溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
近期,在交流群中有網友談到SQL Server索引的最左匹配原則,理解為T-SQL中Where條件的書寫順序的問題,這是一個誤解。
下面先看下實驗結果。
1?、準備數據。
CREATE TABLE [dbo].[t6](
??? [id] [int] IDENTITY(1,1) NOT NULL,
??? [hour] [int] NULL,
??? [ordernumber] [int] NULL,
?CONSTRAINT [PK_t6] PRIMARY KEY CLUSTERED ( [id] ASC ) ?ON [PRIMARY]
) ON [PRIMARY]
GO
?
insert into t6 values(default,default)
--?重復執行如下語句,生成10+M記錄
insert into t6 select id, hour? from t6
?
update t6 set
?? ?hour=id % convert(int,300000*RAND()+2), ordernumber=id % convert(int,3000*RAND()+2)
2?、創建索引1。http://u48582907.b2bname.com/
create index fhsy1 on t6(hour, ordernumber)
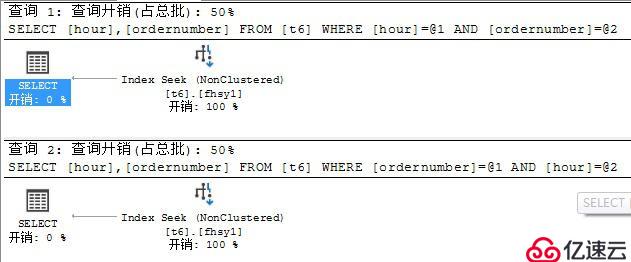
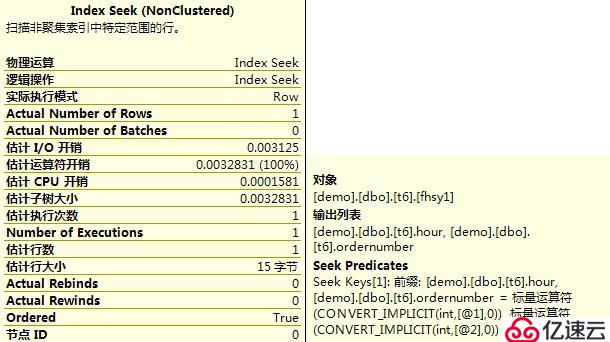
3?、查看兩個字段均為等值查詢的執行計劃。
select hour,ordernumber from t6 where hour=1 and ordernumber=1
select hour,ordernumber from t6 where ordernumber=1 and hour=1
4?、創建索引2。
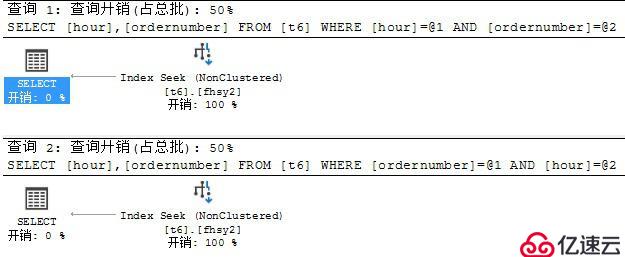
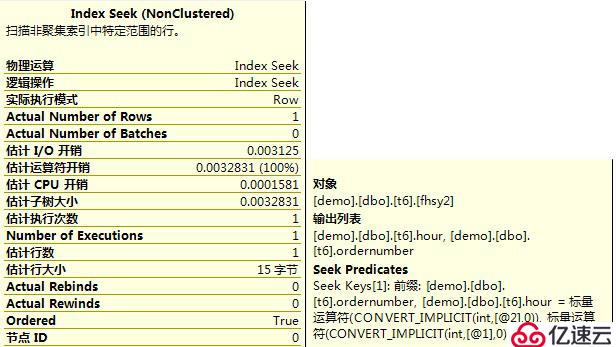
create index fhsy1 on t6(ordernumber, hour)
5?、再次查看執行計劃。
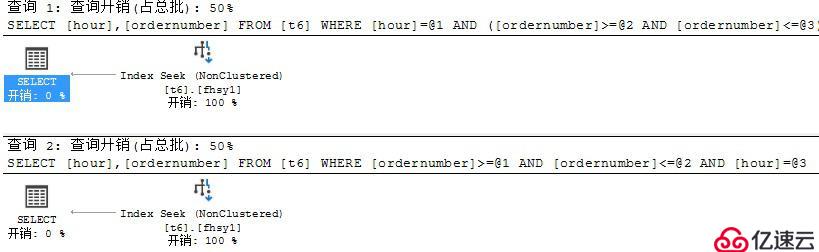
6?、再看一下一個字段為等值,另一個字段為范圍查詢的執行計劃。
select hour,ordernumber from t6 where hour=1 and ordernumber between 1 and 2
select hour,ordernumber from t6 where ordernumber between 1 and 2 and hour=1
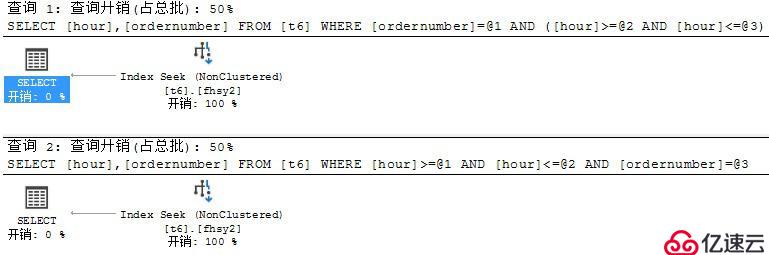
select hour,ordernumber from t6 where ordernumber=1 and hour between 1 and 2
select hour,ordernumber from t6 where hour between 1 and 2 and ordernumber=1
?

結論
1?、索引的最左匹配,是指的檢索條件與索引字段的關系,與在T-SQL語句中Where條件中的書寫順序無關。
索引與搜索條件的書寫順序有關,這在上世紀可能還有可能;現在的數據庫引擎的智能化程序,應該可以通過智能優化或語句改寫,實現順序無關。這一點都做不到,這個數據庫離淘汰就不遠了。鄭州不孕不育醫院:http://yyk.39.net/zz3/zonghe/1d427.html
2?、從Cost來看,索引總是匹配等值檢索字段在前的復合索引,這就是被稱為?最左匹配原則?的原因。
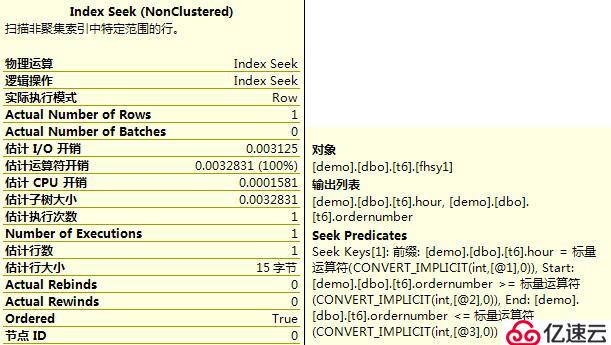
3?、最左匹配索引的執行計劃,是Index Seek/Scan,即先通過等值條件進行定位,再通過不等條件進行范圍掃描。一般來說,此執行計劃要優于Index Scan,即整個索引的掃描。
疑惑
在等值查詢中,CBO會自動選擇一個Cost最小的執行計劃,索引1和索引2相當,最終執行計劃選擇索引2而不是索引1,原因不明。應該和索引樹的高度、統計信息有關。待查。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





