溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1.準備工作
2.實現細節
1.首先是tess-two的用法。
app下的build.gradle的配置如下
android {
defaultConfig {
....
ndk {
abiFilters 'armeabi' //自行選擇添加
}
}
}
dependencies {
compile 'com.rmtheis:tess-two:8.0.0'
}
識別方法:
public String detectText(Bitmap bitmap) {
TessBaseAPI tessBaseAPI = new TessBaseAPI();
String path = ""; //訓練數據路徑
tessBaseAPI.setDebug(true);
tessBaseAPI.init(path, "eng"); //eng為識別語言
tessBaseAPI.setVariable(TessBaseAPI.VAR_CHAR_WHITELIST, "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789"); // 識別白名單
tessBaseAPI.setVariable(TessBaseAPI.VAR_CHAR_BLACKLIST, "!@#$%^&*()_+=-[]}{;:'\"\\|~`,./<>?"); // 識別黑名單
tessBaseAPI.setPageSegMode(TessBaseAPI.PageSegMode.PSM_AUTO_OSD);//設置識別模式
tessBaseAPI.setImage(bitmap); //設置需要識別圖片的bitmap
String inspection = tessBaseAPI.getHOCRText(0);
tessBaseAPI.end();
return inspection ;
}
訓練數據可以在tessdata下載,里面包含各種語言。當然你自己也可以訓練它,有興趣的可以學習一下相關內容。
2.從tess-two的用法可以知道,我們最終需要的是識別圖片的Bitmap。在掃碼項目中我們找到在DecodeHandler類的decode方法中,我們會得到一個PlanarYUVLuminanceSource類的實例。在使用HybridBinarizer算法解析數據源,最終采用MultiFormatReader解析圖像出結果。代碼大致如下:
Result rawResult = null;
MultiFormatReader mMultiFormatReade = new MultiFormatReader();
try {
PlanarYUVLuminanceSource source =
new PlanarYUVLuminanceSource(```, false);
BinaryBitmap bitmap = new BinaryBitmap(new HybridBinarizer(source));
rawResult = mMultiFormatReader.decode(bitmap, mHints);
} catch (ReaderException ignored) {
} finally {
mMultiFormatReader.reset();
}
看完后懵逼了,沒有Bitmap。經過一番查找,找到了在舊版的zxing中PlanarYUVLuminanceSource類有renderCroppedGreyscaleBitmap方法,不知為何去除了。。。
3.之后修改了一些相機的參數信息,適配了部分設備的預覽效果。基本的頁面修改了一下。這里就不贅述了。
走一波,如下效果:
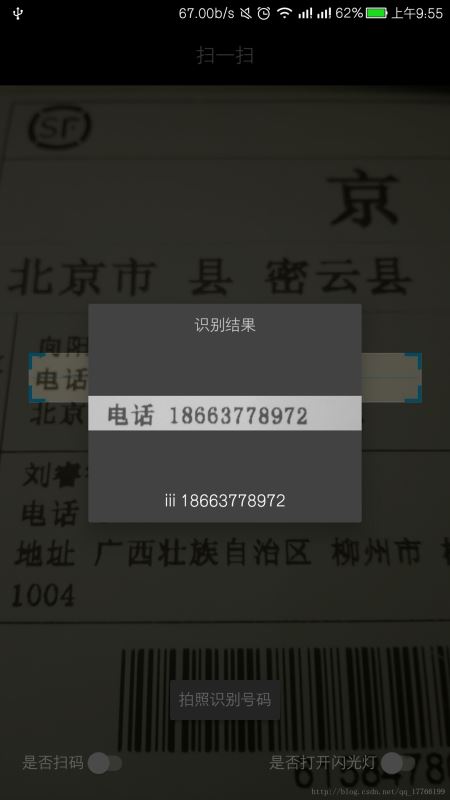
可以發現除了數字以外,它將中文識別為了字母。其實問題首先是我們使用了英文的訓練數據,同時白名單設置了a~z的字母。當然你也不能將字母設置為黑名單,那樣只會讓識別不出的字符識別為亂七八糟的數字。
這里我給出的建議是利用正則去篩選,這樣你可以識別你想要的各種格式數據。我這里只是做了手機號的簡單識別,大家可以舉一反三去處理。
public static String getTelNum(String sParam){
if(TextUtils.isEmpty(sParam)){
return "";
}
Pattern pattern = Pattern.compile("(1|861)(3|5|7|8)\\d{9}$*");
Matcher matcher = pattern.matcher(sParam);
StringBuilder bf = new StringBuilder();
while (matcher.find()) {
bf.append(matcher.group()).append(",");
}
int len = bf.length();
if (len > 0) {
bf.deleteCharAt(len - 1);
}
return bf.toString();
}
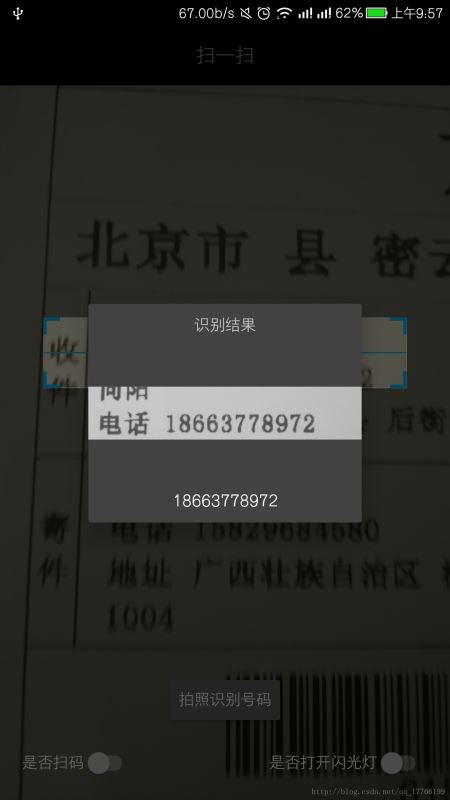
修改后如下:(同時支持多個號碼)

當然本項目也保留了掃碼功能(可在DecodeHandler中自己添加條碼格式):
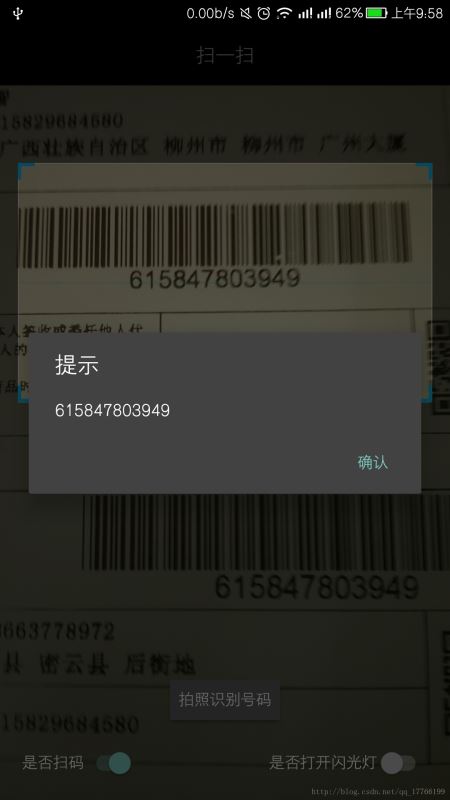
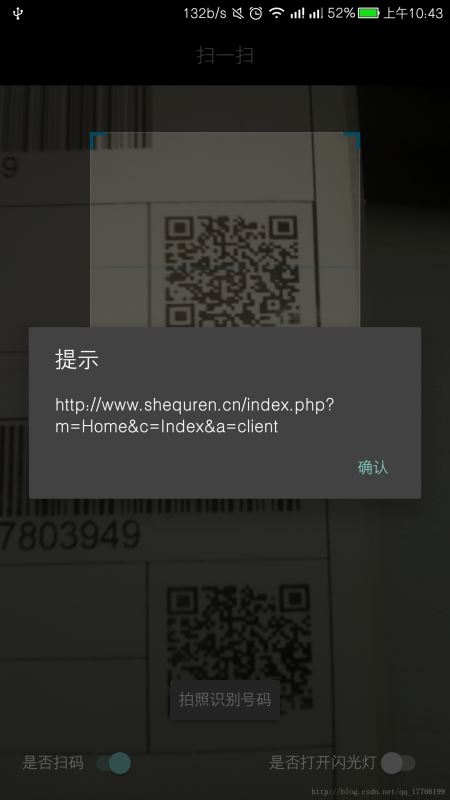
細心的同學可以從圖中看到掃描框的大小都不一樣,這里我是改成了可以手動調節大小的掃描框。畢竟掃碼模式下,框大一點還是比較好識別(將二維碼放入框中有時就費時間)。掃數字這些文字時,框小一點會好識別。具體可以下載自行體驗。
最后我將代碼已經上傳至Github:Tesseract-OCR-Scanner
總結
以上所述是小編給大家介紹的Android實現掃一掃識別數字功能,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對億速云網站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





