溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
我們在使用Exchange系統時,都非常想要一個每天可靠而又可用的郵件系統。對于許多公司而言,郵件系統是我們業務連續性計劃的一部分,并且在設計郵件服務部署的時候都應考慮站點恢復。基本上,許多站點恢復解決方案都涉及在第二個數據中心部署。
下面是官方給出的一些前期規劃:
最終,DAG 的總體設計(其中包括 DAG 的成員數和郵箱數據庫副本數)將取決于每個組織的包括各種故障情形的恢復服務級別協議 (SLA)。在規劃階段中,解決方案的結構設計師和管理員將確定部署要求,尤其是站點恢復要求。他們確定要使用的位置和所需的恢復 SLA 目標。SLA 將確定兩個特定的元素,這兩個元素應是設計高可用性和站點恢復解決方案的基礎:恢復時間目標和恢復點目標。這兩個值都以分鐘為單位度量。恢復時間目標是指恢復服務所需的時間。恢復點目標指在完成恢復操作之后數據的新舊程度。還可以將 SLA 定義為在解決主數據中心的問題之后,將還原為完整服務。
解決方案的結構設計師和管理員還將確定哪一組用戶需要站點恢復保護,并確定多網站解決方案是主動/被動配置還是主動/主動配置。在主動/被動配置中,備用數據中心中通常不駐留任何用戶。在主動/主動配置中,用戶同時駐留在兩個位置,在該解決方案中,數據庫總數中有一定的百分比在第二個數據中心的首選活動位置。當一個數據中心的用戶的服務出現故障時,將在另一數據中心中激活這些用戶。
構造適當的 SLA 通常需要考慮以下基本問題:
- > 主數據中心出現故障后,需要什么級別的服務?
- > 用戶是需要數據服務還是僅需要郵件服務?
- > 急需數據的程度怎樣?
- > 必須支持多少用戶?
- > 用戶如何訪問自已的數據?
- > 什么是備用數據中心激活 SLA?
- > 服務如何移回主數據中心?
- > 資源是否專用于站點恢復解決方案?
通過回答這些問題,我們可以設計出一個郵件解決方案構建站點恢復設計的大致框架。從站點故障進行恢復的核心要求是:創建解決方案,將必要的郵件數據放入承載備用郵件服務的備用數據中心。
在本系列博文中,我們采用的是建立跨站點的DAG實現郵件系統的異地容災,即假設我公司總部數據中心在北京、上海也有一個數據中心,用來做Exchange郵件系統的數據備份容災。
當北京數據中心發生災難時,通過手工的方式啟動上海的容災服務器,從而來實現異地容災。RTO小于1小時,RPO小于15分鐘。
下表是我測試環境的網絡信息,全部為虛擬機:
| 服務器名稱 | 操作系統 | IP地址 | 網關 | DNS | 角色 |
|---|---|---|---|---|---|
| BJAD01 | windows server 2012 R2 | 10.1.1.1 | 10.1.1.10 | 10.1.1.1 | 北京域控01 |
| BJEX01 | windows server 2012 R2 | 10.1.1.2 | 10.1.1.10 | 10.1.1.1 | 北京Exchange01 |
| BJEX02 | windows server 2012 R2 | 10.1.1.4 | 10.1.1.10 | 10.1.1.1 | 北京Exchange02 |
| SHAD01 | windows server 2012 R2 | 172.16.1.1 | 172.16.1.10 | 10.1.1.1 | 上海域控01 |
| SHEX01 | windows server 2012 R2 | 172.16.1.2 | 172.16.1.10 | 172.16.1.1 | 上海Exchange01 |
| SHEX02 | windows server 2012 R2 | 172.16.1.3 | 172.16.1.10 | 172.16.1.1 | 上海Exchange02 |
| Router | windows server 2012 R2 | 10.1.1.10 172.16.1.10 | \ | \ | 路由器 |
環境拓撲信息如下: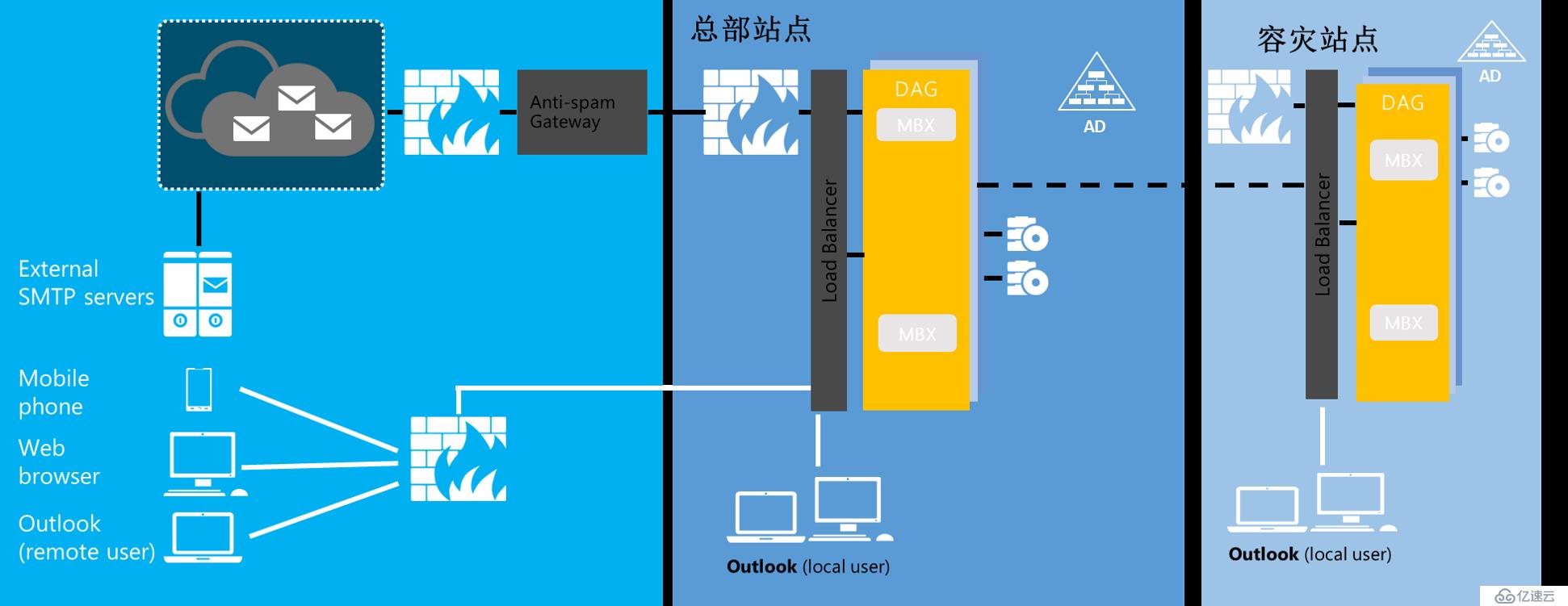
環境準備到此,下一篇我們創建配置路由器!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





