溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何給SQL做個優化”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何給SQL做個優化”吧!
SQL 語句執行較慢的 3 個原因
沒有建立索引,或者索引失效導致了 SQL 語句執行較慢
這個應該是比較好理解的,如果數據比較多,在千萬級別以上,然后呢又沒有建立索引,在這千萬級別的數據中查找你想要的內容,簡直就是在肉搏啊(哎呦,可了不得,竟然敢肉搏
索引失效這塊內容說起來就比較多了,比如在查詢的時候,讓 like 通配符在前面了,比如經常念叨的“最左匹配原則”,又比如我們在查詢條件中使用 or ,而且 or 前后條件中有一個列沒有索引,等等這些情況都會導致索引失效
鎖等待
常用的存儲引擎主要有 InnoDB 和 MyISAM 這兩種了,前者支持行鎖和表鎖,后者就只支持表鎖
如果數據庫操作都是基于表鎖的話,意思就是說,現在有個更新操作,就會把整張表鎖起來,那么查詢的操作都不被允許,所以就不要說提高系統的并發性能了
聰明的你肯定就知道了,既然 MyISAM 只支持表鎖,那么使用 InnoDB 不就好了?你以為 InnoDB 的行鎖不會升級成表鎖嘛?too young too simple !
如果對一張表進行大量的更新操作, mysql 就覺得你這樣用會讓事務的執行效率降低,到最后還是會導致性能下降,這樣的話,還不如把你的行鎖升級成表鎖呢
還有一點,行鎖可是基于索引加的鎖,在執行更新操作時,條件索引都失效了,那么這個鎖也會執行從行鎖升級為表鎖
不恰當的 SQL 語句
這個也比較常見了,啥是不恰當的 SQL 語句呢?就比如,明明你需要查找的內容是 name , age ,但是呢,為了省事,直接 select *,或者在 order by 時,后面的條件不是索引字段,這就是不恰當的 SQL 語句
優化 SQL 語句
在知道了 SQL 語句執行比較慢的原因之后,接下來要做的就是對癥下藥了
針對 沒有索引/索引失效 這塊,最有效的辦法就是 EXPLAIN 語法了,那你知不知道 Show Profile 也可以嘞
針對 鎖等待 這塊,沒辦法了,只能自己多注意
針對 不恰當的 SQL 語句 這塊,介紹幾個常用的 SQL 優化,比如分頁查詢怎么優化一下可以查詢的更快一些呀,你不是說 select * 不是正確的打開方式嘛?那什么是正確的 select 方式呢?別急嘛,阿粉下面都會說到的
廢話不多說,咱們開始了
先來個表
為了確保優化后的結果和我寫的一樣(起碼 90% 是相符的
所以咱們用一樣的數據庫好不好?乖~
首先建個 demo 的數據庫
接下來咱們建表,就建個非常簡單的表好不好
CREATE TABLE demo.table( id int(11) NOT NULL, a int(11) DEFAULT NULL, b int(11) DEFAULT NULL, PRIMARY KEY(id) ) ENGINE = INNODB
然后插入 10 萬條數據
DROP PROCEDURE IF EXISTS demo_insert; CREATE PROCEDURE demo_insert() BEGIN DECLARE i INT; SET i = 1; WHILE i <= 100000 DO INSERT INTO demo.`table` VALUES (i, i, i); SET i = i + 1 ; END WHILE; END; CALL demo_insert();
OK ,準備工作做好了,接下來開始實戰
通過 EXPLAIN 分析 SQL 是怎樣執行的
只要說 SQL 調優,那就離不開 EXPLAIN
EXPLAIN SELECT * FROMtableWHERE id < 100 ORDER BY a;

咱們能夠看到有好幾個參數:
id :每個執行計劃都會有一個 id ,如果是一個聯合查詢的話,這里就會顯示好多個 id
select_type :表示的是 select 查詢類型,常見的就是 SIMPLE (普通查詢,也就是沒有聯合查詢/子查詢), PRIMARY (主查詢), UNION ( UNION 中后面的查詢), SUBQUERY (子查詢)
table :執行查詢計劃的表,在這里我查的就是 table ,所以顯示的是 table, 那如果我給 table 起了別名 a ,在這里顯示的就是 a
type :查詢所執行的方式,這是咱們在分析 SQL 優化的時候一個非常重要的指標,這個值從好到壞依次是: system > const > eq_ref > ref > range > index > ALL
system/const :說明表中只有一行數據匹配,這個時候根據索引查詢一次就能找到對應的數據
eq_ref :使用唯一索引掃描,這個經常在多表連接里面,使用主鍵和唯一索引作為關聯條件時可以看到
ref :非唯一索引掃描,也可以在唯一索引最左原則匹配掃描看到
range :索引范圍掃描,比如查詢條件使用到了 < , > , between 等條件
index :索引全表掃描,這個時候會遍歷整個索引樹
ALL :表示全表掃描,也就是需要遍歷整張表才能找到對應的行
possible_keys :表示可能使用到的索引
key :實際使用到的索引
key_len :使用的索引長度
ref :關聯 id 等信息
rows :找到符合條件時,所掃描的行數,在這里雖然有 10 萬條數據,但是因為索引的緣故,所以掃描了 99 行的數據
Extra :額外的信息,常見的有以下幾種
Using where :不用讀取表里面的所有信息,只需要通過索引就可以拿到需要的數據,這個過程發生在對表的全部請求列都是同一個索引部分時
Using temporary :表示 mysql 需要使用臨時表來存儲結果集,常見于 group by / order by
Using filesort :當查詢的語句中包含 order by 操作的時候,而且 order by 后面的內容不是索引,這樣就沒有辦法利用索引完成排序,就會使用"文件排序",就像例子中給出的,建立的索引是 id , 但是我的查詢語句 order by 后面是 a ,沒有辦法使用索引
Using join buffer :使用了連接緩存
Using index :使用了覆蓋索引
如果對這些參數了解的非常不錯,那么 EXPLAIN 這塊內容就難不住你了
Show Profile 分析下 SQL 執行性能
通過 EXPLAIN 分析執行計劃,只能說明 SQL 的外部執行情況,如果想要知道 mysql 具體是如何查詢的,需要通過 Show Profile 來分析
可以通過 SHOW PROFILES; 語句來查詢最近發送給服務器的 SQL 語句,默認情況下是記錄最近已經執行的 15 條記錄,如下圖我們可以看到:
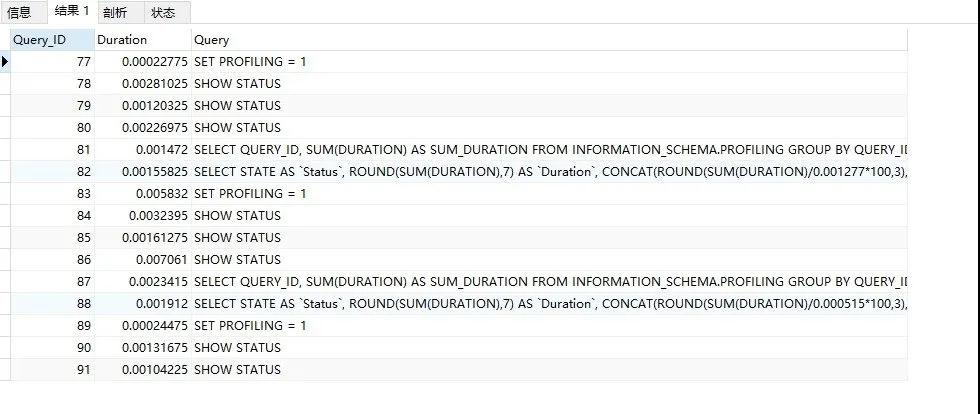
我想看具體的一條語句,看到 Query_ID 了嘛?然后運行下 SHOW PROFILE FOR QUERY 82;這條命令就可以了:
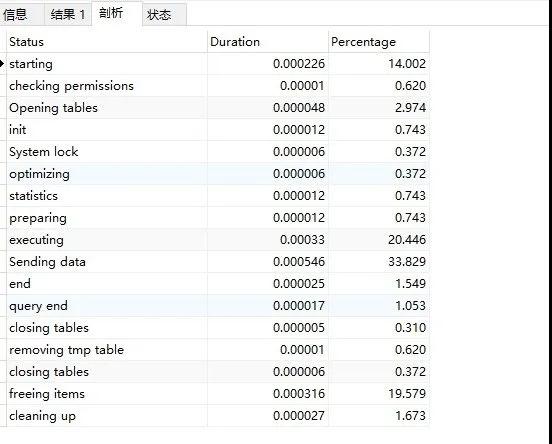
可以看到,在結果中, Sending data 耗時是最長的,這是因為此時 mysql 線程開始讀取數據并且把這些數據返回到客戶端,在這個過程中會有大量磁盤 I/O 操作
通過這樣的分析,我們就能知道, SQL 語句在查詢過程中,到底是 磁盤 I/O 影響了查詢速度,還是 System lock 影響了查詢速度,知道了病癥所在,接下來對癥下藥就容易多了
分頁查詢怎么可以更快一些在使用分頁查詢時,都會使用 limit 關鍵字
但是對于分頁查詢,其實還可以優化一步
我這里給出的數據庫不是太好,因為它太簡單了,看不出來有什么區別,我使用目前項目上正在用的表來做個實驗,可以看下區別(使用的 SQL 語句如下面):
EXPLAIN SELECT * FROM `te_paper_record` ORDER BY id LIMIT 10000, 20; EXPLAIN SELECT * FROM `te_paper_record` WHERE id >= ( SELECT id FROM `te_paper_record` ORDER BY id LIMIT 10000, 1) LIMIT 20;
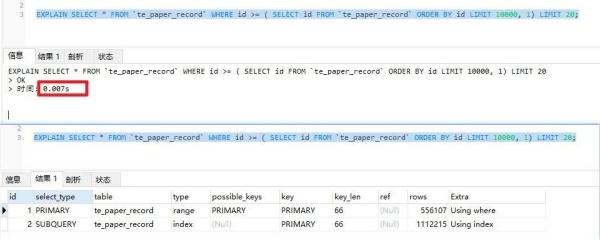
上面一張圖片,我沒有使用子查詢,可以看到執行了 0.033s ,下面的查詢語句,我使用了子查詢去做優化,能夠看到執行了 0.007s ,優化的結果還是很顯而易見的
那么,為什么使用了子查詢,查詢的速度就提上來了呢,這是因為當我們沒有使用子查詢時,查詢到的 10020 行數據都返回回來了,接下來要對這 10020 行數據再進行過濾操作
那可不可以直接就返回需要的 20 行數據呢,這樣就不需要再做過濾操作了,直接返回就可以了嘛
你也太聰明了吧。子查詢就是在做這件事情
所以查詢時間上有了一個很大的優化
正確的 select 打開方式
在查詢時,有時為了省事,直接使用 select * from table where id = 1 這樣的 SQL 語句,但是這樣的寫法在一些環境下是會存在一定的性能損耗的
所以最好的 select 查詢就是,需要什么字段就查詢什么字段
一般在查詢時,都會有條件,按照條件查找
這個時候正確的 select 打開方式是什么呢?
如果可以通過主鍵索引的話, where 后面的條件,優先選擇主鍵索引
為什么呢?這就要知道 MySQL 的存儲規則
MySQL 常用的存儲引擎有 MyISAM 和 InnoDB , InnoDB 會創建主鍵索引,而主鍵索引屬于聚簇索引,也就是在存儲數據時,索引是基于 B+ 樹構成的,具體的行數據則存儲在葉子節點
也就是說,如果是通過主鍵索引查詢的,會直接搜索 B+ 樹,從而查詢到數據
如果不是通過主鍵索引查詢的,需要先搜索索引樹,得到在 B+ 樹上的值,再到 B+ 樹上搜索符合條件的數據,這個過程就是“回表”
很顯然,回表能夠產生時間。
這也是為什么建議, where 后面的條件,優先選擇主鍵索引
其他調優
看完上面的,心里應該就大概有數了, SQL 調優主要就是建立索引/防止產生鎖等待/使用恰當的 SQL 語句去查詢
但是,如果問你除了索引,除了上面這些手段,還有沒有其他調優方式
啥?竟然還有?!
有的,這就需要跳出來,不要局限在具體的 SQL 語句上了,需要在數據庫設計之初就考慮好
比如說,我們常說的要遵循三范式,但是在有的業務場景里面,如果在數據庫里面多幾個冗余字段的話,可能要比嚴格遵循三范式帶來的性能要好很多。
到此,相信大家對“如何給SQL做個優化”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





