溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
機器學習分兩大類,有監督學習(supervised learning)和無監督學習(unsupervised learning)。有監督學習又可分兩類:分類(classification.)和回歸(regression),分類的任務就是把一個樣本劃為某個已知類別,每個樣本的類別信息在訓練時需要給定,比如人臉識別、行為識別、目標檢測等都屬于分類。回歸的任務則是預測一個數值,比如給定房屋市場的數據(面積,位置等樣本信息)來預測房價走勢。而無監督學習也可以成兩類:聚類(clustering)和密度估計(density estimation),聚類則是把一堆數據聚成弱干組,沒有類別信息;密度估計則是估計一堆數據的統計參數信息來描述數據,比如深度學習的RBM。
根據機器學習實戰講解順序,先學習K近鄰法(K Nearest Neighbors-KNN)
K近鄰法是有監督學習方法,原理很簡單,假設我們有一堆分好類的樣本數據,分好類表示每個樣本都一個對應的已知類標簽,當來一個測試樣本要我們判斷它的類別是,就分別計算到每個樣本的距離,然后選取離測試樣本最近的前K個樣本的標簽累計投票,得票數最多的那個標簽就為測試樣本的標簽。
例子(電影分類):

(圖一)
(圖一)中橫坐標表示一部電影中的打斗統計個數,縱坐標表示接吻次數。我們要對(圖一)中的問號這部電影進行分類,其他幾部電影的統計數據和類別如(圖二)所示:
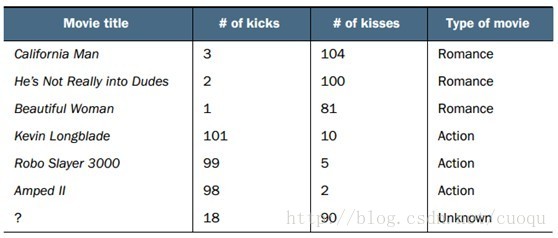
(圖二)
從(圖二)中可以看出有三部電影的類別是Romance,有三部電影的類別是Action,那如何判斷問號表示的這部電影的類別?根據KNN原理,我們需要在(圖一)所示的坐標系中計算問號到所有其他電影之間的距離。計算出的歐式距離如(圖三)所示:
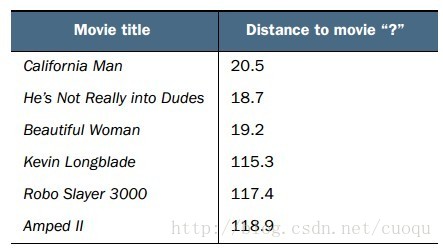
(圖三)
由于我們的標簽只有兩類,那假設我們選K=6/2=3,由于前三個距離最近的電影都是Romance,那么問號表示的電影被判定為Romance。
代碼實戰(Python版本):
先來看看KNN的實現:
from numpy import *
import operator
from os import listdir
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #獲取一條樣本大小
diffMat = tile(inX, (dataSetSize,1)) - dataSet #計算距離
sqDiffMat = diffMat**2 #計算距離
sqDistances = sqDiffMat.sum(axis=1) #計算距離
distances = sqDistances**0.5 #計算距離
sortedDistIndicies = distances.argsort() #距離排序
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]] #前K個距離最近的投票統計
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #前K個距離最近的投票統計
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) #對投票統計進行排序
return sortedClassCount[0][0] #返回最高投票的類別
下面取一些樣本測試KNN:
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def datingClassTest():
hoRatio = 0.50 #hold out 50%
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount
上面的代碼中第一個函數從文本文件中讀取樣本數據,第二個函數把樣本歸一化,歸一化的好處就是降低樣本不同特征之間數值量級對距離計算的顯著性影響
datingClassTest則是對KNN測試,留了一半數據進行測試,文本文件中的每條數據都有標簽,這樣可以計算錯誤率,運行的錯誤率為:the total error rate is: 0.064000
總結:
優點:高精度,對離群點不敏感,對數據不需要假設模型
缺點:判定時計算量太大,需要大量的內存
工作方式:數值或者類別
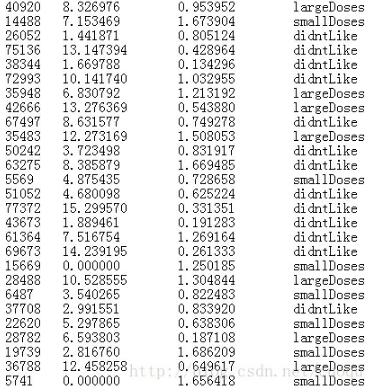
下面挑選一步樣本數據發出來:
參考文獻:machine learning in action
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





