證數據中留存的都是具有高語義價值的視覺相關關系。此外,我們設計了一個考慮關系的聯合訓練方法,有效的學習關系標簽的信息。在實驗中,我們從兩個方面驗證了我們的想法。關系表征學習中,在場景圖生成任務上,我們的視覺相關關系有效的拉大了學習型方法與非學習型方法之間的性能差距,由此證明了非視覺關系是關系數據中的先驗偏置且通過簡單方法即可推斷。另一方面,通過學習視覺相關關系,我們得到的特征具有更好的語義表達與理解能力。該特征也在問答系統、看圖說話中展現出更好的性能,由此證明了視覺相關關系是真正需要被學習,且更有利于提升語義理解能力。
方法:
1. 視覺相關判別網絡(VD-Net)
提出的VD-Net用于分辨對象關系是否視覺相關。網絡僅需要物體對象的位置信息bounding box和類別信息class,并將兩種信息做編碼輸入,而不考慮圖像信息。具體輸入如下:
位置編碼:

其中含有物體中心點、寬高、位置關系信息、尺寸信息等。
針對類別信息,我們使用類別標簽的glove 特征向量作為輸入。
網絡設置如下:
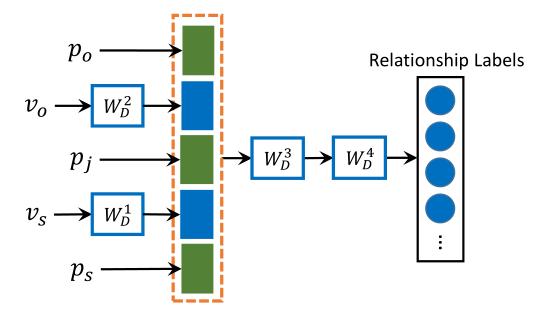
為了避免過擬合,網絡設計需要盡可能的小。網絡包含4個全連接層,其中,,分別是主體、客體的位置編碼及二者聯合位置編碼。,分別是主體、客體對象的類別詞向量。
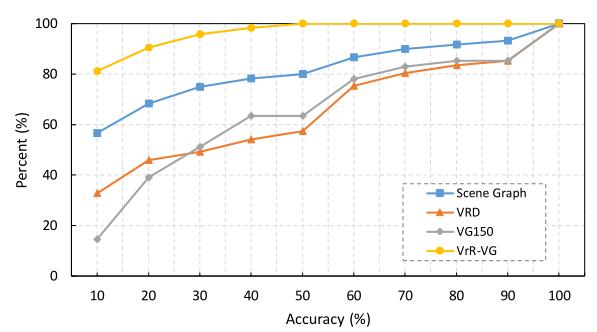
通過VD-Net的學習,可以發現現有的數據集中,關系預測具有很高的準確率,在VG150中,37%的標簽在VD-Net中有至少50%的準確率。
2. 考慮關系信息的聯合特征學習:
我們提出的方法如下:
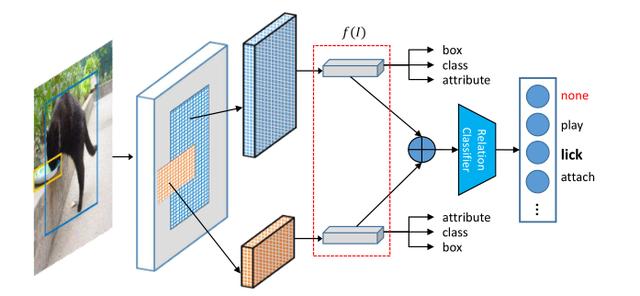
其中,我們使用Faster-RCNN用于特征提取,取自于RPN部分。網絡綜合的學習位置、類別、屬性和關系信息。通過對象關系的信息,進一步拓展特征的語義表征能力。
實驗:
1. 場景圖生成實驗:
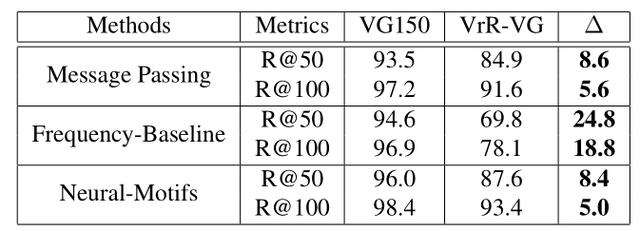
Freqency-Baseline是非學習型方法,基于對數據的統計。在我們的實驗中,VrR-VG明顯的拉開了非學習方法與可學習方法之間的性能差距。更加凸顯出場景圖生成任務中,各個方法的真實性能。同時,實驗也說明非視覺相關的關系比較容易。相對來說,在含有大量非視覺關系的情況下,網絡學習到的內容和基于統計的非學習型方法直接推斷的內容差距有限。
2.
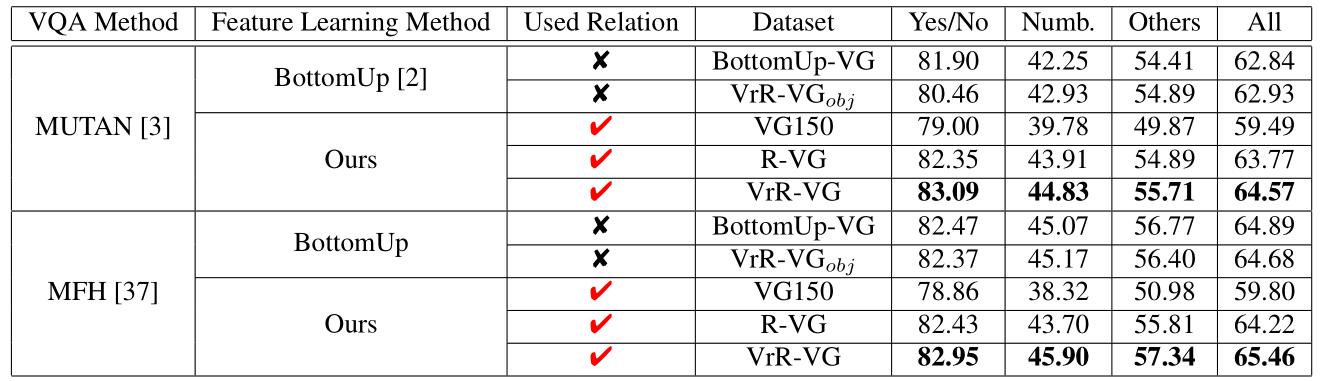
在問答系統實驗中,通過學習視覺相關關系,特征具有更好的性能,在指標上有明顯的提升。

在具體的案例分析上,通過學習視覺相關關系,特征能夠提供更多的語義信息。一些通過單物體信息無法正確回答的問題,在我們的方法下有明顯的效果。
3.
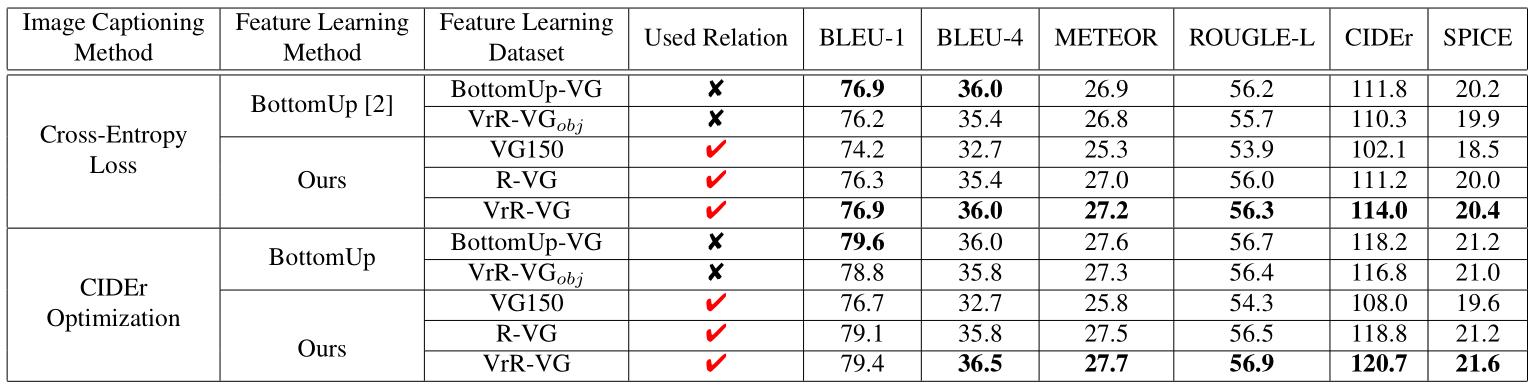
在看圖說話的任務中,通過學習視覺相關關系,任務的性能也有提升。

通過對生成的句子案例分析,我們可以發現,我們的方法給出了一些具有鮮明語義關系的句子。有時句子整體會有更加鮮活的表達,內涵更加豐富的交互信息。
結論:
在對象關系的學習與應用中,我們需要關注視覺相關關系的學習。現有關系數據不能有效的利用在語義相關的任務中,其主要問題是在數據側而非方法側。為了使對象關系應該在語義理解上有更廣泛深入的引用,需要首先明晰那些關系需要學習。在解決什么需要學的前提下,才能在如何學習的方法側走的更遠。
https://www.toutiao.com/i6763103092482245132/
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





