溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
不懂關于Python的知識點有哪些?其實想解決這個問題也不難,下面讓小編帶著大家一起學習怎么去解決,希望大家閱讀完這篇文章后大所收獲。
No.1 一切皆對象
眾所周知,Java中強調“一切皆對象”,但是Python中的面向對象比Java更加徹底,因為Python中的類(class)也是對象,函數(function)也是對象,而且Python的代碼和模塊也都是對象。
·Python中函數和類可以賦值給一個變量
·Python中函數和類可以存放到集合對象中
·Python中函數和類可以作為一個函數的參數傳遞給函數
·Python中函數和類可以作為返回值
Step.1
# 首先創建一個函數和一個Python3.x的新式類
class Demo(object):
def __init__(self):
print("Demo Class")
# 定義一個函數
def function():
print("function")
# 在Python無論是函數,還是類,都是對象,他們可以賦值給一個變量
class_value = Demo
func_value = function
# 并且可以通過變量調用
class_value() # Demo Class
func_value() # functionStep.2
# 將函數和類添加到集合中 obj_list = [] obj_list.append(Demo) obj_list.append(function) # 遍歷列表 for i in obj_list: print(i) # <class '__main__.Demo'> # <function function at 0x0000020D681B3E18>
Step.3
# 定義一個具體函數 def test_func(class_name, func_name): class_name() func_name() # 將類名和函數名傳入形參列表 test_func(Demo, function) # Demo Class # function
Step.4
# 定義函數實現返回類和函數 def test_func2(): return Demo def test_func3(): return function # 執行函數 test_func2()() # Demo Class test_func3()() # function
No.2 關鍵字type、object、class之間的關系
在Python中,object的實例是type,object是頂層類,沒有基類;type的實例是type,type的基類是object。Python中的內置類型的基類是object,但是他們都是由type實例化而來,具體的值由內置類型實例化而來。在Python2.x的語法中用戶自定義的類沒有明確指定基類就默認是沒有基類,在Python3.x的語法中,指定基類為object。
# object是誰實例化的? print(type(object)) # <class 'type'> # object繼承自哪個類? print(object.__bases__) # () # type是誰實例化的? print(type(type)) # <class 'type'> # type繼承自哪個類? print(type.__bases__) # (<class 'object'>,) # 定義一個變量 value = 100 # 100由誰實例化? print(type(value)) # <class 'int'> # int由誰實例化? print(type(int)) # <class 'type'> # int繼承自哪個類? print(int.__bases__) # (<class 'object'>,) # Python 2.x的舊式類 class OldClass(): pass # Python 3.x的新式類 class NewClass(object): pass
No.3 Python的內置類型
在Python中,對象有3個特征屬性:
·在內存中的地址,使用id()函數進行查看
·對象的類型
·對象的默認值
Step.1 None類型
在Python解釋器啟動時,會創建一個None類型的None對象,并且None對象全局只有一個。
Step.2 數值類型
·ini類型
·float類型
·complex類型
·bool類型
Step.3 迭代類型
在Python中,迭代類型可以使用循環來進行遍歷。
Step.4 序列類型
·list
·tuple
·str
·array
·range
·bytes, bytearray, memoryvie(二進制序列)
Step.5 映射類型
dict
Step.6 集合類型
·set
·frozenset
Step.7 上下文管理類型
with語句
Step.8 其他類型
·模塊
·class
·實例
·函數
·方法
·代碼
·object對象
·type對象
·ellipsis(省略號)
·notimplemented
NO.4 魔法函數
Python中的魔法函數使用雙下劃線開始,以雙下劃線結尾。關于詳細介紹請看我的文章——《全面總結Python中的魔法函數》。
No.5 鴨子類型與白鵝類型
鴨子類型是程序設計中的推斷風格,在鴨子類型中關注對象如何使用而不是類型本身。鴨子類型像多態一樣工作但是沒有繼承。鴨子類型的概念來自于:“當看到一只鳥走起來像鴨子、游泳起來像鴨子、叫起來也像鴨子,那么這只鳥就可以被稱為鴨子。”
# 定義狗類
class Dog(object):
def eat(self):
print("dog is eatting...")
# 定義貓類
class Cat(object):
def eat(self):
print("cat is eatting...")
# 定義鴨子類
class Duck(object):
def eat(self):
print("duck is eatting...")
# 以上Python中多態的體現
# 定義動物列表
an_li = []
# 將動物添加到列表
an_li.append(Dog)
an_li.append(Cat)
an_li.append(Duck)
# 依次調用每個動物的eat()方法
for i in an_li:
i().eat()
# dog is eatting...
# cat is eatting...
# duck is eatting...白鵝類型是指只要 cls 是抽象基類,即 cls 的元類是 abc.ABCMeta ,就可以使用 isinstance(obj, cls)。
No.6 協議、 抽象基類、abc模塊和序列之間的繼承關系
協議:Python中的非正式接口,是允許Python實現多態的方式,協議是非正式的,不具備強制性,由約定和文檔定義。
接口:泛指實體把自己提供給外界的一種抽象化物(可以為另一實體),用以由內部操作分離出外部溝通方法,使其能被內部修改而不影響外界其他實體與其交互的方式。
我們可以使用猴子補丁來實現協議,那么什么是猴子補丁呢?
猴子補丁就是在運行時修改模塊或類,不去修改源代碼,從而實現目標協議接口操作,這就是所謂的打猴子補丁。
Tips:猴子補丁的叫法起源于Zope框架,開發人員在修改Zope的Bug時,經常在程序后面追加更新的部分,這些雜牌軍補丁的英文名字叫做guerilla patch,后來寫成gorllia,接著就變成了monkey。
猴子補丁的主要作用是:
·在運行時替換方法、屬性;
·在不修改源代碼的情況下對程序本身添加之前沒有的功能;
·在運行時對象中添加補丁,而不是在磁盤中的源代碼上。
應用案例:假設寫了一個很大的項目,處處使用了json模塊來解析json文件,但是后來發現ujson比json性能更高,修改源代碼是要修改很多處的,所以只需要在程序入口加入:
import json # pip install ujson import ujson def monkey_patch_json(): json.__name__ = 'ujson' json.dumps = ujson.dumps json.loads = ujson.loads monkey_patch_json()
Python 的抽象基類有一個重要實用優勢:可以使用 register 類方法在終端用戶的代碼中把某個類 “聲明” 為一個抽象基類的 “虛擬” 子 類(為此,被注冊的類必腨滿足抽象其類對方法名稱和簽名的要求,最重要的是要滿足底 層語義契約;但是,開發那個類時不用了解抽象基類,更不用繼承抽象基類 。有時,為了讓抽象類識別子類,甚至不用注冊。要抑制住創建抽象基類的沖動。濫用抽象基類會造成災難性后果,表明語言太注重表面形式 。
·抽象基類不能被實例化(不能創建對象),通常是作為基類供子類繼承,子類中重寫虛函數,實現具體的接口。
·判定某個對象的類型
·強制子類必須實現某些方法
抽象基類的定義與使用
import abc # 定義緩存類 class Cache(metaclass=abc.ABCMeta): @abc.abstractmethod def get(self, key): pass @abc.abstractmethod def set(self, key, value): pass # 定義redis緩存類實現Cache類中的get()和set()方法 class RedisCache(Cache): def set(self, key): pass def get(self, key, value): pass
值得注意的是:Python 3.0-Python3.3之間,繼承抽象基類的語法是class ClassName(metaclass=adc.ABCMeta),其他版本是:class ClassName(abc.ABC)。
collections.abc模塊中各個抽象基類的UML類圖
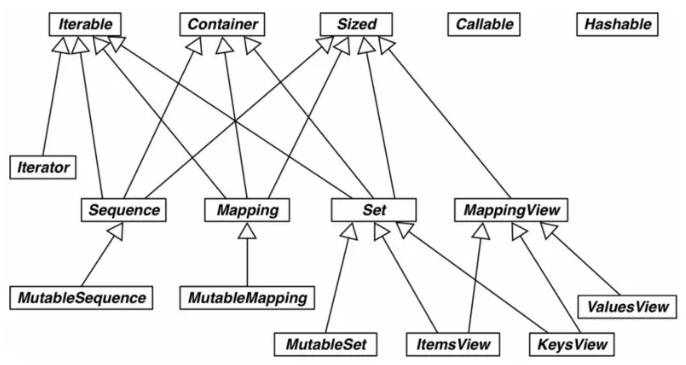
No.7 isinstence和type的區別
class A(object): pass class B(A): pass b = B() print(isinstance(b, B)) print(isinstance(b, A)) print(type(b) is B) print(type(b) is A) # True # True # True # False
No.8 類變量和實例變量
·實例變量只能通過類的實例進行調用
·修改模板對象創建的對象的屬性,模板對象的屬性不會改變
·修改模板對象的屬性,由模板對象創建的對象的屬性會改變
# 此處的類也是模板對象,Python中一切皆對象 class A(object): #類變量 number = 12 def __init__(self): # 實例變量 self.number_2 = 13 # 實例變量只能通過類的實例進行調用 print(A.number) # 12 print(A().number) # 12 print(A().number_2) # 13 # 修改模板對象創建的對象的屬性,模板對象的屬性不會改變 a = A() a.number = 18 print(a.number) # 18 print(A().number) # 12 print(A.number) # 12 # 修改模板對象的屬性,由模板對象創建的對象的屬性會改變 A.number = 19 print(A.number) # 19 print(A().number) # 19
No.9 類和實例屬性以及方法的查找順序
在Python 2.2之前只有經典類,到Python2.7還會兼容經典類,Python3.x以后只使用新式類,Python之前版本也會兼容新式類
Python 2.2 及其之前類沒有基類,Python新式類需要顯式繼承自object,即使不顯式繼承也會默認繼承自object
經典類在類多重繼承的時候是采用從左到右深度優先原則匹配方法的.而新式類是采用C3算法
經典類沒有MRO和instance.mro()調用的
假定存在以下繼承關系:
class D(object): def say_hello(self): pass class E(object): pass class B(D): pass class C(E): pass class A(B, C): pass
采用DFS(深度優先搜索算法)當調用了A的say_hello()方法的時候,系統會去B中查找如果B中也沒有找到,那么去D中查找,很顯然D中存在這個方法,但是DFS對于以下繼承關系就會有缺陷:
class D(object): pass class B(D): pass class C(D): def say_hello(self): pass class A(B, C): pass
在A的實例對象中調用say_hello方法時,系統會先去B中查找,由于B類中沒有該方法的定義,所以會去D中查找,D類中也沒有,系統就會認為該方法沒有定義,其實該方法在C中定義了。所以考慮使用BFS(廣度優先搜索算法),那么問題回到第一個繼承關系,假定C和D具備重名方法,在調用A的實例的方法時,應該先在B中查找,理應調用D中的方法,但是使用BFS的時候,C類中的方法會覆蓋D類中的方法。在Python 2.3以后的版本中,使用C3算法:
# 獲取解析順序的方法 類名.mro() 類名.__mro__ inspect.getmro(類名)
使用C3算法后的第二種繼承順序:
class D(object): pass class B(D): pass class C(D): def say_hello(self): pass class A(B, C): pass print(A.mro()) # [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class 'object'>]
使用C3算法后的第一種繼承順序:
class D(object): pass class E(object): pass class B(D): pass class C(E): pass class A(B, C): pass print(A.mro()) # [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.D'>, <class '__main__.C'>, <class '__main__.E'>, <class 'object'>]
在這里僅介紹了算法的作用和演變歷史,關于深入詳細解析,請看我的其他文章——《從Python繼承談起,到C3算法落筆》。
No.10 類方法、實例方法和靜態方法
class Demo(object): # 類方法 @classmethod def class_method(cls, number): pass # 靜態方法 @staticmethod def static_method(number): pass # 對象方法/實例方法 def object_method(self, number): pass
實例方法只能通過類的實例來調用;靜態方法是一個獨立的、無狀態的函數,緊緊依托于所在類的命名空間上;類方法在為了獲取類中維護的數據,比如:
class Home(object): # 房間中人數 __number = 0 @classmethod def add_person_number(cls): cls.__number += 1 @classmethod def get_person_number(cls): return cls.__number def __new__(self): Home.add_person_number() # 重寫__new__方法,調用object的__new__ return super().__new__(self) class Person(Home): def __init__(self): # 房間人員姓名 self.name = 'name' # 創建人員對象時調用Home的__new__()方法 tom = Person() print(type(tom)) # <class '__main__.Person'> alice = Person() bob = Person() test = Person() print(Home.get_person_number())
No.11 數據封裝和私有屬性
Python中使用雙下劃線+屬性名稱實現類似于靜態語言中的private修飾來實現數據封裝。
class User(object): def __init__(self, number): self.__number = number self.__number_2 = 0 def set_number(self, number): self.__number = number def get_number(self): return self.__number def set_number_2(self, number2): self.__number_2 = number2 # self.__number2 = number2 def get_number_2(self): return self.__number_2 # return self.__number2 u = User(25) print(u.get_number()) # 25 # 真的類似于Java的反射機制嗎? print(u._User__number) # 25 # 下面又是啥情況。。。想不明白了T_T u.set_number_2(18) print(u.get_number_2()) # 18 print(u._User__number_2) # Anaconda 3.6.3 第一次是:u._User__number_2 第二次是:18 # Anaconda 3.6.5 結果都是 0 # 代碼我改成了正確答案,感謝我大哥給我指正錯誤,我保留了錯誤痕跡 # 變量名稱寫錯了,算是個寫博客突發事故,這問題我找了一天,萬分感謝我大哥,我太傻B了,犯了低級錯誤 # 留給和我一樣的童鞋參考我的錯我之處吧! # 正確結果: # 25 25 18 18
No.12 Python的自省機制
自省(introspection)是一種自我檢查行為。在計算機編程中,自省是指這種能力:檢查某些事物以確定它是什么、它知道什么以及它能做什么。自省向程序員提供了極大的靈活性和控制力。
dir([obj]):返回傳遞給它的任何對象的屬性名稱經過排序的列表(會有一些特殊的屬性不包含在內)
getattr(obj, attr):返回任意對象的任何屬性 ,調用這個方法將返回obj中名為attr值的屬性的值
... ...
No.13 super函數
Python3.x 和 Python2.x 的一個區別是: Python 3 可以使用直接使用 super().xxx 代替 super(type[, object-or-type]).xxx 。
super()函數用來調用MRO(類方法解析順序表)的下一個類的方法。
No.14 Mixin繼承
在設計上將Mixin類作為功能混入繼承自Mixin的類。使用Mixin類實現多重繼承應該注意:
Mixin類必須表示某種功能
職責單一,如果要有多個功能,就要設計多個Mixin類
不依賴子類實現,Mixin類的存在僅僅是增加了子類的功能特性
即使子類沒有繼承這個Mixin類也可以工作
class Cat(object):
def eat(self):
print("I can eat.")
def drink(self):
print("I can drink.")
class CatFlyMixin(object):
def fly(self):
print("I can fly.")
class CatJumpMixin(object):
def jump(self):
print("I can jump.")
class TomCat(Cat, CatFlyMixin):
pass
class PersianCat(Cat, CatFlyMixin, CatJumpMixin):
pass
if __name__ == '__main__':
# 湯姆貓沒有跳躍功能
tom = TomCat()
tom.fly()
tom.eat()
tom.drink()
# 波斯貓混入了跳躍功能
persian = PersianCat()
persian.drink()
persian.eat()
persian.fly()
persian.jump()No.15 上下文管理器with語句與contextlib簡化
普通的異常捕獲機制:
try: pass except Exception as err: pass else: pass finally: pass
with簡化了異常捕獲寫法:
class Demo(object):
def __enter__(self):
print("enter...")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print("exit...")
def echo_hello(self):
print("Hello, Hello...")
with Demo() as d:
d.echo_hello()
# enter...
# Hello, Hello...
# exit...
import contextlib
# 使用裝飾器
@contextlib.contextmanager
def file_open(file_name):
# 此處寫__enter___函數中定義的代碼
print("enter function code...")
yield {}
# 此處寫__exit__函數中定義的代碼
print("exit function code...")
with file_open("json.json") as f:
pass
# enter function code...
# exit function code...No.16 序列類型的分類
容器序列:list tuple deque
扁平序列:str bytes bytearray array.array
可變序列:list deque bytearray array
不可變序列:str tuple bytes
No.17 +、+=、extend()之間的區別于應用場景
首先看測試用例:
# 創建一個序列類型的對象 my_list = [1, 2, 3] # 將現有的序列合并到my_list extend_my_list = my_list + [4, 5] print(extend_my_list) # [1, 2, 3, 4, 5] # 將一個元組合并到這個序列 extend_my_list = my_list + (6, 7) # 拋出異常 TypeError: can only concatenate list (not "tuple") to list print(extend_my_list) # 使用另一種方式合并 extend_my_list += (6, 7) print(extend_my_list) # [1, 2, 3, 4, 5, 6, 7] # 使用extend()函數進行合并 extend_my_list.extend((7, 8)) print(extend_my_list) # [1, 2, 3, 4, 5, 6, 7, 7, 8]
由源代碼片段可知:
class MutableSequence(Sequence): __slots__ = () """All the operations on a read-write sequence. Concrete subclasses must provide __new__ or __init__, __getitem__, __setitem__, __delitem__, __len__, and insert(). """ # extend()方法內部使用for循環來append()元素,它接收一個可迭代序列 def extend(self, values): 'S.extend(iterable) -- extend sequence by appending elements from the iterable' for v in values: self.append(v) # 調用 += 運算的時候就是調用該函數,這個函數內部調用extend()方法 def __iadd__(self, values): self.extend(values) return self
No.18 使用bisect維護一個已排序的序列
import bisect my_list = [] bisect.insort(my_list, 2) bisect.insort(my_list, 9) bisect.insort(my_list, 5) bisect.insort(my_list, 5) bisect.insort(my_list, 1) # insort()函數返回接收的元素應該插入到指定序列的索引位置 print(my_list) # [1, 2, 5, 5, 9]
No.19 deque類詳解
deque是Python中一個雙端隊列,能在隊列兩端以的效率插入數據,位于collections模塊中。
from collections import deque # 定義一個雙端隊列,長度為3 d = deque(maxlen=3) deque類的源碼: class deque(object): """ deque([iterable[, maxlen]]) --> deque object 一個類似列表的序列,用于對其端點附近的數據訪問進行優化。 """ def append(self, *args, **kwargs): """ 在隊列右端添加數據 """ pass def appendleft(self, *args, **kwargs): """ 在隊列左端添加數據 """ pass def clear(self, *args, **kwargs): """ 清空所有元素 """ pass def copy(self, *args, **kwargs): """ 淺拷貝一個雙端隊列 """ pass def count(self, value): """ 統計指定value值的出現次數 """ return 0 def extend(self, *args, **kwargs): """ 使用迭代的方式擴展deque的右端 """ pass def extendleft(self, *args, **kwargs): """ 使用迭代的方式擴展deque的左端 """ pass def index(self, value, start=None, stop=None): __doc__ """ 返回第一個符合條件的索引的值 """ return 0 def insert(self, index, p_object): """ 在指定索引之前插入 """ pass def pop(self, *args, **kwargs): # real signature unknown """ 刪除并返回右端的一個元素 """ pass def popleft(self, *args, **kwargs): # real signature unknown """ 刪除并返回左端的一個元素 """ pass def remove(self, value): # real signature unknown; restored from __doc__ """ 刪除第一個與value相同的值 """ pass def reverse(self): # real signature unknown; restored from __doc__ """ 翻轉隊列 """ pass def rotate(self, *args, **kwargs): # real signature unknown """ 向右旋轉deque N步, 如果N是個負數,那么向左旋轉N的絕對值步 """ pass def __add__(self, *args, **kwargs): # real signature unknown """ Return self+value. """ pass def __bool__(self, *args, **kwargs): # real signature unknown """ self != 0 """ pass def __contains__(self, *args, **kwargs): # real signature unknown """ Return key in self. """ pass def __copy__(self, *args, **kwargs): # real signature unknown """ Return a shallow copy of a deque. """ pass def __delitem__(self, *args, **kwargs): # real signature unknown """ Delete self[key]. """ pass def __eq__(self, *args, **kwargs): # real signature unknown """ Return self==value. """ pass def __getattribute__(self, *args, **kwargs): # real signature unknown """ Return getattr(self, name). """ pass def __getitem__(self, *args, **kwargs): # real signature unknown """ Return self[key]. """ pass def __ge__(self, *args, **kwargs): # real signature unknown """ Return self>=value. """ pass def __gt__(self, *args, **kwargs): # real signature unknown """ Return self>value. """ pass def __iadd__(self, *args, **kwargs): # real signature unknown """ Implement self+=value. """ pass def __imul__(self, *args, **kwargs): # real signature unknown """ Implement self*=value. """ pass def __init__(self, iterable=(), maxlen=None): # known case of _collections.deque.__init__ """ deque([iterable[, maxlen]]) --> deque object A list-like sequence optimized for data accesses near its endpoints. # (copied from class doc) """ pass def __iter__(self, *args, **kwargs): # real signature unknown """ Implement iter(self). """ pass def __len__(self, *args, **kwargs): # real signature unknown """ Return len(self). """ pass def __le__(self, *args, **kwargs): # real signature unknown """ Return self<=value. """ pass def __lt__(self, *args, **kwargs): # real signature unknown """ Return self<value. """ pass def __mul__(self, *args, **kwargs): # real signature unknown """ Return self*value.n """ pass @staticmethod # known case of __new__ def __new__(*args, **kwargs): # real signature unknown """ Create and return a new object. See help(type) for accurate signature. """ pass def __ne__(self, *args, **kwargs): # real signature unknown """ Return self!=value. """ pass def __reduce__(self, *args, **kwargs): # real signature unknown """ Return state information for pickling. """ pass def __repr__(self, *args, **kwargs): # real signature unknown """ Return repr(self). """ pass def __reversed__(self): # real signature unknown; restored from __doc__ """ D.__reversed__() -- return a reverse iterator over the deque """ pass def __rmul__(self, *args, **kwargs): # real signature unknown """ Return self*value. """ pass def __setitem__(self, *args, **kwargs): # real signature unknown """ Set self[key] to value. """ pass def __sizeof__(self): # real signature unknown; restored from __doc__ """ D.__sizeof__() -- size of D in memory, in bytes """ pass maxlen = property(lambda self: object(), lambda self, v: None, lambda self: None) # default """maximum size of a deque or None if unbounded""" __hash__ = None
No.20 列表推導式、生成器表達式、字典推導式
列表推導式
列表生成式要比操作列表效率高很多,但是列表生成式的濫用會導致代碼可讀性降低,并且列表生成式可以替換map()和reduce()函數。
# 構建列表 my_list = [x for x in range(9)] print(my_list) # [0, 1, 2, 3, 4, 5, 6, 7, 8] # 構建0-8中為偶數的列表 my_list = [x for x in range(9) if(x%2==0)] print(my_list) # [0, 2, 4, 6, 8] # 構建0-8為奇數的列表,并將每個數字做平方運算 def function(number): return number * number my_list = [function(x) for x in range(9) if x%2!=0] print(my_list) # [1, 9, 25, 49]
生成器表達式
生成器表達式就是把列表表達式的中括號變成小括號。
# 構造一個生成器 gen = (i for i in range(9)) # 生成器可以被遍歷 for i in gen: print(i)
生成器可以使用list()函數轉換為列表:
# 將生成器轉換為列表 li = list(gen) print(li)
字典推導式
d = {
'tom': 18,
'alice': 16,
'bob': 20,
}
dict = {key: value for key, value in d.items()}
print(dict) # {'tom': 18, 'alice': 16, 'bob': 20}Set集合推導式
my_set = {i for i in range(9)}
print(my_set) # {0, 1, 2, 3, 4, 5, 6, 7, 8}No.21 Set與Dict的實現原理
Set和Dict的背后實現都是Hash(哈希)表,有的書本上也較散列表。Hash表原理可以參考我的算法與數學博客欄目,下面給出幾點總結:
Set和Dict的效率高于List。
Se和Dict的Key必須是可哈希的元素。
在Python中,不可變對象都是可哈希的,比如:str、fronzenset、tuple,需要實現__hash__()函數。
Dict內存空間占用多,但是速度快,Python中自定義對象或Python內部對象都是Dict包裝的。
Dict和Set的元素存儲順序和元素的添加順序有關,但是添加元素時有可能改變已有的元素順序。
List會隨著元素數量的增加,查找元素的時間也會增大。
Dict和Set不會隨著元素數量的增加而查找時間延長。
No.22 Python中的集合類模塊collections
defaultdict
defaultdict在dict的基礎上添加了default_factroy方法,它的作用是當key不存在的時候自動生成相應類型的value,defalutdict參數可以指定成list、set、int等各種類型。
應用場景:
from collections import defaultdict
my_list = [
("Tom", 18),
("Tom", 20),
("Alice", 15),
("Bob", 21),
]
def_dict = defaultdict(list)
for key, val in my_list:
def_dict[key].append(val)
print(def_dict.items())
# dict_items([('Tom', [18, 20]), ('Alice', [15]), ('Bob', [21])])
# 如果不考慮重復元素可以使用如下方式
def_dict_2 = defaultdict(set)
for key, val in my_list:
def_dict_2[key].add(val)
print(def_dict_2.items())
# dict_items([('Tom', {18, 20}), ('Alice', {15}), ('Bob', {21})])源碼:
class defaultdict(Dict[_KT, _VT], Generic[_KT, _VT]): default_factory = ... # type: Callable[[], _VT] @overload def __init__(self, **kwargs: _VT) -> None: ... @overload def __init__(self, default_factory: Optional[Callable[[], _VT]]) -> None: ... @overload def __init__(self, default_factory: Optional[Callable[[], _VT]], **kwargs: _VT) -> None: ... @overload def __init__(self, default_factory: Optional[Callable[[], _VT]], map: Mapping[_KT, _VT]) -> None: ... @overload def __init__(self, default_factory: Optional[Callable[[], _VT]], map: Mapping[_KT, _VT], **kwargs: _VT) -> None: ... @overload def __init__(self, default_factory: Optional[Callable[[], _VT]], iterable: Iterable[Tuple[_KT, _VT]]) -> None: ... @overload def __init__(self, default_factory: Optional[Callable[[], _VT]], iterable: Iterable[Tuple[_KT, _VT]], **kwargs: _VT) -> None: ... def __missing__(self, key: _KT) -> _VT: ... # TODO __reversed__ def copy(self: _DefaultDictT) -> _DefaultDictT: ...
OrderedDict
OrderDict最大的特點就是元素位置有序,它是dict的子類。OrderDict在內部維護一個字典元素的有序列表。
應用場景:
from collections import OrderedDict
my_dict = {
"Bob": 20,
"Tim": 20,
"Amy": 18,
}
# 通過key來排序
order_dict = OrderedDict(sorted(my_dict.items(), key=lambda li: li[1]))
print(order_dict) # OrderedDict([('Amy', 18), ('Bob', 20), ('Tim', 20)])源碼:
class OrderedDict(dict):
'Dictionary that remembers insertion order'
# An inherited dict maps keys to values.
# The inherited dict provides __getitem__, __len__, __contains__, and get.
# The remaining methods are order-aware.
# Big-O running times for all methods are the same as regular dictionaries.
# The internal self.__map dict maps keys to links in a doubly linked list.
# The circular doubly linked list starts and ends with a sentinel element.
# The sentinel element never gets deleted (this simplifies the algorithm).
# The sentinel is in self.__hardroot with a weakref proxy in self.__root.
# The prev links are weakref proxies (to prevent circular references).
# Individual links are kept alive by the hard reference in self.__map.
# Those hard references disappear when a key is deleted from an OrderedDict.
def __init__(*args, **kwds):
'''Initialize an ordered dictionary. The signature is the same as
regular dictionaries. Keyword argument order is preserved.
'''
if not args:
raise TypeError("descriptor '__init__' of 'OrderedDict' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError('expected at most 1 arguments, got %d' % len(args))
try:
self.__root
except AttributeError:
self.__hardroot = _Link()
self.__root = root = _proxy(self.__hardroot)
root.prev = root.next = root
self.__map = {}
self.__update(*args, **kwds)
def __setitem__(self, key, value,
dict_setitem=dict.__setitem__, proxy=_proxy, Link=_Link):
'od.__setitem__(i, y) <==> od[i]=y'
# Setting a new item creates a new link at the end of the linked list,
# and the inherited dictionary is updated with the new key/value pair.
if key not in self:
self.__map[key] = link = Link()
root = self.__root
last = root.prev
link.prev, link.next, link.key = last, root, key
last.next = link
root.prev = proxy(link)
dict_setitem(self, key, value)
def __delitem__(self, key, dict_delitem=dict.__delitem__):
'od.__delitem__(y) <==> del od[y]'
# Deleting an existing item uses self.__map to find the link which gets
# removed by updating the links in the predecessor and successor nodes.
dict_delitem(self, key)
link = self.__map.pop(key)
link_prev = link.prev
link_next = link.next
link_prev.next = link_next
link_next.prev = link_prev
link.prev = None
link.next = None
def __iter__(self):
'od.__iter__() <==> iter(od)'
# Traverse the linked list in order.
root = self.__root
curr = root.next
while curr is not root:
yield curr.key
curr = curr.next
def __reversed__(self):
'od.__reversed__() <==> reversed(od)'
# Traverse the linked list in reverse order.
root = self.__root
curr = root.prev
while curr is not root:
yield curr.key
curr = curr.prev
def clear(self):
'od.clear() -> None. Remove all items from od.'
root = self.__root
root.prev = root.next = root
self.__map.clear()
dict.clear(self)
def popitem(self, last=True):
'''Remove and return a (key, value) pair from the dictionary.
Pairs are returned in LIFO order if last is true or FIFO order if false.
'''
if not self:
raise KeyError('dictionary is empty')
root = self.__root
if last:
link = root.prev
link_prev = link.prev
link_prev.next = root
root.prev = link_prev
else:
link = root.next
link_next = link.next
root.next = link_next
link_next.prev = root
key = link.key
del self.__map[key]
value = dict.pop(self, key)
return key, value
def move_to_end(self, key, last=True):
'''Move an existing element to the end (or beginning if last==False).
Raises KeyError if the element does not exist.
When last=True, acts like a fast version of self[key]=self.pop(key).
'''
link = self.__map[key]
link_prev = link.prev
link_next = link.next
soft_link = link_next.prev
link_prev.next = link_next
link_next.prev = link_prev
root = self.__root
if last:
last = root.prev
link.prev = last
link.next = root
root.prev = soft_link
last.next = link
else:
first = root.next
link.prev = root
link.next = first
first.prev = soft_link
root.next = link
def __sizeof__(self):
sizeof = _sys.getsizeof
n = len(self) + 1 # number of links including root
size = sizeof(self.__dict__) # instance dictionary
size += sizeof(self.__map) * 2 # internal dict and inherited dict
size += sizeof(self.__hardroot) * n # link objects
size += sizeof(self.__root) * n # proxy objects
return size
update = __update = MutableMapping.update
def keys(self):
"D.keys() -> a set-like object providing a view on D's keys"
return _OrderedDictKeysView(self)
def items(self):
"D.items() -> a set-like object providing a view on D's items"
return _OrderedDictItemsView(self)
def values(self):
"D.values() -> an object providing a view on D's values"
return _OrderedDictValuesView(self)
__ne__ = MutableMapping.__ne__
__marker = object()
def pop(self, key, default=__marker):
'''od.pop(k[,d]) -> v, remove specified key and return the corresponding
value. If key is not found, d is returned if given, otherwise KeyError
is raised.
'''
if key in self:
result = self[key]
del self[key]
return result
if default is self.__marker:
raise KeyError(key)
return default
def setdefault(self, key, default=None):
'od.setdefault(k[,d]) -> od.get(k,d), also set od[k]=d if k not in od'
if key in self:
return self[key]
self[key] = default
return default
@_recursive_repr()
def __repr__(self):
'od.__repr__() <==> repr(od)'
if not self:
return '%s()' % (self.__class__.__name__,)
return '%s(%r)' % (self.__class__.__name__, list(self.items()))
def __reduce__(self):
'Return state information for pickling'
inst_dict = vars(self).copy()
for k in vars(OrderedDict()):
inst_dict.pop(k, None)
return self.__class__, (), inst_dict or None, None, iter(self.items())
def copy(self):
'od.copy() -> a shallow copy of od'
return self.__class__(self)
@classmethod
def fromkeys(cls, iterable, value=None):
'''OD.fromkeys(S[, v]) -> New ordered dictionary with keys from S.
If not specified, the value defaults to None.
'''
self = cls()
for key in iterable:
self[key] = value
return self
def __eq__(self, other):
'''od.__eq__(y) <==> od==y. Comparison to another OD is order-sensitive
while comparison to a regular mapping is order-insensitive.
'''
if isinstance(other, OrderedDict):
return dict.__eq__(self, other) and all(map(_eq, self, other))
return dict.__eq__(self, other)deque
list存儲數據的時候,內部實現是數組,數組的查找速度是很快的,但是插入和刪除數據的速度堪憂。deque雙端列表內部實現是雙端隊列。deuque適用隊列和棧,并且是線程安全的。
deque提供append()和pop()函數實現在deque尾部添加和彈出數據,提供appendleft()和popleft()函數實現在deque頭部添加和彈出元素。這4個函數的時間復雜度都是的,但是list的時間復雜度高達。
創建deque隊列
from collections import deque # 創建一個隊列長度為20的deque dQ = deque(range(10), maxlen=20) print(dQ) # deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=20)
源碼
class deque(object): """ deque([iterable[, maxlen]]) --> deque object A list-like sequence optimized for data accesses near its endpoints. """ def append(self, *args, **kwargs): # real signature unknown """ Add an element to the right side of the deque. """ pass def appendleft(self, *args, **kwargs): # real signature unknown """ Add an element to the left side of the deque. """ pass def clear(self, *args, **kwargs): # real signature unknown """ Remove all elements from the deque. """ pass def copy(self, *args, **kwargs): # real signature unknown """ Return a shallow copy of a deque. """ pass def count(self, value): # real signature unknown; restored from __doc__ """ D.count(value) -> integer -- return number of occurrences of value """ return 0 def extend(self, *args, **kwargs): # real signature unknown """ Extend the right side of the deque with elements from the iterable """ pass def extendleft(self, *args, **kwargs): # real signature unknown """ Extend the left side of the deque with elements from the iterable """ pass def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__ """ D.index(value, [start, [stop]]) -> integer -- return first index of value. Raises ValueError if the value is not present. """ return 0 def insert(self, index, p_object): # real signature unknown; restored from __doc__ """ D.insert(index, object) -- insert object before index """ pass def pop(self, *args, **kwargs): # real signature unknown """ Remove and return the rightmost element. """ pass def popleft(self, *args, **kwargs): # real signature unknown """ Remove and return the leftmost element. """ pass def remove(self, value): # real signature unknown; restored from __doc__ """ D.remove(value) -- remove first occurrence of value. """ pass def reverse(self): # real signature unknown; restored from __doc__ """ D.reverse() -- reverse *IN PLACE* """ pass def rotate(self, *args, **kwargs): # real signature unknown """ Rotate the deque n steps to the right (default n=1). If n is negative, rotates left. """ pass def __add__(self, *args, **kwargs): # real signature unknown """ Return self+value. """ pass def __bool__(self, *args, **kwargs): # real signature unknown """ self != 0 """ pass def __contains__(self, *args, **kwargs): # real signature unknown """ Return key in self. """ pass def __copy__(self, *args, **kwargs): # real signature unknown """ Return a shallow copy of a deque. """ pass def __delitem__(self, *args, **kwargs): # real signature unknown """ Delete self[key]. """ pass def __eq__(self, *args, **kwargs): # real signature unknown """ Return self==value. """ pass def __getattribute__(self, *args, **kwargs): # real signature unknown """ Return getattr(self, name). """ pass def __getitem__(self, *args, **kwargs): # real signature unknown """ Return self[key]. """ pass def __ge__(self, *args, **kwargs): # real signature unknown """ Return self>=value. """ pass def __gt__(self, *args, **kwargs): # real signature unknown """ Return self>value. """ pass def __iadd__(self, *args, **kwargs): # real signature unknown """ Implement self+=value. """ pass def __imul__(self, *args, **kwargs): # real signature unknown """ Implement self*=value. """ pass def __init__(self, iterable=(), maxlen=None): # known case of _collections.deque.__init__ """ deque([iterable[, maxlen]]) --> deque object A list-like sequence optimized for data accesses near its endpoints. # (copied from class doc) """ pass def __iter__(self, *args, **kwargs): # real signature unknown """ Implement iter(self). """ pass def __len__(self, *args, **kwargs): # real signature unknown """ Return len(self). """ pass def __le__(self, *args, **kwargs): # real signature unknown """ Return self<=value. """ pass def __lt__(self, *args, **kwargs): # real signature unknown """ Return self<value. """ pass def __mul__(self, *args, **kwargs): # real signature unknown """ Return self*value.n """ pass @staticmethod # known case of __new__ def __new__(*args, **kwargs): # real signature unknown """ Create and return a new object. See help(type) for accurate signature. """ pass def __ne__(self, *args, **kwargs): # real signature unknown """ Return self!=value. """ pass def __reduce__(self, *args, **kwargs): # real signature unknown """ Return state information for pickling. """ pass def __repr__(self, *args, **kwargs): # real signature unknown """ Return repr(self). """ pass def __reversed__(self): # real signature unknown; restored from __doc__ """ D.__reversed__() -- return a reverse iterator over the deque """ pass def __rmul__(self, *args, **kwargs): # real signature unknown """ Return self*value. """ pass def __setitem__(self, *args, **kwargs): # real signature unknown """ Set self[key] to value. """ pass def __sizeof__(self): # real signature unknown; restored from __doc__ """ D.__sizeof__() -- size of D in memory, in bytes """ pass maxlen = property(lambda self: object(), lambda self, v: None, lambda self: None) # default """maximum size of a deque or None if unbounded""" __hash__ = None
Counter
用來統計元素出現的次數。
應用場景

源碼
class Counter(dict):
'''Dict subclass for counting hashable items. Sometimes called a bag
or multiset. Elements are stored as dictionary keys and their counts
are stored as dictionary values.
>>> c = Counter('abcdeabcdabcaba') # count elements from a string
>>> c.most_common(3) # three most common elements
[('a', 5), ('b', 4), ('c', 3)]
>>> sorted(c) # list all unique elements
['a', 'b', 'c', 'd', 'e']
>>> ''.join(sorted(c.elements())) # list elements with repetitions
'aaaaabbbbcccdde'
>>> sum(c.values()) # total of all counts
15
>>> c['a'] # count of letter 'a'
5
>>> for elem in 'shazam': # update counts from an iterable
... c[elem] += 1 # by adding 1 to each element's count
>>> c['a'] # now there are seven 'a'
7
>>> del c['b'] # remove all 'b'
>>> c['b'] # now there are zero 'b'
0
>>> d = Counter('simsalabim') # make another counter
>>> c.update(d) # add in the second counter
>>> c['a'] # now there are nine 'a'
9
>>> c.clear() # empty the counter
>>> c
Counter()
Note: If a count is set to zero or reduced to zero, it will remain
in the counter until the entry is deleted or the counter is cleared:
>>> c = Counter('aaabbc')
>>> c['b'] -= 2 # reduce the count of 'b' by two
>>> c.most_common() # 'b' is still in, but its count is zero
[('a', 3), ('c', 1), ('b', 0)]
'''
# References:
# http://en.wikipedia.org/wiki/Multiset
# http://www.gnu.org/software/smalltalk/manual-base/html_node/Bag.html
# http://www.demo2s.com/Tutorial/Cpp/0380__set-multiset/Catalog0380__set-multiset.htm
# http://code.activestate.com/recipes/259174/
# Knuth, TAOCP Vol. II section 4.6.3
def __init__(*args, **kwds):
'''Create a new, empty Counter object. And if given, count elements
from an input iterable. Or, initialize the count from another mapping
of elements to their counts.
>>> c = Counter() # a new, empty counter
>>> c = Counter('gallahad') # a new counter from an iterable
>>> c = Counter({'a': 4, 'b': 2}) # a new counter from a mapping
>>> c = Counter(a=4, b=2) # a new counter from keyword args
'''
if not args:
raise TypeError("descriptor '__init__' of 'Counter' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError('expected at most 1 arguments, got %d' % len(args))
super(Counter, self).__init__()
self.update(*args, **kwds)
def __missing__(self, key):
'The count of elements not in the Counter is zero.'
# Needed so that self[missing_item] does not raise KeyError
return 0
def most_common(self, n=None):
'''List the n most common elements and their counts from the most
common to the least. If n is None, then list all element counts.
>>> Counter('abcdeabcdabcaba').most_common(3)
[('a', 5), ('b', 4), ('c', 3)]
'''
# Emulate Bag.sortedByCount from Smalltalk
if n is None:
return sorted(self.items(), key=_itemgetter(1), reverse=True)
return _heapq.nlargest(n, self.items(), key=_itemgetter(1))
def elements(self):
'''Iterator over elements repeating each as many times as its count.
>>> c = Counter('ABCABC')
>>> sorted(c.elements())
['A', 'A', 'B', 'B', 'C', 'C']
# Knuth's example for prime factors of 1836: 2**2 * 3**3 * 17**1
>>> prime_factors = Counter({2: 2, 3: 3, 17: 1})
>>> product = 1
>>> for factor in prime_factors.elements(): # loop over factors
... product *= factor # and multiply them
>>> product
1836
Note, if an element's count has been set to zero or is a negative
number, elements() will ignore it.
'''
# Emulate Bag.do from Smalltalk and Multiset.begin from C++.
return _chain.from_iterable(_starmap(_repeat, self.items()))
# Override dict methods where necessary
@classmethod
def fromkeys(cls, iterable, v=None):
# There is no equivalent method for counters because setting v=1
# means that no element can have a count greater than one.
raise NotImplementedError(
'Counter.fromkeys() is undefined. Use Counter(iterable) instead.')
def update(*args, **kwds):
'''Like dict.update() but add counts instead of replacing them.
Source can be an iterable, a dictionary, or another Counter instance.
>>> c = Counter('which')
>>> c.update('witch') # add elements from another iterable
>>> d = Counter('watch')
>>> c.update(d) # add elements from another counter
>>> c['h'] # four 'h' in which, witch, and watch
4
'''
# The regular dict.update() operation makes no sense here because the
# replace behavior results in the some of original untouched counts
# being mixed-in with all of the other counts for a mismash that
# doesn't have a straight-forward interpretation in most counting
# contexts. Instead, we implement straight-addition. Both the inputs
# and outputs are allowed to contain zero and negative counts.
if not args:
raise TypeError("descriptor 'update' of 'Counter' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError('expected at most 1 arguments, got %d' % len(args))
iterable = args[0] if args else None
if iterable is not None:
if isinstance(iterable, Mapping):
if self:
self_get = self.get
for elem, count in iterable.items():
self[elem] = count + self_get(elem, 0)
else:
super(Counter, self).update(iterable) # fast path when counter is empty
else:
_count_elements(self, iterable)
if kwds:
self.update(kwds)
def subtract(*args, **kwds):
'''Like dict.update() but subtracts counts instead of replacing them.
Counts can be reduced below zero. Both the inputs and outputs are
allowed to contain zero and negative counts.
Source can be an iterable, a dictionary, or another Counter instance.
>>> c = Counter('which')
>>> c.subtract('witch') # subtract elements from another iterable
>>> c.subtract(Counter('watch')) # subtract elements from another counter
>>> c['h'] # 2 in which, minus 1 in witch, minus 1 in watch
0
>>> c['w'] # 1 in which, minus 1 in witch, minus 1 in watch
-1
'''
if not args:
raise TypeError("descriptor 'subtract' of 'Counter' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError('expected at most 1 arguments, got %d' % len(args))
iterable = args[0] if args else None
if iterable is not None:
self_get = self.get
if isinstance(iterable, Mapping):
for elem, count in iterable.items():
self[elem] = self_get(elem, 0) - count
else:
for elem in iterable:
self[elem] = self_get(elem, 0) - 1
if kwds:
self.subtract(kwds)
def copy(self):
'Return a shallow copy.'
return self.__class__(self)
def __reduce__(self):
return self.__class__, (dict(self),)
def __delitem__(self, elem):
'Like dict.__delitem__() but does not raise KeyError for missing values.'
if elem in self:
super().__delitem__(elem)
def __repr__(self):
if not self:
return '%s()' % self.__class__.__name__
try:
items = ', '.join(map('%r: %r'.__mod__, self.most_common()))
return '%s({%s})' % (self.__class__.__name__, items)
except TypeError:
# handle case where values are not orderable
return '{0}({1!r})'.format(self.__class__.__name__, dict(self))
# Multiset-style mathematical operations discussed in:
# Knuth TAOCP Volume II section 4.6.3 exercise 19
# and at http://en.wikipedia.org/wiki/Multiset
#
# Outputs guaranteed to only include positive counts.
#
# To strip negative and zero counts, add-in an empty counter:
# c += Counter()
def __add__(self, other):
'''Add counts from two counters.
>>> Counter('abbb') + Counter('bcc')
Counter({'b': 4, 'c': 2, 'a': 1})
'''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
newcount = count + other[elem]
if newcount > 0:
result[elem] = newcount
for elem, count in other.items():
if elem not in self and count > 0:
result[elem] = count
return result
def __sub__(self, other):
''' Subtract count, but keep only results with positive counts.
>>> Counter('abbbc') - Counter('bccd')
Counter({'b': 2, 'a': 1})
'''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
newcount = count - other[elem]
if newcount > 0:
result[elem] = newcount
for elem, count in other.items():
if elem not in self and count < 0:
result[elem] = 0 - count
return result
def __or__(self, other):
'''Union is the maximum of value in either of the input counters.
>>> Counter('abbb') | Counter('bcc')
Counter({'b': 3, 'c': 2, 'a': 1})
'''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
other_count = other[elem]
newcount = other_count if count < other_count else count
if newcount > 0:
result[elem] = newcount
for elem, count in other.items():
if elem not in self and count > 0:
result[elem] = count
return result
def __and__(self, other):
''' Intersection is the minimum of corresponding counts.
>>> Counter('abbb') & Counter('bcc')
Counter({'b': 1})
'''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
other_count = other[elem]
newcount = count if count < other_count else other_count
if newcount > 0:
result[elem] = newcount
return result
def __pos__(self):
'Adds an empty counter, effectively stripping negative and zero counts'
result = Counter()
for elem, count in self.items():
if count > 0:
result[elem] = count
return result
def __neg__(self):
'''Subtracts from an empty counter. Strips positive and zero counts,
and flips the sign on negative counts.
'''
result = Counter()
for elem, count in self.items():
if count < 0:
result[elem] = 0 - count
return result
def _keep_positive(self):
'''Internal method to strip elements with a negative or zero count'''
nonpositive = [elem for elem, count in self.items() if not count > 0]
for elem in nonpositive:
del self[elem]
return self
def __iadd__(self, other):
'''Inplace add from another counter, keeping only positive counts.
>>> c = Counter('abbb')
>>> c += Counter('bcc')
>>> c
Counter({'b': 4, 'c': 2, 'a': 1})
'''
for elem, count in other.items():
self[elem] += count
return self._keep_positive()
def __isub__(self, other):
'''Inplace subtract counter, but keep only results with positive counts.
>>> c = Counter('abbbc')
>>> c -= Counter('bccd')
>>> c
Counter({'b': 2, 'a': 1})
'''
for elem, count in other.items():
self[elem] -= count
return self._keep_positive()
def __ior__(self, other):
'''Inplace union is the maximum of value from either counter.
>>> c = Counter('abbb')
>>> c |= Counter('bcc')
>>> c
Counter({'b': 3, 'c': 2, 'a': 1})
'''
for elem, other_count in other.items():
count = self[elem]
if other_count > count:
self[elem] = other_count
return self._keep_positive()
def __iand__(self, other):
'''Inplace intersection is the minimum of corresponding counts.
>>> c = Counter('abbb')
>>> c &= Counter('bcc')
>>> c
Counter({'b': 1})
'''
for elem, count in self.items():
other_count = other[elem]
if other_count < count:
self[elem] = other_count
return self._keep_positive()namedtuple
命名tuple中的元素來使程序更具可讀性 。
應用案例
from collections import namedtuple
City = namedtuple('City', 'name title popu coor')
tokyo = City('Tokyo', '下輩子讓我做系守的姑娘吧!下輩子讓我做東京的帥哥吧!', 36.933, (35.689722, 139.691667))
print(tokyo)
# City(name='Tokyo', title='下輩子讓我做系守的姑娘吧!下輩子讓我做東京的帥哥吧!', popu=36.933, coor=(35.689722,
139.691667))
def namedtuple(typename, field_names, *, verbose=False, rename=False, module=None):
"""Returns a new subclass of tuple with named fields.
>>> Point = namedtuple('Point', ['x', 'y'])
>>> Point.__doc__ # docstring for the new class
'Point(x, y)'
>>> p = Point(11, y=22) # instantiate with positional args or keywords
>>> p[0] + p[1] # indexable like a plain tuple
33
>>> x, y = p # unpack like a regular tuple
>>> x, y
(11, 22)
>>> p.x + p.y # fields also accessible by name
33
>>> d = p._asdict() # convert to a dictionary
>>> d['x']
11
>>> Point(**d) # convert from a dictionary
Point(x=11, y=22)
>>> p._replace(x=100) # _replace() is like str.replace() but targets named fields
Point(x=100, y=22)
"""
# Validate the field names. At the user's option, either generate an error
# message or automatically replace the field name with a valid name.
if isinstance(field_names, str):
field_names = field_names.replace(',', ' ').split()
field_names = list(map(str, field_names))
typename = str(typename)
if rename:
seen = set()
for index, name in enumerate(field_names):
if (not name.isidentifier()
or _iskeyword(name)
or name.startswith('_')
or name in seen):
field_names[index] = '_%d' % index
seen.add(name)
for name in [typename] + field_names:
if type(name) is not str:
raise TypeError('Type names and field names must be strings')
if not name.isidentifier():
raise ValueError('Type names and field names must be valid '
'identifiers: %r' % name)
if _iskeyword(name):
raise ValueError('Type names and field names cannot be a '
'keyword: %r' % name)
seen = set()
for name in field_names:
if name.startswith('_') and not rename:
raise ValueError('Field names cannot start with an underscore: '
'%r' % name)
if name in seen:
raise ValueError('Encountered duplicate field name: %r' % name)
seen.add(name)
# Fill-in the class template
class_definition = _class_template.format(
typename = typename,
field_names = tuple(field_names),
num_fields = len(field_names),
arg_list = repr(tuple(field_names)).replace("'", "")[1:-1],
repr_fmt = ', '.join(_repr_template.format(name=name)
for name in field_names),
field_defs = '\n'.join(_field_template.format(index=index, name=name)
for index, name in enumerate(field_names))
)
# Execute the template string in a temporary namespace and support
# tracing utilities by setting a value for frame.f_globals['__name__']
namespace = dict(__name__='namedtuple_%s' % typename)
exec(class_definition, namespace)
result = namespace[typename]
result._source = class_definition
if verbose:
print(result._source)
# For pickling to work, the __module__ variable needs to be set to the frame
# where the named tuple is created. Bypass this step in environments where
# sys._getframe is not defined (Jython for example) or sys._getframe is not
# defined for arguments greater than 0 (IronPython), or where the user has
# specified a particular module.
if module is None:
try:
module = _sys._getframe(1).f_globals.get('__name__', '__main__')
except (AttributeError, ValueError):
pass
if module is not None:
result.__module__ = module
return resultChainMap
用來合并多個字典。
應用案例
from collections import ChainMap
cm = ChainMap(
{"Apple": 18},
{"Orange": 20},
{"Mango": 22},
{"pineapple": 24},
)
print(cm)
# ChainMap({'Apple': 18}, {'Orange': 20}, {'Mango': 22}, {'pineapple': 24})源碼
class ChainMap(MutableMapping):
''' A ChainMap groups multiple dicts (or other mappings) together
to create a single, updateable view.
The underlying mappings are stored in a list. That list is public and can
be accessed or updated using the *maps* attribute. There is no other
state.
Lookups search the underlying mappings successively until a key is found.
In contrast, writes, updates, and deletions only operate on the first
mapping.
'''
def __init__(self, *maps):
'''Initialize a ChainMap by setting *maps* to the given mappings.
If no mappings are provided, a single empty dictionary is used.
'''
self.maps = list(maps) or [{}] # always at least one map
def __missing__(self, key):
raise KeyError(key)
def __getitem__(self, key):
for mapping in self.maps:
try:
return mapping[key] # can't use 'key in mapping' with defaultdict
except KeyError:
pass
return self.__missing__(key) # support subclasses that define __missing__
def get(self, key, default=None):
return self[key] if key in self else default
def __len__(self):
return len(set().union(*self.maps)) # reuses stored hash values if possible
def __iter__(self):
return iter(set().union(*self.maps))
def __contains__(self, key):
return any(key in m for m in self.maps)
def __bool__(self):
return any(self.maps)
@_recursive_repr()
def __repr__(self):
return '{0.__class__.__name__}({1})'.format(
self, ', '.join(map(repr, self.maps)))
@classmethod
def fromkeys(cls, iterable, *args):
'Create a ChainMap with a single dict created from the iterable.'
return cls(dict.fromkeys(iterable, *args))
def copy(self):
'New ChainMap or subclass with a new copy of maps[0] and refs to maps[1:]'
return self.__class__(self.maps[0].copy(), *self.maps[1:])
__copy__ = copy
def new_child(self, m=None): # like Django's Context.push()
'''New ChainMap with a new map followed by all previous maps.
If no map is provided, an empty dict is used.
'''
if m is None:
m = {}
return self.__class__(m, *self.maps)
@property
def parents(self): # like Django's Context.pop()
'New ChainMap from maps[1:].'
return self.__class__(*self.maps[1:])
def __setitem__(self, key, value):
self.maps[0][key] = value
def __delitem__(self, key):
try:
del self.maps[0][key]
except KeyError:
raise KeyError('Key not found in the first mapping: {!r}'.format(key))
def popitem(self):
'Remove and return an item pair from maps[0]. Raise KeyError is maps[0] is empty.'
try:
return self.maps[0].popitem()
except KeyError:
raise KeyError('No keys found in the first mapping.')
def pop(self, key, *args):
'Remove *key* from maps[0] and return its value. Raise KeyError if *key* not in maps[0].'
try:
return self.maps[0].pop(key, *args)
except KeyError:
raise KeyError('Key not found in the first mapping: {!r}'.format(key))
def clear(self):
'Clear maps[0], leaving maps[1:] intact.'
self.maps[0].clear()UserDict
UserDict是MutableMapping和Mapping的子類,它繼承了MutableMapping.update和Mapping.get兩個重要的方法 。
應用案例
from collections import UserDict class DictKeyToStr(UserDict): def __missing__(self, key): if isinstance(key, str): raise KeyError(key) return self[str(key)] def __contains__(self, key): return str(key) in self.data def __setitem__(self, key, item): self.data[str(key)] = item # 該函數可以不實現 ''' def get(self, key, default=None): try: return self[key] except KeyError: return default '''
源碼
class UserDict(MutableMapping):
# Start by filling-out the abstract methods
def __init__(*args, **kwargs):
if not args:
raise TypeError("descriptor '__init__' of 'UserDict' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError('expected at most 1 arguments, got %d' % len(args))
if args:
dict = args[0]
elif 'dict' in kwargs:
dict = kwargs.pop('dict')
import warnings
warnings.warn("Passing 'dict' as keyword argument is deprecated",
DeprecationWarning, stacklevel=2)
else:
dict = None
self.data = {}
if dict is not None:
self.update(dict)
if len(kwargs):
self.update(kwargs)
def __len__(self): return len(self.data)
def __getitem__(self, key):
if key in self.data:
return self.data[key]
if hasattr(self.__class__, "__missing__"):
return self.__class__.__missing__(self, key)
raise KeyError(key)
def __setitem__(self, key, item): self.data[key] = item
def __delitem__(self, key): del self.data[key]
def __iter__(self):
return iter(self.data)
# Modify __contains__ to work correctly when __missing__ is present
def __contains__(self, key):
return key in self.data
# Now, add the methods in dicts but not in MutableMapping
def __repr__(self): return repr(self.data)
def copy(self):
if self.__class__ is UserDict:
return UserDict(self.data.copy())
import copy
data = self.data
try:
self.data = {}
c = copy.copy(self)
finally:
self.data = data
c.update(self)
return c
@classmethod
def fromkeys(cls, iterable, value=None):
d = cls()
for key in iterable:
d[key] = value
return dNo.23 Python中的變量與垃圾回收機制
Python與Java的變量本質上不一樣,Python的變量本事是個指針。當Python解釋器執行number=1的時候,實際上先在內存中創建一個int對象,然后將number指向這個int對象的內存地址,也就是將number“貼”在int對象上,測試用例如下:
number = [1, 2, 3] demo = number demo.append(4) print(number) # [1, 2, 3, 4]
==和is的區別就是前者判斷的值是否相等,后者判斷的是對象id值是否相等。
class Person(object): pass p_0 = Person() p_1 = Person() print(p_0 is p_1) # False print(p_0 == p_1) # False print(id(p_0)) # 2972754016464 print(id(p_1)) # 2972754016408 li_a = [1, 2, 3, 4] li_b = [1, 2, 3, 4] print(li_a is li_b) # False print(li_a == li_b) # True print(id(li_a)) # 2972770077064 print(id(li_b)) # 2972769996680 a = 1 b = 1 print(a is b) # True print(a == b) # True print(id(a)) # 1842179136 print(id(b)) # 1842179136
Python有一個優化機制叫intern,像這種經常使用的小整數、小字符串,在運行時就會創建,并且全局唯一。
Python中的del語句并不等同于C++中的delete,Python中的del是將這個對象的指向刪除,當這個對象沒有任何指向的時候,Python虛擬機才會刪除這個對象。
No.24 Python元類編程
property動態屬性
class Home(object): def __init__(self, age): self.__age = age @property def age(self): return self.__age if __name__ == '__main__': home = Home(21) print(home.age) # 21
在Python中,為函數添加@property裝飾器可以使得函數像變量一樣訪問。
getattr和getattribute函數的使用
getattr在查找屬性的時候,找不到該屬性就會調用這個函數。
class Demo(object):
def __init__(self, user, passwd):
self.user = user
self.password = passwd
def __getattr__(self, item):
return 'Not find Attr.'
if __name__ == '__main__':
d = Demo('Bob', '123456')
print(d.User)getattribute在調用屬性之前會調用該方法。
class Demo(object):
def __init__(self, user, passwd):
self.user = user
self.password = passwd
def __getattr__(self, item):
return 'Not find Attr.'
def __getattribute__(self, item):
print('Hello.')
if __name__ == '__main__':
d = Demo('Bob', '123456')
print(d.User)
# Hello.
# None屬性描述符
在一個類中實現__get__()、__set__()和__delete__()都是屬性描述符。
數據屬性描述符
import numbers
class IntField(object):
def __init__(self):
self.v = 0
def __get__(self, instance, owner):
return self.v
def __set__(self, instance, value):
if(not isinstance(value, numbers.Integral)):
raise ValueError("Int value need.")
self.v = value
def __delete__(self, instance):
pass非數據屬性描述符
在Python的新式類中,對象屬性的訪問都會調用__getattribute__()方法,它允許我們在訪問對象時自定義訪問行為,值得注意的是小心無限遞歸的發生。__getattriubte__()是所有方法和屬性查找的入口,當調用該方法之后會根據一定規則在__dict__中查找相應的屬性值或者是對象,如果沒有找到就會調用__getattr__()方法,與之對應的__setattr__()和__delattr__()方法分別用來自定義某個屬性的賦值行為和用于處理刪除屬性的行為。描述符的概念在Python 2.2中引進,__get__()、__set__()、__delete__()分別定義取出、設置、刪除描述符的值的行為。
值得注意的是,只要實現這三種方法中的任何一個都是描述符。
僅實現__get__()方法的叫做非數據描述符,只有在初始化之后才能被讀取。
同時實現__get__()和__set__()方法的叫做數據描述符,屬性是可讀寫的。
屬性訪問的優先規則
對象的屬性一般是在__dict__中存儲,在Python中,__getattribute__()實現了屬性訪問的相關規則。
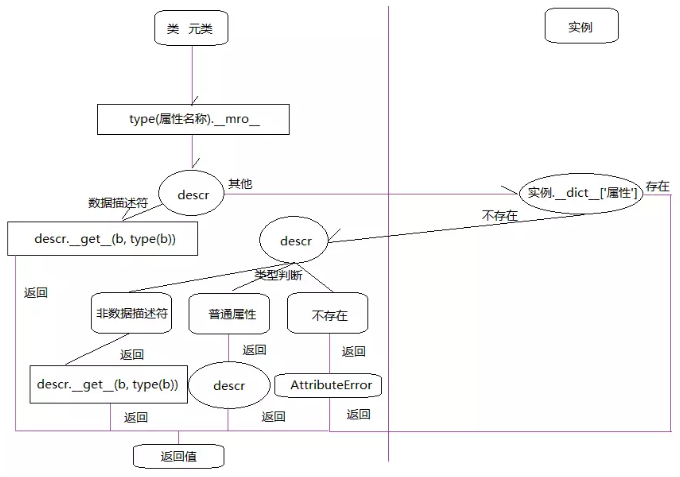
假定存在實例obj,屬性number在obj中的查找過程是這樣的:
搜索基類列表type(b).__mro__,直到找到該屬性,并賦值給descr。
判斷descr的類型,如果是數據描述符則調用descr.__get__(b, type(b)),并將結果返回。
如果是其他的(非數據描述符、普通屬性、沒找到的類型)則查找實例obj的實例屬性,也就是obj.__dict__。
如果在obj.__dict__沒有找到相關屬性,就會重新回到descr的判斷上。
如果再次判斷descr類型為非數據描述符,就會調用descr.__get__(b, type(b)),并將結果返回,結束執行。
如果descr是普通屬性,直接就返回結果。
如果第二次沒有找到,為空,就會觸發AttributeError異常,并且結束查找。
用流程圖表示:
__new__()和__init__()的區別
__new__()函數用來控制對象的生成過程,在對象上生成之前調用。
__init__()函數用來對對象進行完善,在對象生成之后調用。
如果__new__()函數不返回對象,就不會調用__init__()函數。
自定義元類
在Python中一切皆對象,類用來描述如何生成對象,在Python中類也是對象,原因是它具備創建對象的能力。當Python解釋器執行到class語句的時候,就會創建這個所謂類的對象。既然類是個對象,那么就可以動態的創建類。這里我們用到type()函數,下面是此函數的構造函數源碼:
def __init__(cls, what, bases=None, dict=None): # known special case of type.__init__ """ type(object_or_name, bases, dict) type(object) -> the object's type type(name, bases, dict) -> a new type # (copied from class doc) """ pass
由此可知,type()接收一個類的額描述返回一個類。
def bar():
print("Hello...")
user = type('User', (object, ), {
'name': 'Bob',
'age': 20,
'bar': bar,
})
user.bar() # Hello...
print(user.name, user.age) # Bob 20元類用來創建類,因為累也是對象。type()之所以可以創建類是由于tyep()就是個元類,Python中所有的類都由它創建。在Python中,我們可以通過一個對象的__class__屬性來確定這個對象由哪個類產生,當Python創建一個類的對象的時候,Python將在這個類中查找其__metaclass__屬性。如果找到了,就用它創建對象,如果沒有找到,就去父類中查找,如果還是沒有,就去模塊中查找,一路下來還沒有找到的話,就用type()創建。創建元類可以使用下面的寫法:
class MetaClass(type): def __new__(cls, *args, **kwargs): return super().__new__(cls, *args, **kwargs) class User(metaclass=MetaClass): pass
使用元類創建API
元類的主要用途就是創建API,比如Python中的ORM框架。
Python領袖 Tim Peters :
“元類就是深度的魔法,99%的用戶應該根本不必為此操心。如果你想搞清楚究竟是否需要用到元類,那么你就不需要它。那些實際用到元類的人都非常清楚地知道他們需要做什么,而且根本不需要解釋為什么要用元類。”
No.25 迭代器和生成器
當容器中的元素很多的時候,不可能全部讀取到內存,那么就需要一種算法來推算下一個元素,這樣就不必創建很大的容器,生成器就是這個作用。
Python中的生成器使用yield返回值,每次調用yield會暫停,因此生成器不會一下子全部執行完成,是當需要結果時才進行計算,當函數執行到yield的時候,會返回值并且保存當前的執行狀態,也就是函數被掛起了。我們可以使用next()函數和send()函數恢復生成器,將列表推導式的[]換成()就會變成一個生成器:
my_iter = (x for x in range(10)) for i in my_iter: print(i)
值得注意的是,我們一般不會使用next()方法來獲取元素,而是使用for循環。當使用while循環時,需要捕獲StopIteration異常的產生。
Python虛擬機中有一個棧幀的調用棧,棧幀保存了指定的代碼的信息和上下文,每一個棧幀都有自己的數據棧和塊棧,由于這些棧幀保存在堆內存中,使得解釋器有中斷和恢復棧幀的能力:
import inspect frame = None def foo(): global frame frame = inspect.currentframe() def bar(): foo() bar() print(frame.f_code.co_name) # foo print(frame.f_back.f_code.co_name) # bar
這也是生成器存在的基礎。只要我們在任何地方獲取生成器對象,都可以開始或暫停生成器,因為棧幀是獨立于調用者而存在的,這也是協程的理論基礎。
迭代器是一種不同于for循環的訪問集合內元素的一種方式,一般用來遍歷數據,迭代器提供了一種惰性訪問數據的方式。
可以使用for循環的有以下幾種類型:
·集合數據類型
·生成器,包括生成器和帶有yield的生成器函數
這些可以直接被for循環調用的對象叫做可迭代對象,可以使用isinstance()判斷一個對象是否為可Iterable對象。集合數據類型如list、dict、str等是Iterable但不是Iterator,可以通過iter()函數獲得一個Iterator對象。send()和next()的區別就在于send()可傳遞參數給yield()表達式,這時候傳遞的參數就會作為yield表達式的值,而yield的參數是返回給調用者的值,也就是說send可以強行修改上一個yield表達式值。
感謝你能夠認真閱讀完這篇文章,希望小編分享關于Python的知識點有哪些內容對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,遇到問題就找億速云,詳細的解決方法等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





