溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹SQL優化之如何使用索引,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
下面 sql 30秒執行出結果,查看 sql 謂詞中有 like ,我們知道謂詞中有這樣的語句是不走索引的(為了保護客戶的隱私,表名和部分列已經重命名)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
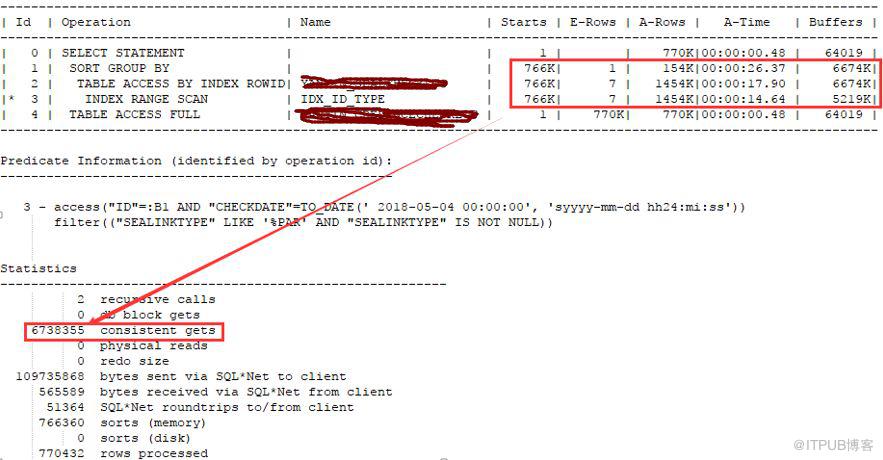
邏輯讀600多萬。查看索引情況如下

表過濾返回數據量如下:
1 2 3 4 5 6 |
|
通過查詢上面返回數據可知,因為xxxtype不走索引,所以通過索引要回表197984次,如果走了索引只回表12856次。
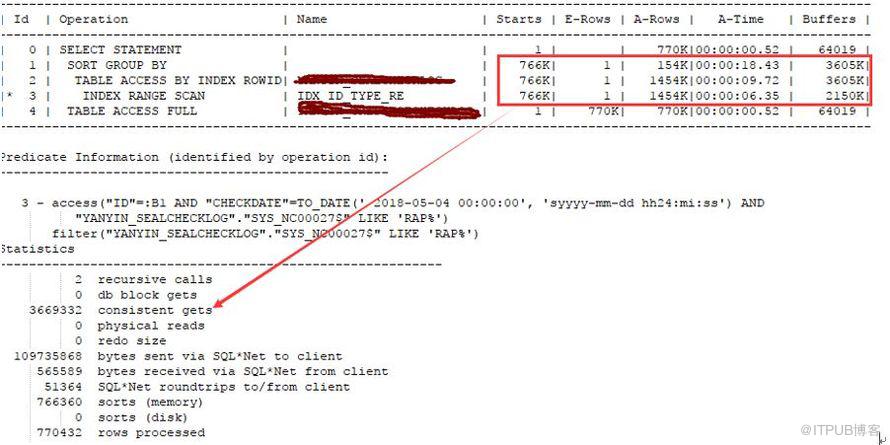
下面我們建立REVERSE索引IDX_ID_TYPE_RE
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
查看執行計劃如下,邏輯讀將為300萬,但是時間還是維持在 18 秒,根本原因在于這個索引因為標量子查詢的問題被訪問700 萬次導致。
下面我們改寫sql如下
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
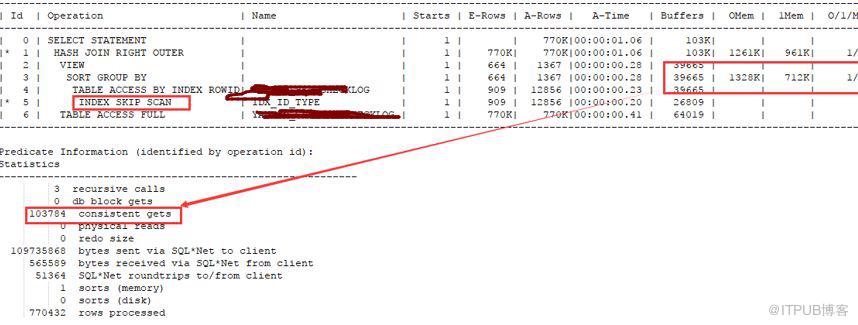
執行計劃中出現index_skip_scan。
下面我們創建如下索引:
1 |
|
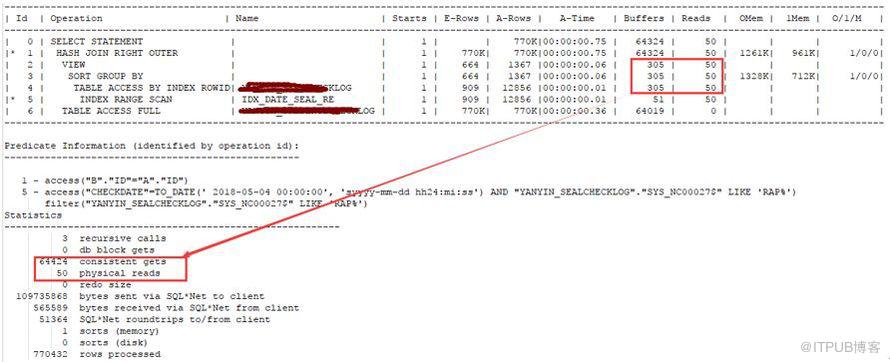
可以看到,邏輯讀降到64424, 50 個物理讀是因為剛剛創建索引的原因, sql 也秒出。
以上是“SQL優化之如何使用索引”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





