溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關python中simhash包的使用方法,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
1、simHash簡介
simHash算法是GoogleMoses Charikear于2007年發布的一篇論文《Detecting Near-duplicates for web crawling》中提出的, 專門用來解決億萬級別的網頁去重任務。
simHash是局部敏感哈希(locality sensitve hash)的一種,其主要思想是降維,將高維的特征向量映射成低維的特征向量,再通過比較兩個特征向量的漢明距離(Hamming Distance) 來確定文章之間的相似性。
什么是局部敏感呢?假設A,B具有一定的相似性,在hash之后,仍能保持這種相似性,就稱之為局部敏感hash
漢明距離:
Hamming Distance,又稱漢明距離,在信息論中,等長的兩個字符串之間的漢明距離就是兩個字符串對應位置的不同字符的個數。即將一個字符串變換成另外一個字符串所需要替換的字符個數,可使用異或操作。
例如: 1011與1001之間的漢明距離是1。
2、simHash具體流程
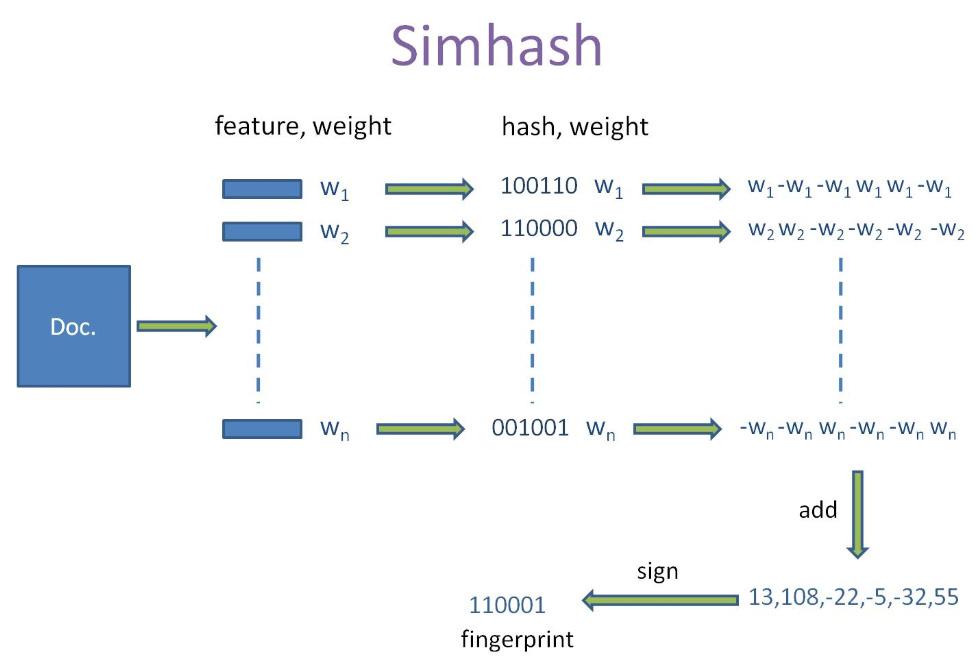
simHash算法總共分為5個流程: 分詞、has、加權、合并、降維。
分詞
對待處理文檔進行中文分詞,得到有效的特征及其權重。可以使用TF-IDF方法獲取一篇文章權重最高的前topK個詞(feature)和權重(weight)。即可使用jieba.analyse.extract_tags()來實現
hash
對獲取的詞(feature),進行普通的哈希操作,計算hash值,這樣就得到一個長度為n位的二進制,得到(hash:weight)的集合。
加權
在獲取的hash值的基礎上,根據對應的weight值進行加權,即W=hash*weight。即hash為1則和weight正相乘,為0則和weight負相乘。例如一個詞經過hash后得到(010111:5)經過步驟(3)之后可以得到列表[-5,5,-5,5,5,5]。
合并
將上述得到的各個向量的加權結果進行求和,變成只有一個序列串。如[-5,5,-5,5,5,5]、[-3,-3,-3,3,-3,3]、[1,-1,-1,1,1,1]進行列向累加得到[-7,1,-9,9,3,9],這樣,我們對一個文檔得到,一個長度為64的列表。
降維
對于得到的n-bit簽名的累加結果的每個值進行判斷,大于0則置為1, 否則置為0,從而得到該語句的simhash值。例如,[-7,1,-9,9,3,9]得到 010111,這樣,我們就得到一個文檔的 simhash值。
最后根據不同語句的simhash值的漢明距離來判斷相似度。
根據經驗值,對64位的 SimHash值,海明距離在3以內的可認為相似度比較高。
3、Python實現simHash
使用Python實現simHash算法,具體如下:
# -*- coding:utf-8 -*-
import jieba
import jieba.analyse
import numpy as np
class SimHash(object):
def simHash(self, content):
seg = jieba.cut(content)
# jieba.analyse.set_stop_words('stopword.txt')
# jieba基于TF-IDF提取關鍵詞
keyWords = jieba.analyse.extract_tags("|".join(seg), topK=10, withWeight=True)
keyList = []
for feature, weight in keyWords:
print('weight: {}'.format(weight))
# weight = math.ceil(weight)
weight = int(weight)
binstr = self.string_hash(feature)
temp=[]
for c in binstr:
if (c == '1'):
temp.append(weight)
else:
temp.append(-weight)
keyList.append(temp)
listSum = np.sum(np.array(keyList), axis = 0)
if (keyList == []):
return '00'
simhash = ''
for i in listSum:
if (i>0):
simhash = simhash + '1'
else:
simhash = simhash + '0'
return simhash
def string_hash(self, source):
if source == "":
return 0
else:
x = ord(source[0]) << 7
m = 1000003
mask = 2**128 - 1
for c in source:
x = ((x*m)^ord(c)) & mask
x ^= len(source)
if x == -1:
x = -2
x = bin(x).replace('0b', '').zfill(64)[-64:]
# print('strint_hash: %s, %s'%(source, x))
return str(x)
def getDistance(self, hashstr1, hashstr2):
'''
計算兩個simhash的漢明距離
'''
length = 0
for index, char in enumerate(hashstr1):
if char == hashstr2[index]:
continue
else:
length += 1
return length
if __name__ == '__main__':
simhash = SimHash()
s1 = simhash.simHash('我想洗照片')
s2 = simhash.simHash('可以洗一張照片嗎')
dis = simhash.getDistance(s1, s2)
print('dis: {}'.format(dis))對于短小的文本,計算相似度并不十分準確,更適用于較長的文本。
關于python中simhash包的使用方法就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





