復制信息記錄表|全方位認識 mysql 系統庫
在上一期《時區信息記錄表|全方位認識 mysql 系統庫》中,我們詳細介紹了mysql系統庫中的時區信息記錄表,本期我們將為大家帶來系列第七篇《復制信息記錄表|全方位認識 mysql 系統庫》,下面請跟隨我們一起開始 mysql 系統庫的系統學習之旅吧!
1、復制信息表概述
復制信息表用于在從庫在復制主庫的數據期間,用于保存從主庫轉發到從庫的二進制日志事件、記錄有關中繼日志當前狀態和位置的信息。
一共有三種類型的日志,如下:
-
master.info文件或者mysql.slave_master_info表:用于保存從庫的IO線程連接主庫的連接狀態、帳號、IP、端口、密碼以及IO線程當前讀取主庫binlog的file和position等信息(被稱為IO線程信息日志。默認情況下,IO線程的連接信息和狀態保存在master.info文件中(默認位置在datadir下,可以使用master_info_file選項執行master.info文件路徑),如果需要保存在mysql.slave_master_info表中,需要在server啟動之前設置master-info-repository = TABLE)。
-
relay-log.info文件或者mysql.slave_relay_log_info表:
從庫的IO線程從主庫獲取到最新的binlog事件信息會先寫入到從庫本地的relay log中,SQL線程再去讀取relay log解析并重放,而relay_log.info文件或者mysql.slave_relay_log_info表就是用于記錄最新的relay log的file和position以及SQL線程當前重放的事件對應主庫binlog的file和position(relay log即被稱為中繼日志,SQL線程位置被稱為SQL線程信息日志。默認情況下,relay log的位置信息和SQL線程的位置信息保存在relay-log.info文件中(默認位置在datadir下,可以使用relay_log_info_file選項執行relay-log.info文件路徑),如果需要保存在mysql.slave_relay_log_info表中,需要在server啟動之前設置relay-log-info-repository = TABLE)。
設置relay_log_info_repository和master_info_repository設置為TABLE可以提高數據庫本身或者所在主機意外終止之后crash recovery的能力(這兩張表是innodb表,可以保證crash之后表中的位置信息不丟失),且可以保證數據一致性。
從庫crash時,SQL線程可能還有一部分relay log重放延遲,另外,IO線程的位置也可能正處于一個事務的中間,并不完整,所以必須在從庫上啟用參數relay-log-recovery=ON,啟用該參數之后,從庫crash recovery時會清理掉SQL線程未重放完成的relay log,并以SQL線程的位置為準重置掉IO線程的位置重新從主庫請求。
這兩張表在數據庫實例啟動時如果無法被mysqld初始化,則mysqld允許繼續啟動,但會在錯誤日志中寫入警告信息,這種情況在MySQL從不支持該表的版本升級到支持該表的版本時常常遇見。
PS:
2、復制信息表詳解
由于本期所介紹的表中存放的復制信息,在我們日常的數據庫維護過程當中尤其重要,所以,下文中會在每張表的介紹過程中適度進行一些擴展。
2.1. slave_master_info
該表提供查詢IO線程讀取主庫的位置信息,以及從庫連接主庫的IP、賬號、端口、密碼等信息。
下面是該表中存儲的信息內容。
root@localhost : mysql 01:08:29> select * from slave_master_info\G;
*************************** 1. row ***************************
Number_of_lines: 25
Master_log_name: mysql-bin.000292
Master_log_pos: 194
Host: 192.168.2.148
User_name: qfsys
User_password: letsg0
Port: 3306
Connect_retry: 60
Enabled_ssl: 0
Ssl_ca:
Ssl_capath:
Ssl_cert:
Ssl_cipher:
Ssl_key:
Ssl_verify_server_cert: 0
Heartbeat: 5
Bind:
Ignored_server_ids: 0
Uuid: ec123678-5e26-11e7-9d38-000c295e08a0
Retry_count: 86400
Ssl_crl:
Ssl_crlpath:
Enabled_auto_position: 0
Channel_name:
Tls_version:
1 row in set (0.00 sec)
表字段與show slave status輸出字段、master.info文件中的行信息對應關系及其表字段含義如下:
|
master.info文件中的行數 |
mysql.slave_master_info表字段 |
show slave status命令輸出字段 |
字段含義描述 |
|
1 |
Number_of_lines |
[None] |
表示master.info中的信息行數或者slave_master_info表中的信息字段數 |
|
2 |
Master_log_name |
Master_Log_File |
表示從庫IO線程當前讀取主庫最新的binlog file名稱 |
|
3 |
Master_log_pos |
Read_Master_Log_Pos |
表示從庫IO線程當前讀取主庫最新的binlog position |
|
4 |
Host |
Master_Host |
表示從庫IO線程當前正連接的主庫IO或者主機名 |
|
5 |
User_name |
Master_User |
表示從庫IO線程用于連接主庫用戶名 |
|
6 |
User_password |
[None] |
表示從庫IO線程用于連接主庫的用戶密碼 |
|
7 |
Port |
Master_Port |
表示從庫IO線程所連接主庫的網絡端口 |
|
8 |
Connect_retry |
Connect_Retry |
表示從庫IO線程斷線重連主庫的間隔時間,單位為秒,默認值為60 |
|
9 |
Enabled_ssl |
Master_SSL_Allowed |
表示主從之間的連接是否支持SSL |
|
10 |
Ssl_ca |
Master_SSL_CA_File |
表示CA(Certificate Authority )認證文件名 |
|
11 |
Ssl_capath |
Master_SSL_CA_Path |
表示CA(Certificate Authority )認證文件路徑 |
|
12 |
Ssl_cert |
Master_SSL_Cert |
表示SSL認證證書文件名 |
|
13 |
Ssl_cipher |
Master_SSL_Cipher |
表示用于SSL連接握手中可能使用到的密碼列表 |
|
14 |
Ssl_key |
Master_SSL_Key |
表示SSL認證的密鑰文件名 |
|
15 |
Ssl_verify_server_cert |
Master_SSL_Verify_Server_Cert |
表示是否需要校驗server的證書 |
|
16 |
Heartbeat |
[None] |
表示主從之間的復制心跳包的間隔時間,單位為秒 |
|
17 |
Bind |
Master_Bind |
表示從庫可用于連接主庫的網絡接口,默認為空 |
|
18 |
Ignored_server_ids |
Replicate_Ignore_Server_Ids |
表示從庫復制需要忽略哪些server-id,注意:這是一個列表,第一個數字表示需要忽略的實例server-id總數 |
|
19 |
Uuid |
Master_UUID |
表示主庫的UUID |
|
20 |
Retry_count |
Master_Retry_Count |
表示從庫最大允許重連主庫的次數 |
|
21 |
Ssl_crl |
[None] |
SSL證書撤銷列表文件的路徑 |
|
22 |
Ssl_crl_path |
[None] |
包含ssl證書吊銷列表文件的目錄路徑 |
|
23 |
Enabled_auto_position |
Auto_position |
表示從庫是否啟用在主庫中自動尋找位置的功能(使用1時啟動自動尋找位置,如果使用auto_position=0,則不會自耦東找位置) |
|
24 |
Channel_name |
Channel_name |
表示從庫復制通道名稱,一個通道代表一個復制源 |
|
25 |
Tls_Version |
Master_TLS_Version |
表示在Master上的TLS版本號 |
2.2. slave_relay_log_info
該表提供查詢SQL線程重放的二進制文件對應的主庫位置和relay log當前最新的位置。
下面是該表中存儲的信息內容。
root@localhost : mysql 10:39:31> select * from slave_relay_log_info\G
*************************** 1. row ***************************
Number_of_lines: 7
Relay_log_name: /home/mysql/data/mysqldata1/relaylog/mysql-relay-bin.000205
Relay_log_pos: 14097976
Master_log_name: mysql-bin.000060
Master_log_pos: 21996812
Sql_delay: 0
Number_of_workers: 16
Id: 1
Channel_name:
1 row in set (0.00 sec)
表字段與show slave statu
s輸出字段、relay-log.info文件中的行信息對應關系及其表字段含義如下:
|
relay-log.info文件中的行數 |
mysql.slave_relay_log_info表字段 |
show slave status命令輸出字段 |
字段含義描述 |
|
1 |
Number_of_lines |
[None] |
表示relay-log.info中的信息行數或者slave_relay_log_info表中的信息字段數,用于版本化表定義 |
|
2 |
Relay_log_name |
Relay_Log_File |
表示當前最新的relay log文件名稱 |
|
3 |
Relay_log_pos |
Relay_Log_Pos |
表示當前最新的relay log文件對應的最近一次完整接收的event的位置 |
|
4 |
Master_log_name |
Relay_Master_Log_File |
表示SQL線程當前正在重放的中繼日志對應的主庫binlog 文件名 |
|
5 |
Master_log_pos |
Exec_Master_Log_Pos |
表示SQL線程當前正在重放的中繼日志對應主庫binlog 文件中的位置 |
|
6 |
Sql_delay |
SQL_Delay |
表示延遲復制指定的從庫必須延遲主庫多少秒 |
|
7 |
Number_of_workers |
[None] |
表示從庫當前并行復制有多少個worker線程 |
|
8 |
Id |
[None] |
用于內部唯一標記表中的每一行記錄,目前總是1 |
|
9 |
Channel_name |
Channel_name |
表示從庫復制通道名稱,用于多源復制,一個通道對應一個主庫源 |
什么是中繼日志:
-
中繼日志(relay log)與二進制日志(binlog,即,binary log)中,保存的event數據是一樣的(但中繼日志中還保存了更多的信息),也是由一組包含描述數據庫變更的事件數據的文件組成,這些文件名后綴帶連續編號,此外,還有一個包含所有正在使用的中繼日志文件名稱的索引文件。
-
中繼日志中的數據存放格式與二進制日志相同,都可以使用mysqlbinlog命令來提取數據,默認情況下,中繼日志保存在datadir下,文件名格式為:
host_name-relay-bin.nnnnnn,其中host_name是從庫服務器主機名,nnnnnn是文件后綴序列號。連續的中繼日志文件從000001開始的連續序列號創建。使用索引文件來跟蹤當前正在使用的中繼日志文件。默認的中繼日志索引文件名保存在datadir下,文件名格式為:host_name-relay-bin.index。
* 中繼日志文件和中繼日志索引文件名稱可分別使用--relay-log和--relay-log-index參數選項指定值覆蓋默認值,如果文件名使用默認值,則要注意主機名稱不能修改,否則會報無法打開中繼日志的錯誤,建議使用參數選項指定固定的文件名稱前綴。如果已經出現了這種情況發生報錯了,那么需要修改index文件中的中繼日志文件名和datadir下的中繼日志文件名前綴為新的主機名,然后重啟從庫。
在什么情況下會產生新的中繼日志文件。
-
I/O線程啟動時。
-
使用語句:
FLUSH LOGS或mysqladmin flush-logs命令時。
-
當前中繼日志文件的大小變得“太大”時,日志滾動規則如下:
* 如果max_relay_log_size系統變量的值大于0,那么中繼日志按照此參數指定的大小進行滾動。
* 如果max_relay_log_size系統變量的值為0,則中繼日志按照max_binlog_size系統變量指定的大小進行滾動。
SQL線程在執行完relay log之后,會自行決定何時清理掉這些已經執行完成的relay log文件,但如果使用FLUSH LOGS語句或mysqladmin flush-logs命令強制滾動中繼日志時,SQL線程可能會同時清理掉已經執行完成的relay log文件。
2.3. slave_worker_info
該表提供查詢多線程復制時的worker線程狀態信息,與performance_schema.replication_applier_status_by_worker表的區別是:
slave_worker_info表記錄worker線程重放的relay log和主庫binlog位置信息,而performance_schema.replication_applier_status_by_worker表記錄的是worker線程重放的GTID位置信息。
下面是該表中存儲的信息內容。
root@localhost : mysql 01:09:39> select * from slave_worker_info limit 1\G;
*************************** 1. row ***************************
Id: 1
Relay_log_name:
Relay_log_pos: 0
Master_log_name:
Master_log_pos: 0
Checkpoint_relay_log_name:
Checkpoint_relay_log_pos: 0
Checkpoint_master_log_name:
Checkpoint_master_log_pos: 0
Checkpoint_seqno: 0
Checkpoint_group_size: 64
Checkpoint_group_bitmap:
Channel_name:
1 row in set (0.00 sec)
表字段含義。
-
Id:
表中數據的ID,也是worker線程的ID,對應著performance_schema.replication_applier_status_by_worker表的WORKER_ID字段(如果復制停止,則該字段值仍然存在,不像performance_schema.replication_applier_status_by_worker表中THREAD_ID字段值會清空)。
-
Relay_log_name:
每個worker線程當前最新執行到的relay log文件名。
-
Relay_log_pos:
每個worker線程當前最新執行到的relay log文件中的position。
-
Master_log_name:
每個worker線程當前最新執行到的主庫binary log文件名。
-
Master_log_pos:
每個worker線程當前最新執行到的主庫binary log文件中的position。
-
Checkpoint_relay_log_name:
每個worker線程最新檢查點的relay log文件名。
-
Checkpoint_relay_log_pos:
每個worker線程最新檢查點的relay log文件中的position。
-
Checkpoint_master_log_name:
每個worker線程最新檢查點對應主庫的binary log文件名。
-
Checkpoint_master_log_pos:
每個worker線程最新檢查點對應主庫的binary log文件中的position。
-
Checkpoint_seqno:
每個worker線程當前最新執行完成的事務號,這個事務號的大小值是相對于每個worker線程自己的最新檢查點而言的,并不是真正的事務號。
-
Checkpoint_group_size:
表示每個worker線程的執行隊列大于這個字段值時,就會觸發當前worker線程執行一次檢查點。
-
Checkpoint_group_bitmap:
用于從庫crash之后recovery的關鍵值,它是一個位圖值,表示每個worker線程在自己的最新檢查點中已經執行的事務。
-
Channel_name:
復制通道名稱,多主復制時,顯示指定的復制通道名稱,單主復制時該字段為空。
該表中記錄的內容對從庫多線程復制crash recovery至關重要,所以下文對該表中記錄的內容如何作用于crash recovery過程進行一些必要的說明。
從庫多線程復制如何做復制分發。
-
我們知道在MySQL 5.7中加入了基于事務的并行復制(基于行),主庫在binlog的GTID事件中新加入了last_commit和sequence_number標記,用于表示在每個binlog中的每個group中的提交順序(每個binlog中重置這兩個計數標記),在每個給定的binlog中,每個group中的last_commit總是為上一個group中最大的sequence_number、總是為當前group中最小的sequence_number - 1(在每個binlog中,last_commit總是從0開始計數,sequence_number總是從1開始計數)。
-
從庫relay log中記錄的主庫binlog,不會改變主庫的server id、時間戳信息以及last_commit和sequence_number值,這樣,從庫SQL線程在執行binlog重放時,就可以依據這些信息決定從庫是否需要嚴格按照主庫提交順序進行提交(從庫重放的事務只是分發順序按照主庫提交順序,但是從庫自己在提交這些事務時是否按照主庫提交順序進行提交,還需要看從庫自己的slave_preserve_commit_order變量設置,設置為1則嚴格按照relay log中的順序進行提交,設置為0從庫會自行決定提交順序)。
-
SQL線程并行分發原理。
* SQL協調器線程讀取到一個新的事務,取出last_commit和sequence_number值。
* SQL協調器線程判斷取出的新事務的當前last_commit是否大于當前已執行完成的sequence_number中的最小值(Low water mark,簡稱LWM,也叫低水位線標記)。
* 如果SQL協調器線程讀取到的當前事務的last_commit大于當前已執行完成的sequence_number值,則說明上一個group中的事務還沒有全部執行完成,此時SQL協調器線程需要等待所有的worker線程執行完成上一個group中的事務,等待LWM變大,直到當前讀取到的事務的last_commit與當前已執行完成的事務的最小sequence_number值相等才可以繼續分發新的事務給空閑的worker線程(并行復制是針對每個group內的事務才可以并行復制,所以,group之間是串行的,一個group未執行完成之前,下一個group的事務是需要進行等待的。
只有同一個group內的事務之間才可以并行執行。根據上文中的描述,每個group中的事務的last_commit總是為當前group中最小的sequence_number - 1,即,如果SQL協調器線程讀取到的當前事務的last_commit小于當前已執行完成事務的最小的sequence_number 就說明當前所有worker線程正在執行的事務處于同一個group中,那么也就是說SQL協調器線程可以繼續往下尋找空閑的worker線程進行分發,否則SQL協調器線程就需要進行等待)。
* SQL協調器線程通過統計worker線程返回的狀態信息,尋找一個空閑的worker線程,如果沒有空閑的線程,則SQL協調器線程需要進行等待,知道找到一個空閑的worker線程為止(如果有多個worker線程,則SQL協調器線程隨機選擇一個空閑的worker線程進行分發)。
* 將當前讀取到的事務的binlog event分發給選定的空閑worker線程,之后worker線程會去應用這個事務,然后SQL協調器線程繼續讀取新的binlog event(注意,SQL協調器線程分發是按照event為單位的,不是事務單位,所以,如果當一個事務的第一個event分發給了給定worker線程之后,后續讀取到的新的event如果同屬于一個事務,則進入下一個事務之前的所有event都會分發給同一個worker線程處理。
當一個事務中所有的binlog event組分發完成,讀取到下一個新的事務時,SQL協調器線程會重復以上判斷流程)。
從庫多線程復制的crash recovery。
-
從前面多線程復制分發的原理我們可以知道,處于同一個group中的事務是并行應用的,且事務是隨機分配的,在從庫正常運行過程當中,如果任意掐一刻下去,那么所有worker線程正在執行的事務中,哪些是已經執行完成的,哪些還未執行完成其實是無法使用單個位置來確定(因為從庫并行復制時有可能是亂序提交:
需要看slave_preserve_commit_order變量如何設置),也就是說所有worker線程中正在執行的最大位置和最小位置之間可能有斷點。那MySQL是如何解決從庫crash recovery的斷點續做問題的呢?
-
MySQL 為了解決這個問題,對worker線程的執行狀態做了很多記錄工作,首先,維護了一個隊列,這個隊列叫做GAQ(Group Assigned Queue),當SQL協調器線程在分配某一個事務時,首先會將這個事務加入到這個隊列,然后,才會去按照規則來尋找一個空閑的worker線程來執行,如下圖(鄭重聲明:
該圖來自書籍《MySQL 運維內參》):
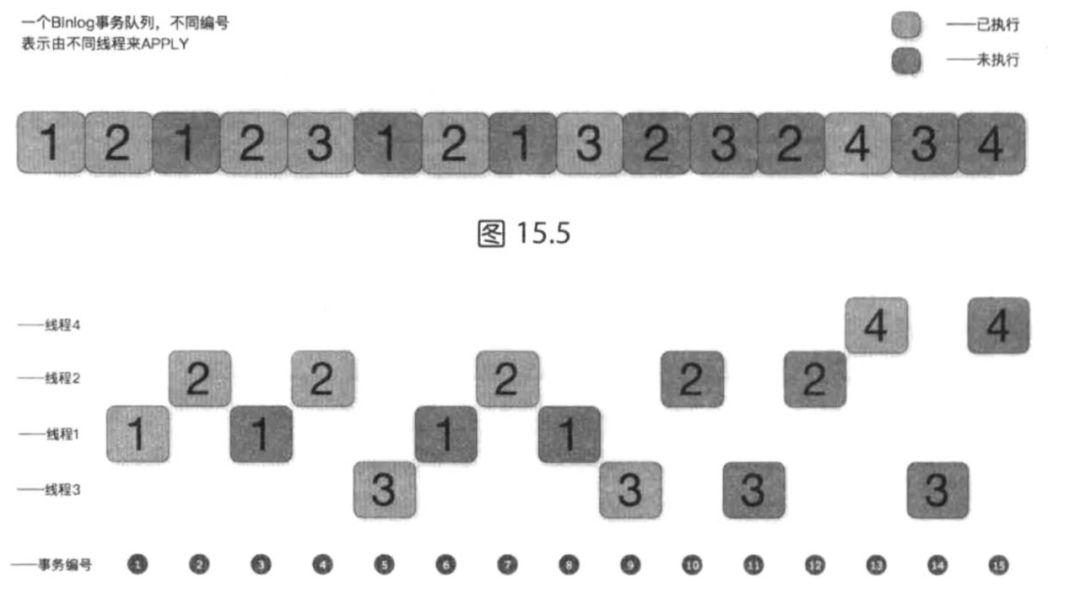
每一個事務在分發到worker線程之后,都會分配一個編號,這個編號在某一段時間內,都是相對固定的,這個編號一旦被分配,就不會再改變。
在事務被某個worker線程執行完成之后,它的位置信息就會被flush一次,這與5.5版本中的relay_log_info記錄的原理是類似的(relay_log_info中存放了從庫當前SQL線程重放的位置),但是現在是多線程,每個worker線程的執行位置不能直接存放在relay_log_info中了,relay_log_info中存放的是所有worker線程匯總之后的位置,每個worker線程獨立的位置信息存放在了mysql.slave_worker_info表中,在該表中,有多少個并行復制線程,就有多少行記錄(如果是多主復制,則每個復制通道都有slave_parallel_workers變量指定的記錄數)。
mysql.slave_worker_info表中,Checkpoint開頭的字段記錄了每個worker線程的檢查點相關的信息(這里與innodb存儲引擎的檢查點不同,但是概念相通),worker線程的檢查點的作用是什么呢?
-
前面說了SQL協調器線程在分配事務給worker線程之前會將事務先存放到GAQ隊列中,但是這個隊列的長度是有限的(是不是很熟悉?
跟redo log的總大小是有限的概念類似),不可能無限制的增長下去,所以必須要在這個隊列中,找到一個位置點,這個位置點就是GAQ的起點位置,這個位置點之前的binlog就表示已經執行完成了。確定這個位置的過程,就叫做檢查點。在多線程復制的執行過程中,隨著每個worker線程不斷第應用事務的binlog,檢查點在GAQ中被不斷地向前推進,每個worker線程通過Checkpoint_point_bitmap字段記錄自己已經執行過的事務和每個已執行事務與之對應的當時的最新檢查點的相對位置,這樣一來,當復制意外終端之后,重新開始復制時,就可以通過所有的worker線程記錄的Checkpoint_point_bitmap字段來計算出哪些事務是已經執行過的,哪些事務是還未執行的,即通過所有worker線程記錄的Checkpoint_point_bitmap信息執行一次檢查點操作就可以找到一個合適的恢復位置,執行檢查點的大概過程如下(注意:這里是執行檢查點的過程,與從庫crash recovery過程無關):
* 在GAQ隊列中,從尾部開始掃描,如果是已經執行過的事務,則直接將其從隊列中刪除。
* 持續掃描GAQ隊列,直到找到一個未執行過的事務為止即停止掃描。
* 上述步驟中掃描動作停止前掃描到的最后一個事務被確定為檢查點的最新位置,并且別標記為LWM(低水位線標記)。
* 將當前LWM這個事務對應的位置(master_log_pos和relay_log_pos位置)設置為此次檢查點對應的位置。
* 通過所有的worker線程檢查自己的檢查點,也就是查看每個worker線程自己的Checkpoint_seqno字段值,這個字段值是每個worker線程在執行事務提交時更新的,更新的字段值為每個worker線程在做事務提交時對應的最新檢查點的相對位置。
* 將本次執行檢查點的位置記錄到mysql.slave_relay_log_info表中,作為全局bin
log應用的位置。
-
現在,我們來看從庫crash recovery的過程:
* 首先,讀取mysql.slave_master_info、mysql.slave_relay_log_info、mysql.slave_worker_info表中的信息讀取出來,從mysql.slave_master_info表中找到連接主庫的信息,從mysql.slave_relay_log_info表中找到全局最新的復制位置以及worker線程個數,從mysql.slave_worker_info表中找到每一個worker線程對應的復制信息位置。
* 然后,根據mysql.slave_relay_log_info表中的位置(這個位置就是全局最新的檢查點位置)為準來判斷所有worker線程的位置,在這個位置之前的worker線程位置就表示已經執行過的了,直接剔除,在這個位置之后的worker線程位置就表示這些事務是還沒有執行過的(根據每個worker線程在mysql.slave_worker_info表中記錄的Checkpoint_seqno和Checkpoint_group_bitmap字段計算出自己哪些事務沒有執行過,然后通過每個worker線程在mysql.slave_worker_info表中記錄的其他checkpoint字段信息轉換為對應的全局檢查點的位置。
然后根據所有worker線程的轉換位置信息匯總為一個共同的bitmap,根據這個共同的bitmap來比對mysql.slave_relay_log_info表中的位置就可以提取出哪些事務還沒有執行過),找出了哪些事務還沒有執行之后,把這些事務串行地一個一個地去重新應用(應用一個更新一次mysql.slave_relay_log_info表,為什么要串行,這是為了在恢復過程中如果再次跪了,還可以正確地恢復位置),應用完成之后清空mysql.slave_worker_info表。然后啟動復制線程,繼續從主庫拉取最新的binlog進行數據復制。
PS:
如果在主從復制架構中,有2個以上的從庫,且從庫永遠不做提升主庫的操作時,可以使用如下方法優化從庫延遲(在該場景下,從庫無需擔心數據丟失問題,因為有另外一個從庫兜底+不做主從切換,只需要專心提供快速應用主庫binlog與只讀業務即可)。
-
關閉log_slave_updates參數,減少從庫binlog寫入量(如果不做級聯復制甚至可以同時關閉binlog)。
-
設置innodb_flush_log_at_trx_commit為0或者2,減少事務提交時redo log的等待頻率。
-
設置sync_binlog為默認值或者更大的值,減少事務提交時binlog的等待頻率。
-
設置slave_preserve_commit_order參數為OFF(默認為OFF,設置為ON時要求開啟binlog和log_slave_updates參數),減少事務嚴格按照主庫順序提交時的提交等待時間。
2.4. gtid_executed
前面介紹的三張表中,存放的都不包括GTID信息,在數據庫運行過程中,GTID相關的信息是保存在performance_schema下的相關表中,詳見"全方位認識 performance_schema"系列文章《復制狀態與變量記錄表 | performance_schema全方位介紹》。
但是performance_schema下的表都是內存表,記錄的信息是易失的。gtid_executed表才是GTID信息的持久表,該表提供查詢與當前實例中的數據一致的GTID集合(該表用于存儲所有事務分配的 GTID集合,GTID集合由UUID集合構成,每個UUID集合的組成為:uuid:interval[:interval]...,例如 :28b13b49-3dfb-11e8-a76d-5254002a54f2:1-600401,
3ff62ef2-3dfb-11e8-a448-525400c33752:1-110133)
-
GTID是在整個復制拓撲中是全局唯一的,GTID中的事務號是一個單調遞增的無間隙數字。
正常情況下,客戶端的數據修改在執行commit時會分配一個GTID,且會記錄到binlog中,這些GTID通過復制組件在其他實例中進行重放時也會保留GTID來源不變。但是如果客戶端自行使用sql_log_bin變量關閉了binlog記錄或者客戶端執行的是一個只讀事務,那么server不會分配GTID,在binlog中也不會有GTID記錄。
-
當某個從庫接受到自己的GTID集合中已經包含的GTID時,會忽略這個已存在的GTID,并且不會報錯,事務也不會被執行。
從MySQL 5.7.5開始,GTID存儲在mysql數據庫的名為gtid_executed的表中。
對于每個GTID集合,默認情況下值記錄每個GTID集合的起始和結束的事務號對應的GTID,該表只在數據庫初始化或者執行update_grade升級的時候創建,不允許手工創建于修改。當實例本身有客戶端訪問數據寫入或者有從其他主庫通過復制插件同步數據的時候,該表中會有新的GTID記錄寫入,另外,該表中的記錄還會在binlog滾動或者實例重啟的時候被更新(日志滾動時該表需要把除了最新的binlog之外其他binlog中的所有GTID結合記錄到該表中,實例重啟時,需要把所有的binlog中的GTID集合記錄到該表中)。
由于有mysql.gtid_executed表記錄GTID(避免了binlog丟失的時候丟失GTID歷史記錄),所以,從5.7.5版本開始,在復制拓撲中的從庫允許關閉binlog,也允許在binlog開啟的情況下關閉log_slave_updates變量。
由于GTID必須要再gtid_mode為ON或者為ON_PERMISSIVE時才會生成,所以自然該表中的記錄也需要依賴于gtid_mode變量為ON或ON_PERMISSIVE時才會進行記錄,另外,該表中是否實時存儲GTID,取決于binlog日志是否開啟,或者binlog啟用時是否啟用log_slave_updates變量,如下:
-
當禁用二進制日志記錄(log_bin為OFF),或者啟用binlog但禁用log_slave_updates,則Server會在每個事物提交時把屬于該事物的GTID同時更新到該表中。
此時,該表的GTID周期性自動壓縮功能激活,每達到gtid_executed_compression_period系統變量指定的事物數量壓縮一次該表中的GTID集合(也就是把每個UUID對應的事務號的記錄取一個最大值,取一個最小值,刪除中間值),要注意:周期性自動壓縮功能僅針對從庫,對主庫無效,因為主庫必須啟用binlog,且log_slave_updates參數不影響主庫。
-
如果啟用二進制日志記錄(log_bin為ON)且log_slave_updates參數也啟用,則周期性自動壓縮功能失效,該表中的記錄只會在binlog日志滾動或者服務器關閉時才會進行壓縮,且會把除了最后一個binlog之外,其他所有binlog中包含的GTID集合寫入該表中。
-
注意:
* 如果啟用二進制日志記錄(log_bin為ON)且log_slave_updates參數也啟用,那么該表不會實時記錄GTID,也就是說,完整的GTID集合,有一部分記錄在該表中,有一部分是記錄在binlog中的,如果一旦server發生crash,那么在crash recovery時會讀取binlog中最新的GTID集合并合并到該表中。
* 該表中的記錄在執行reset master語句時會被清空。
該表中的記錄周期性執行壓縮示例。
# 假設表中有如下實時記錄的GTID記錄
mysql> SELECT * FROM mysql.gtid_executed;
+ -------------------------------------- + ---------- ------ + -------------- +
| source_uuid | interval_start | interval_end |
| -------------------------------------- + ---------- ------ + -------------- |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 37 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 38 | 38 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 39 | 39 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 40 | 40 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 41 | 41 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 42 | 42 |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 43 | 43 |
...
# 那么,每達到gtid_executed_compression_period變量定義的事務個數時,激活壓縮功能,GTID被壓縮為一行記錄,如下
+ -------------------------------------- + ---------- ------ + -------------- +
| source_uuid | interval_start | interval_end |
| -------------------------------------- + ---------- ------ + -------------- |
| 3E11FA47-71CA-11E1-9E33-C80AA9429562 | 37 | 43 |
...
# 注意:當gtid_executed_compression_period系統變量設置為0時,周期性自動壓縮功能失效,你需要預防該表被撐爆的風險
表字段含義。
-
source_uuid:
代表數據來源的GTID集合。
-
interval_start:
每個UUID集合的最小事務號。
-
interval_end:
每個UUID集合的最大事務號。
對該表的壓縮功能由名為 thread/sql/compress_gtid_table 的專用前臺線程執行。
該線程使用SHOW PROCESSLIST無法查看,但它可以在performance_schema.threads表中查看到(線程 thread/sql/compress_gtid_table 大多數時候都處于休眠狀態,直到每滿gtid_executed_compression_period個事務之后,該線程被喚醒以執行前面所述的對mysql.gtid_executed表的壓縮。然后繼續進入睡眠狀態,直到下一次滿gtid_executed_compression_period個事務,然后被喚醒再次執行壓縮,以此類推,無限重復此循環。但如果當關閉binlog或者啟用binlog但關閉log_slave_updates變量時,gtid_executed_compression_period變量被設置為了0,那么意味著該線程會始終處于休眠狀態且永不會喚醒),如下所示:
mysql> SELECT * FROM performance_schema.threads WHERE NAME LIKE '%gtid%'\G
*************************** 1. row ***************************
THREAD_ID: 26
NAME: thread/sql/compress_gtid_table
TYPE: FOREGROUND
PROCESSLIST_ID: 1
PROCESSLIST_USER: NULL
PROCESSLIST_HOST: NULL
PROCESSLIST_DB: NULL
PROCESSLIST_COMMAND: Daemon
PROCESSLIST_TIME: 1509
PROCESSLIST_STATE: Suspending
PROCESSLIST_INFO: NULL
PARENT_THREAD_ID: 1
ROLE: NULL
INSTRUMENTED: YES
HISTORY: YES
CONNECTION_TYPE: NULL
THREAD_OS_ID: 18677
2.5. ndb_binlog_index
該表提供查詢ndb集群引擎相關的統計信息,由于國內較少使用NDB存儲引擎,這里不做過多介紹,有興趣的朋友可自行研究。
本期內容就介紹到這里,本期內容參考鏈接如下:
https://dev.mysql.com/doc/refman/5.7/en/replication-gtids-concepts.html#replication-gtids-gtid-executed-table
"翻過這座山,你就可以看到一片海!
"。
堅持閱讀我們的"全方位認識 mysql 系統庫"系列文章分享,你就可以系統地學完它。
謝謝你的閱讀,我們下期不見不散!
| 作者簡介
羅小波·沃趣科技高級數據庫技術專家
IT從業多年,主要負責MySQL 產品的數據庫支撐與售后二線支撐。曾參與版本發布系統、輕量級監控系統、運維管理平臺、數據庫管理平臺的設計與編寫,熟悉MySQL體系結構,Innodb存儲引擎,喜好專研開源技術,多次在公開場合做過線下線上數據庫專題分享,發表過多篇數據庫相關的研究文章。





