溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
作者 | 莫源?阿里巴巴技術專家
首先來看一下,整個需求的來源:當把應用遷移到 Kubernetes 之后,要如何去保障應用的健康與穩定呢?其實很簡單,可以從兩個方面來進行增強:
從可觀測性上來講,可以在三個方面來去做增強:
當出現了問題之后,首先要做的事情是要降低影響的范圍,進行問題的調試與診斷。最后當出現問題的時候,理想的狀況是:可以通過和 K8s 集成的自愈機制進行完整的恢復。
本小節為大家介紹 Liveness probe 和 eadiness probe。
Liveness probe 也叫就緒指針,用來判斷一個 pod 是否處在就緒狀態。當一個 pod 處在就緒狀態的時候,它才能夠對外提供相應的服務,也就是說接入層的流量才能打到相應的 pod。當這個 pod 不處在就緒狀態的時候,接入層會把相應的流量從這個 pod 上面進行摘除。
來看一下簡單的一個例子:
如下圖其實就是一個 Readiness 就緒的一個例子:
cdn.com/7972a7447a196a56fc78ede6a4fe04b0161e045c.png">
當這個 pod 指針判斷一直處在失敗狀態的時候,其實接入層的流量不會打到現在這個 pod 上。
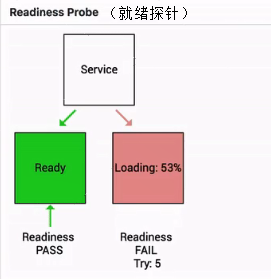
當這個 pod 的狀態從 FAIL 的狀態轉換成 success 的狀態時,它才能夠真實地承載這個流量。
Liveness 指針也是類似的,它是存活指針,用來判斷一個 pod 是否處在存活狀態。當一個 pod 處在不存活狀態的時候,會出現什么事情呢?
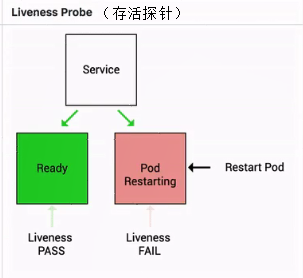
這個時候會由上層的判斷機制來判斷這個 pod 是否需要被重新拉起。那如果上層配置的重啟策略是 restart always 的話,那么此時這個 pod 會直接被重新拉起。
接下來看一下 Liveness 指針和 Readiness 指針的具體的用法。
Liveness 指針和 Readiness 指針支持三種不同的探測方式:
從探測結果來講主要分為三種:
那在 kubelet 里面有一個叫 ProbeManager 的組件,這個組件里面會包含 Liveness-probe 或 Readiness-probe,這兩個 probe 會將相應的 Liveness 診斷和 Readiness 診斷作用在 pod 之上,來實現一個具體的判斷。
下面介紹這三種方式不同的檢測方式的一個 yaml 文件的使用。
首先先看一下 exec,exec 的使用其實非常簡單。如下圖所示,大家可以看到這是一個 Liveness probe,它里面配置了一個 exec 的一個診斷。接下來,它又配置了一個 command 的字段,這個 command 字段里面通過 cat 一個具體的文件來判斷當前 Liveness probe 的狀態,當這個文件里面返回的結果是 0 時,或者說這個命令返回是 0 時,它會認為此時這個 pod 是處在健康的一個狀態。

那再來看一下這個 httpGet,httpGet 里面有一個字段是路徑,第二個字段是 port,第三個是 headers。這個地方有時需要通過類似像 header 頭的一個機制做 health 的一個判斷時,需要配置這個 header,通常情況下,可能只需要通過 health 和 port 的方式就可以了。

第三種是 tcpSocket,tcpSocket 的使用方式其實也比較簡單,你只需要設置一個檢測的端口,像這個例子里面使用的是 8080 端口,當這個 8080 端口 tcp connect 審核正常被建立的時候,那 tecSocket,Probe 會認為是健康的一個狀態。
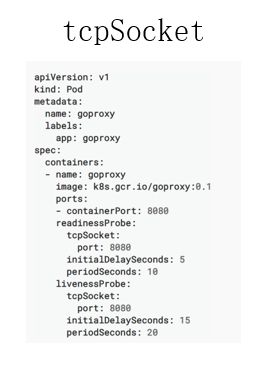
此外還有如下的五個參數,是 Global 的參數。
?
?
?
?
接下來對 Liveness 指針和 Readiness 指針進行一個簡單的總結。

Liveness 指針是存活指針,它用來判斷容器是否存活、判斷 pod 是否 running。如果 Liveness 指針判斷容器不健康,此時會通過 kubelet 殺掉相應的 pod,并根據重啟策略來判斷是否重啟這個容器。如果默認不配置 Liveness 指針,則默認情況下認為它這個探測默認返回是成功的。
Readiness 指針用來判斷這個容器是否啟動完成,即 pod 的 condition 是否 ready。如果探測的一個結果是不成功,那么此時它會從 pod 上 Endpoint 上移除,也就是說從接入層上面會把前一個 pod 進行摘除,直到下一次判斷成功,這個 pod 才會再次掛到相應的 endpoint 之上。
對于檢測失敗上面來講 Liveness 指針是直接殺掉這個 pod,而 Readiness 指針是切掉 endpoint 到這個 pod 之間的關聯關系,也就是說它把這個流量從這個 pod 上面進行切掉。
Liveness 指針適用場景是支持那些可以重新拉起的應用,而 Readiness 指針主要應對的是啟動之后無法立即對外提供服務的這些應用。
在使用 Liveness 指針和 Readiness 指針的時候有一些注意事項。因為不論是 Liveness 指針還是 Readiness 指針都需要配置合適的探測方式,以免被誤操作。
第一個是調大超時的閾值,因為在容器里面執行一個 shell 腳本,它的執行時長是非常長的,平時在一臺 ecs 或者在一臺 vm 上執行,可能 3 秒鐘返回的一個腳本在容器里面需要 30 秒鐘。所以這個時間是需要在容器里面事先進行一個判斷的,那如果可以調大超時閾值的方式,來防止由于容器壓力比較大的時候出現偶發的超時;
第二個是調整判斷的一個次數,3 次的默認值其實在比較短周期的判斷周期之下,不一定是最佳實踐,適當調整一下判斷的次數也是一個比較好的方式;
第三個是 exec,如果是使用 shell 腳本的這個判斷,調用時間會比較長,比較建議大家可以使用類似像一些編譯性的腳本 Golang 或者一些 C 語言、C++ 編譯出來的這個二進制的 binary 進行判斷,那這種通常會比 shell 腳本的執行效率高 30% 到 50%;
?
接下來給大家講解一下在 K8s 中常見的問題診斷。
首先要了解一下 K8s 中的一個設計理念,就是這個狀態機制。因為 K8s 是整個的一個設計是面向狀態機的,它里面通過 yaml 的方式來定義的是一個期望到達的一個狀態,而真正這個 yaml 在執行過程中會由各種各樣的 controller來負責整體的狀態之間的一個轉換。
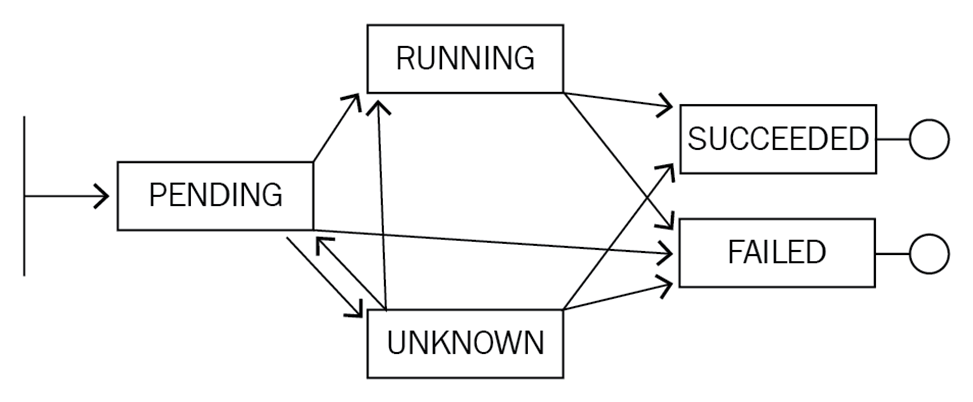

比如說上面的圖,實際上是一個 Pod 的一個生命周期。剛開始它處在一個 pending 的狀態,那接下來可能會轉換到類似像 running,也可能轉換到 Unknown,甚至可以轉換到 failed。然后,當 running 執行了一段時間之后,它可以轉換到類似像 successded 或者是 failed,然后當出現在 unknown 這個狀態時,可能由于一些狀態的恢復,它會重新恢復到 running 或者 successded 或者是 failed 。
其實 K8s 整體的一個狀態就是基于這種類似像狀態機的一個機制進行轉換的,而不同狀態之間的轉化都會在相應的 K8s對象上面留下來類似像 Status 或者像 Conditions 的一些字段來進行表示。
像下面這張圖其實表示的就是說在一個 Pod 上面一些狀態位的一些展現。
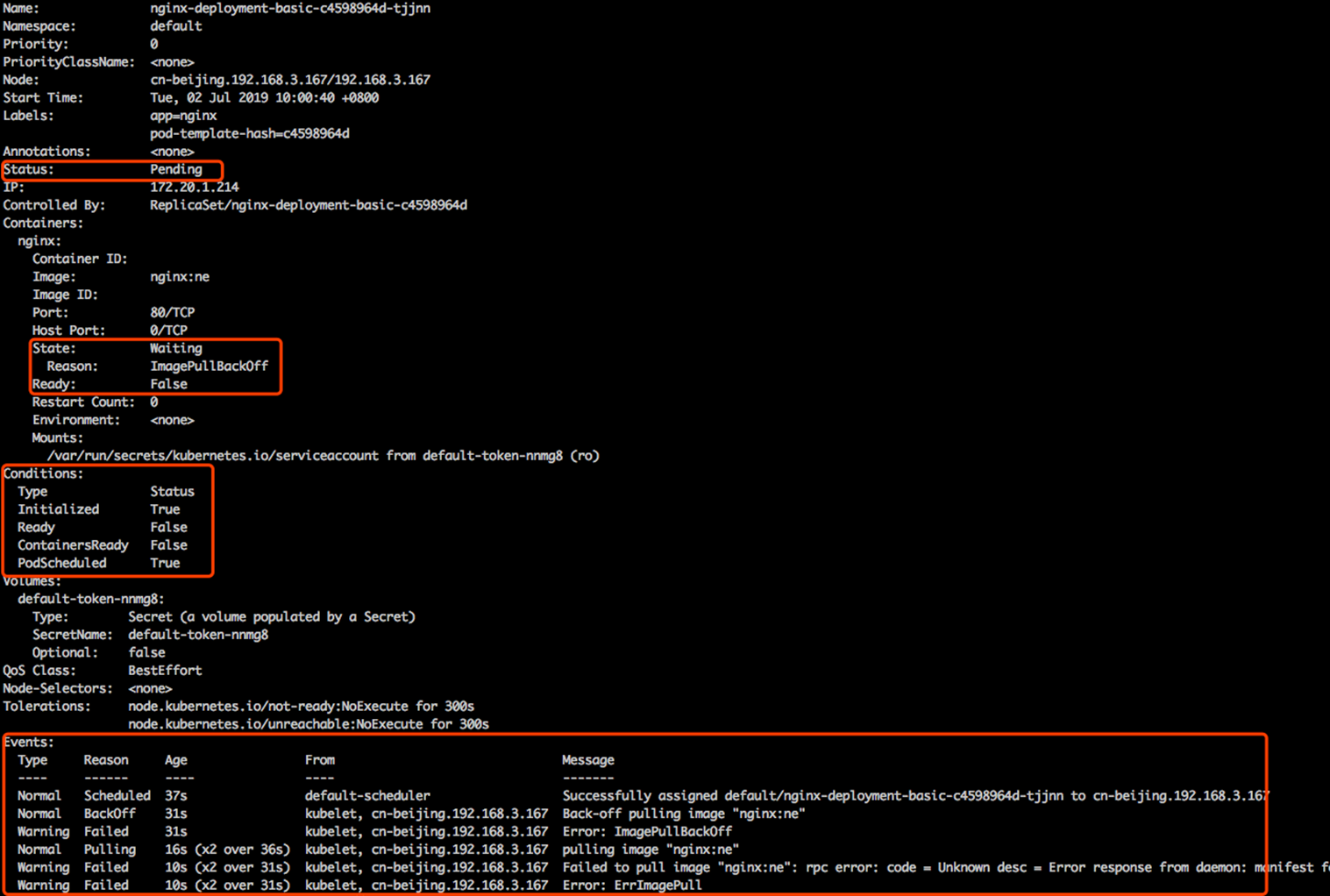
比如說在 Pod 上面有一個字段叫 Status,這個 Status 表示的是 Pod 的一個聚合狀態,在這個里面,這個聚合狀態處在一個 pending 狀態。
然后再往下看,因為一個 pod 里面有多個 container,每個 container 上面又會有一個字段叫 State,然后 State 的狀態表示當前這個 container 的一個聚合狀態。那在這個例子里面,這個聚合狀態處在的是 waiting 的狀態,那具體的原因是因為什么呢?是因為它的鏡像沒有拉下來,所以處在 waiting 的狀態,是在等待這個鏡像拉取。然后這個 ready 的部分呢,目前是 false,因為它這個進行目前沒有拉取下來,所以這個 pod 不能夠正常對外服務,所以此時 ready 的狀態是未知的,定義為 false。如果上層的 endpoint 發現底層這個 ready 不是 true 的話,那么此時這個服務是沒有辦法對外服務的。
再往下是 condition,condition 這個機制表示是說:在 K8s 里面有很多這種比較小的這個狀態,而這個狀態之間的聚合會變成上層的這個 Status。那在這個例子里面有幾個狀態,第一個是 Initialized,表示是不是已經初始化完成?那在這個例子里面已經是初始化完成的,那它走的是第二個階段,是在這個 ready 的狀態。因為上面幾個 container 沒有拉取下來相應的鏡像,所以 ready 的狀態是 false。
然后再往下可以看到這個 container 是否 ready,這里可以看到是 false,而這個狀態是 PodScheduled,表示說當前這個 pod 是否是處在一個已經被調度的狀態,它已經 bound 在現在這個 node 之上了,所以這個狀態也是 true。
那可以通過相應的 condition 是 true 還是 false 來判斷整體上方的這個狀態是否是正常的一個狀態。而在 K8s 里面不同的狀態之間的這個轉換都會發生相應的事件,而事件分為兩種: 一種叫做 normal 的事件,一種是 warning 事件。大家可以看見在這第一條的事件是有個 normal 事件,然后它相應的 reason 是 scheduler,表示說這個 pod 已經被默認的調度器調度到相應的一個節點之上,然后這個節點是 cn-beijing192.168.3.167 這個節點之上。
再接下來,又是一個 normal 的事件,表示說當前的這個鏡像在 pull 相應的這個 image。然后再往下是一個 warning 事件,這個 warning 事件表示說 pull 這個鏡像失敗了。
以此類推,這個地方表示的一個狀態就是說在 K8s 里面這個狀態機制之間這個狀態轉換會產生相應的事件,而這個事件又通過類似像 normal 或者是 warning 的方式進行暴露。開發者可以通過類似像通過這個事件的機制,可以通過上層 condition Status 相應的一系列的這個字段來判斷當前這個應用的具體的狀態以及進行一系列的診斷。
本小節介紹一下常見應用的一些異常。首先是 pod 上面,pod 上面可能會停留幾個常見的狀態。
第一個就是 pending 狀態,pending 表示調度器沒有進行介入。此時可以通過 kubectl describe pod 來查看相應的事件,如果由于資源或者說端口占用,或者是由于 node selector 造成 pod 無法調度的時候,可以在相應的事件里面看到相應的結果,這個結果里面會表示說有多少個不滿足的 node,有多少是因為 CPU 不滿足,有多少是由于 node 不滿足,有多少是由于?tag?打標造成的不滿足。
那第二個狀態就是 pod 可能會停留在 waiting 的狀態,pod 的 states 處在 waiting 的時候,通常表示說這個 pod 的鏡像沒有正常拉取,原因可能是由于這個鏡像是私有鏡像,但是沒有配置 Pod secret;那第二種是說可能由于這個鏡像地址是不存在的,造成這個鏡像拉取不下來;還有一個是說這個鏡像可能是一個公網的鏡像,造成鏡像的拉取失敗。
第三種是 pod 不斷被拉起,而且可以看到類似像 backoff 。這個通常表示說 pod 已經被調度完成了,但是啟動失敗,那這個時候通常要關注的應該是這個應用自身的一個狀態,并不是說配置是否正確、權限是否正確,此時需要查看的應該是 pod 的具體日志。
第四種 pod 處在 running 狀態,但是沒有正常對外服務。那此時比較常見的一個點就可能是由于一些非常細碎的配置,類似像有一些字段可能拼寫錯誤,造成了 yaml 下發下去了,但是有一段沒有正常地生效,從而使得這個 pod 處在 running 的狀態沒有對外服務,那此時可以通過 apply-validate-f pod.yaml 的方式來進行判斷當前 yaml 是否是正常的,如果 yaml 沒有問題,那么接下來可能要診斷配置的端口是否是正常的,以及 Liveness 或 Readiness 是否已經配置正確。
最后一種就是 service 無法正常工作的時候,該怎么去判斷呢?那比較常見的 service 出現問題的時候,是自己的使用上面出現了問題。因為 service 和底層的 pod 之間的關聯關系是通過 selector 的方式來匹配的,也就是說 pod 上面配置了一些 label,然后 service 通過 match label 的方式和這個 pod 進行相互關聯。如果這個 label 配置的有問題,可能會造成這個 service 無法找到后面的 endpoint,從而造成相應的 service 沒有辦法對外提供服務,那如果 service 出現異常的時候,第一個要看的是這個 service 后面是不是有一個真正的 endpoint,其次來看這個 endpoint 是否可以對外提供正常的服務。
本節講解的是在 K8s 里面如何進行應用的遠程調試,遠程調試主要分為 pod 的遠程調試以及 service 的遠程調試。還有就是針對一些性能優化的遠程調試。
首先把一個應用部署到集群里面的時候,發現問題的時候,需要進行快速驗證,或者說修改的時候,可能需要類似像登陸進這個容器來進行一些診斷。

比如說可以通過 exec 的方式進入一個 pod。像這條命令里面,通過 kubectl exec-it pod-name 后面再填寫一個相應的命令,比如說 /bin/bash,表示希望到這個 pod 里面進入一個交互式的一個 bash。然后在 bash 里面可以做一些相應的命令,比如說修改一些配置,通過 supervisor 去重新拉起這個應用,都是可以的。
那如果指定這一個 pod 里面可能包含著多個 container,這個時候該怎么辦呢?怎么通過 pod 來指定 container 呢?其實這個時候有一個參數叫做 -c,如上圖下方的命令所示。-c 后面是一個 container-name,可以通過 pod 在指定 -c 到這個 container-name,具體指定要進入哪個 container,后面再跟上相應的具體的命令,通過這種方式來實現一個多容器的命令的一個進入,從而實現多容器的一個遠程調試。
那么 service 的遠程調試該怎么做呢?service 的遠程調試其實分為兩個部分:
在反向列入上面有這樣一個開源組件,叫做 Telepresence,它可以將本地的應用代理到遠程集群中的一個 service 上面,使用它的方式非常簡單。

首先先將 Telepresence 的一個 Proxy 應用部署到遠程的 K8s 集群里面。然后將遠程單一個 deployment swap 到本地的一個 application,使用的命令就是 Telepresence-swap-deployment 然后以及遠程的 DEPLOYMENT_NAME。通過這種方式就可以將本地一個 application 代理到遠程的 service 之上、可以將應用在遠程集群里面進行本地調試,這個有興趣的同學可以到 GitHub 上面來看一下這個插件的使用的方式。
第二個是如果本地應用需要調用遠程集群的服務時候,可以通過 port-forward 的方式將遠程的應用調用到本地的端口之上。比如說現在遠程的里面有一個 API server,這個 API server 提供了一些端口,本地在調試 Code 時候,想要直接調用這個 API server,那么這時,比較簡單的一個方式就是通過 port-forward 的方式。

它的使用方式是 kubectl port-forward,然后 service 加上遠程的 service name,再加上相應的 namespace,后面還可以加上一些額外的參數,比如說端口的一個映射,通過這種機制就可以把遠程的一個應用代理到本地的端口之上,此時通過訪問本地端口就可以訪問遠程的服務。
最后再給大家介紹一個開源的調試工具,它也是 kubectl 的一個插件,叫 kubectl-debug。我們知道在 K8s 里面,底層的容器 runtime 比較常見的就是類似像 docker 或者是 containerd,不論是 docker 還是 containerd,它們使用的一個機制都是基于 Linux namespace 的一個方式進行虛擬化和隔離的。
通常情況下 ,并不會在鏡像里面帶特別多的調試工具,類似像 netstat telnet 等等這些 ,因為這個會造成應用整體非常冗余。那么如果想要調試的時候該怎么做呢?其實這個時候就可以依賴類似于像 kubectl-debug 這樣一個工具。<br />?<br /> kubectl-debug 這個工具是依賴于 Linux namespace 的方式來去做的,它可以 datash 一個 Linux namespace 到一個額外的 container,然后在這個 container 里面執行任何的 debug 動作,其實和直接去 debug 這個 Linux namespace 是一致的。這里有一個簡單的操作,給大家來介紹一下:
這個地方其實已經安裝好了 kubectl-debug,它是 kubectl 的一個插件。所以這個時候,你可以直接通過 kubectl-debug 這條命令來去診斷遠程的一個 pod。像這個例子里面,當執行 debug 的時候,實際上它首先會先拉取一些鏡像,這個鏡像里面實際上會默認帶一些診斷的工具。當這個鏡像啟用的時候,它會把這個 debug container 進行啟動。與此同時會把這個 container 和相應的你要診斷的這個 container 的 namespace 進行掛靠,也就說此時這個 container 和你是同 namespace 的,類似像網絡站,或者是類似像內核的一些參數,其實都可以在這個 debug container 里面實時地進行查看。
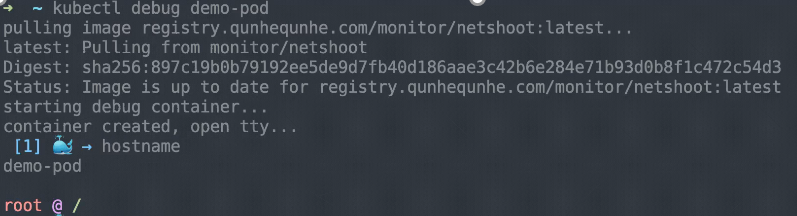
像這個例子里面,去查看類似像 hostname、進程、netstat 等等,這些其實都是和這個需要 debug 的 pod 是在同一個環境里面的,所以你之前這三條命令可以看到里面相關的信息。
如果此時進行 logout 的話,相當于會把相應的這個 debug pod 殺掉,然后進行退出,此時對應用實際上是沒有任何的影響的。那么通過這種方式可以不介入到容器里面,就可以實現相應的一個診斷。

此外它還支持額外的一些機制,比如說我給設定一些 image,然后類似像這里面安裝了的是 htop,然后開發者可以通過這個機制來定義自己需要的這個命令行的工具,并且通過這種 image 的方式設置進來。那么這個時候就可以通過這種機制來調試遠程的一個 pod。
關于 Liveness 和 Readiness 的指針。Liveness probe 就是保活指針,它是用來看 pod 是否存活的,而 Readiness probe 是就緒指針,它是判斷這個 pod 是否就緒的,如果就緒了,就可以對外提供服務。這個就是 Liveness 和 Readiness 需要記住的部分;
應用診斷的三個步驟:首先 describe 相應的一個狀態;然后提供狀態來排查具體的一個診斷方向;最后來查看相應對象的一個 event 獲取更詳細的一個信息;
提供 pod 一個日志來定位應用的自身的一個狀態;
“ 阿里巴巴云原生微信公眾號(ID:Alicloudnative)關注微服務、Serverless、容器、Service Mesh等技術領域、聚焦云原生流行技術趨勢、云原生大規模的落地實踐,做最懂云原生開發者的技術公眾號。”
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





