溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
吐槽
以前都是手擼RPC,最近接觸SpringCloud,深感痛心。主要有以下幾點:
1)代碼量巨大,找BUG時間長,超級復雜的設計
2)版本管理混亂,經常出現莫名其妙的配置錯誤(所以2.0是打死不敢上生產啊)
3)Netflix公司的有些代碼,實在是讓人費解,根本就不考慮擴展性
4)生態鏈龐大,學習成本大
建議準備上微服務的同學,固定下一個版本,不要隨意更新或降級。拿tomcat的basedir來說,1.5.8到1.5.13到1.5.16版本是換來換去,不小心點會出事故的。
server: port: 21004 context-path: / tomcat: basedir: file:.
如上,basedir先是從.換到file:.,又從file:.換成.,連兼容代碼都木有。有木有想打死工程師?
前言
今天主要談的話題,是平滑的上下線功能。所謂平滑,指的是發版無感知,不至于等到夜深人靜的時候偷偷去搞。某些請求時間可以長點,但不能失敗,尤其是對支付來說,想花錢花不出去是很讓人苦惱的;花了錢買不到東西是很讓人惱火的。整體來說,SpringCloud功能齊全,經過一段時間的踩坑后使用起來還是非常舒服的。
我們的微服務,大體集成了以下內容。
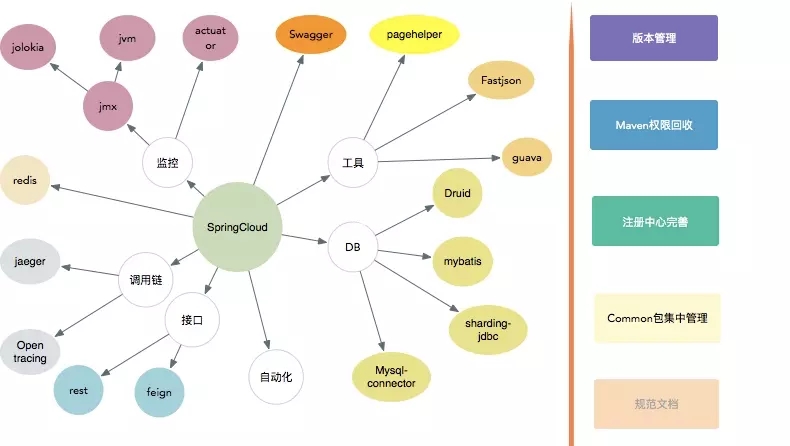
嗯,一個龐大的生態
問題
那么問題來了,SpringCloud到注冊中心的注冊是通過Rest接口調用的。它不能像ZooKeeper那樣,有問題節點反饋及時生效。也不能像Redis那么快的去輪訓,太嬌貴怕輪壞了。如下圖:
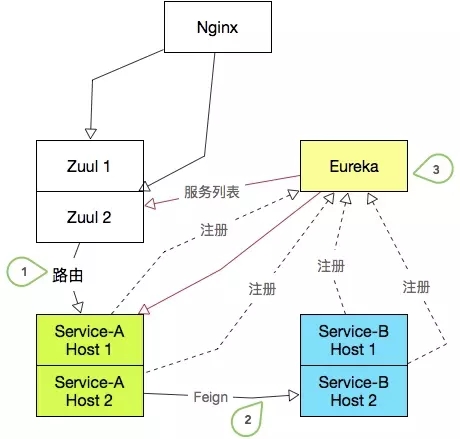
有三個要求:
1)ServiceA下線一臺實例后,Zuul網關的調用不能失敗 2)ServiceB下線一臺實例后,ServiceA的Feign調用不能失敗 3)服務上線下線,Eureka服務能夠快速感知
說白了就一件事,怎樣盡量縮短服務下線后Zuul和其他被依賴服務的發現時間,并在這段時間內保證請求不失敗。
解決時間問題
影響因子
1) Eureka的兩層緩存問題 (這是什么鬼)
EurekaServer默認有兩個緩存,一個是ReadWriteMap,另一個是ReadOnlyMap。有服務提供者注冊服務或者維持心跳時時,會修改ReadWriteMap。當有服務調用者查詢服務實例列表時,默認會從ReadOnlyMap讀取(這個在原生Eureka可以配置,SpringCloud Eureka中不能配置,一定會啟用ReadOnlyMap讀取),這樣可以減少ReadWriteMap讀寫鎖的爭用,增大吞吐量。EurekaServer定時把數據從ReadWriteMap更新到ReadOnlyMap中
2) 心跳時間
服務提供者注冊服務后,會定時心跳。這個根據服務提供者的Eureka配置中的服務刷新時間決定。還有個配置是服務過期時間,這個配置在服務提供者配置但是在EurekaServer使用了,但是默認配置EurekaServer不會啟用這個字段。需要配置好EurekaServer的掃描失效時間,才會啟用EurekaServer的主動失效機制。在這個機制啟用下:每個服務提供者會發送自己服務過期時間上去,EurekaServer會定時檢查每個服務過期時間和上次心跳時間,如果在過期時間內沒有收到過任何一次心跳,同時沒有處于保護模式下,則會將這個實例從ReadWriteMap中去掉
3)調用者服務從Eureka拉列表的輪訓間隔
4) Ribbon緩存
解決方式
1) 禁用Eureka的ReadOnlyMap緩存 (Eureka端)
eureka.server.use-read-only-response-cache: false
2) 啟用主動失效,并且每次主動失效檢測間隔為3s (Eureka端)
eureka.server.eviction-interval-timer-in-ms: 3000
像eureka.server.responseCacheUpdateInvervalMs和eureka.server.responseCacheAutoExpirationInSeconds在啟用了主動失效后其實沒什么用了。默認的180s真夠把人給急瘋的。
3) 服務過期時間 (服務提供方)
eureka.instance.lease-expiration-duration-in-seconds: 15
超過這個時間沒有接收到心跳EurekaServer就會將這個實例剔除。EurekaServer一定要設置eureka.server.eviction-interval-timer-in-ms否則這個配置無效,這個配置一般為服務刷新時間配置的三倍。默認90s!
4) 服務刷新時間配置,每隔這個時間會主動心跳一次 (服務提供方)
eureka.instance.lease-renewal-interval-in-seconds: 5
默認30s
5) 拉服務列表時間間隔 (客戶端)
eureka.client.registryFetchIntervalSeconds: 5
默認30s
6) ribbon刷新時間 (客戶端)
ribbon.ServerListRefreshInterval: 5000
ribbon竟然也有緩存,默認30s
這些超時時間相互影響,竟然三個地方都需要配置,一不小心就會出現服務不下線,服務不上線的囧境。不得不說SpringCloud的這套默認參數簡直就是在搞笑。
重試
那么一臺服務器下線,最長的不可用時間是多少呢?(即請求會落到下線的服務器上,請求失敗)。趕的巧的話,這個基本時間就是eureka.client.registryFetchIntervalSeconds+ribbon.ServerListRefreshInterval,大約是8秒的時間。如果算上服務端主動失效的時間,這個時間會增加到11秒。
如果你只有兩個實例,極端情況下服務上線的發現時間也需要11秒,那就是22秒的時間。
理想情況下,在這11秒之間,請求是失敗的。加入你的QPS是1000,部署了四個節點,那么在11秒中失敗的請求數量會是 1000 / 4 * 11 = 2750,這是不可接受的。所以我們要引入重試機制。
SpringCloud引入重試還是比較簡單的。但不是配置一下就可以的,既然用了重試,那么就還需要控制超時。可以按照以下的步驟:
引入pom (千萬別忘了哦)
<dependency> <groupId>org.springframework.retry</groupId> <artifactId>spring-retry</artifactId> </dependency>
加入配置
ribbon.OkToRetryOnAllOperations:true #(是否所有操作都重試,若false則僅get請求重試) ribbon.MaxAutoRetriesNextServer:3 #(重試負載均衡其他實例最大重試次數,不含首次實例) ribbon.MaxAutoRetries:1 #(同一實例最大重試次數,不含首次調用) ribbon.ReadTimeout:30000 ribbon.ConnectTimeout:3000 ribbon.retryableStatusCodes:404,500,503 #(那些狀態進行重試) spring.cloud.loadbalancer.retry.enable:true # (重試開關)
發布系統
OK,機制已經解釋清楚,但是實踐起來還是很繁雜的,讓人焦躁。比如有一個服務有兩個實例,我要一臺一臺的去發布,在發布第二臺之前,起碼要等上11秒。如果手速太快,那就是災難。所以一個配套的發布系統是必要的。
首先可以通過rest請求去請求Eureka,主動去隔離一臺實例,多了這一步,可以減少至少3秒服務不可用的時間(還是比較劃算的)。
然后通過打包工具打包,推包。依次上線替換。
市面上沒有這樣的持續集成哦你工具,那么發布系統就需要定制,這也是一部分工作量。
到此,僅僅是解決了SpringCloud微服務平滑上下線的功能,至于灰度,又是另外一個話題了。有條件的公司選擇自研還是很明智的,不至于將功能拉低到如此的水平。
不過大體不用擔心,你的公司能不能活下去,還是一個未知數。Netflix都忍了,在做的各位能比它強大么?
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





