溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python實現購物評論文本情感分析操作,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
具體如下:
昨晚上發現了snownlp這個庫,很開心。先說說我開心的原因。我本科畢業設計做的是文本挖掘,用R語言做的,發現R語言對文本處理特別不友好,沒有很多強大的庫,特別是針對中文文本的,加上那時候還沒有學機器學習算法。所以很頭疼,后來不得已用了一個可視化的軟件RostCM,但是一般可視化軟件最大的缺點是無法調參,很死板,準確率并不高。現在研一,機器學習算法學完以后,又想起來要繼續學習文本挖掘了。所以前半個月開始了用python進行文本挖掘的學習,很多人都推薦我從《python自然語言處理》這本書入門,學習了半個月以后,可能本科畢業設計的時候有些基礎了,再看這個感覺沒太多進步,并且這里通篇將nltk庫進行英文文本挖掘的,英文文本挖掘跟中文是有很大差別的,或者說學完英文文本挖掘,再做中文的,也是完全懵逼的。所以我停了下來,覺得太沒效率了。然后我在網上查找關于python如何進行中文文本挖掘的文章,最后找到了snownlp這個庫,這個庫是國人自己開發的python類庫,專門針對中文文本進行挖掘,里面已經有了算法,需要自己調用函數,根據不同的文本構建語料庫就可以,真的太方便了。我只介紹一下這個庫具體應用,不介紹其中的有關算法原理,因為算法原理可以自己去學習。因為我在學習這個庫的時候,我查了很多資料發現很少或者基本沒有寫這個庫的實例應用,很多都是轉載官網對這個庫的簡介,所以我記錄一下我今天的學習。
首先簡單介紹一下這個庫可以進行哪些文本挖掘。snownlp主要可以進行中文分詞(算法是Character-Based Generative Model)、詞性標注(原理是TnT、3-gram 隱馬)、情感分析(官網木有介紹原理,但是指明購物類的評論的準確率較高,其實是因為它的語料庫主要是購物方面的,可以自己構建相關領域語料庫,替換原來的,準確率也挺不錯的)、文本分類(原理是樸素貝葉斯)、轉換拼音、繁體轉簡體、提取文本關鍵詞(原理是TextRank)、提取摘要(原理是TextRank)、分割句子、文本相似(原理是BM25)。官網還有更多關于該庫的介紹,在看我這個文章之前,建議先看一下官網,里面有最基礎的一些命令的介紹。官網鏈接:https://pypi.python.org/pypi/snownlp/0.11.1。
PS:可以直接使用pip install snownlp 命令進行snownlp模塊的快速安裝(注:這里要求pip版本至少為18.0)。
下面正式介紹實例應用。主要是中文文本的情感分析,我今天從京東網站采集了249條關于筆記本的評論文本作為練習數據,由于我只是想練習一下,沒采集更多。然后人工標注每條評論的情感正負性,情感正負性就是指該條評論代表了評論者的何種態度,是褒義還是貶義。以下是樣例
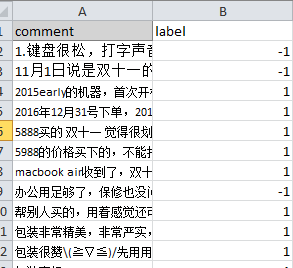
其中-1表示貶義,1表示褒義。由于snownlp全部是unicode編碼,所以要注意數據是否為unicode編碼。因為是unicode編碼,所以不需要去除中文文本里面含有的英文,因為都會被轉碼成統一的編碼(補充一下,關于編碼問題,我還是不特別清楚,所以這里不多講,還請對這方面比較熟悉的伙伴多多指教)。軟件本身默認的是Ascii編碼,所以第一步先設置軟件的默認編碼為utf-8,代碼如下:
1、改變軟件默認編碼
import sys
reload(sys)
sys.setdefaultencoding('utf-8')2、然后準備數據
import pandas as pd #加載pandas
text=pd.read_excel(u'F:/自然語言處理/評論文本.xlsx',header=0) #讀取文本數據
text0=text.iloc[:,0] #提取所有數據
text1=[i.decode('utf-8') for i in text0] #上一步提取數據不是字符而是object,所以在這一步進行轉碼為字符3、訓練語料庫
from snownlp import sentiment #加載情感分析模塊
sentiment.train('E:/Anaconda2/Lib/site-packages/snownlp/sentiment/neg.txt', 'E:/Anaconda2/Lib/site-packages/snownlp/sentiment/pos.txt') #對語料庫進行訓練,把路徑改成相應的位置。我這次練習并沒有構建語料庫,用了默認的,所以把路徑寫到了sentiment模塊下。
sentiment.save('D:/pyscript/sentiment.marshal')#這一步是對上一步的訓練結果進行保存,如果以后語料庫沒有改變,下次不用再進行訓練,直接使用就可以了,所以一定要保存,保存位置可以自己決定,但是要把`snownlp/seg/__init__.py`里的`data_path`也改成你保存的位置,不然下次使用還是默認的。4、進行預測
from snownlp import SnowNLP senti=[SnowNLP(i).sentiments for i in text1] #遍歷每條評論進行預測
5、進行驗證準確率
預測結果為positive的概率,positive的概率大于等于0.6,我認為可以判斷為積極情感,小于0.6的判斷為消極情感。所以以下將概率大于等于0.6的評論標簽賦為1,小于0.6的評論標簽賦為-1,方便后面與實際標簽進行比較。
newsenti=[] for i in senti: if (i>=0.6): newsenti.append(1) else: newsenti.append(-1) text['predict']=newsenti #將新的預測標簽增加為text的某一列,所以現在text的第0列為評論文本,第1列為實際標簽,第2列為預測標簽 counts=0 for j in range(len(text.iloc[:,0])): #遍歷所有標簽,將預測標簽和實際標簽進行比較,相同則判斷正確。 if text.iloc[j,2]==text.iloc[j,1]: counts+=1 print u"準確率為:%f"%(float(counts)/float(len(text)))#輸出本次預測的準確率
運行結果為:

準確率還可以,但還不算高,原因是我考慮時間原因,并且我只是練習一下,所以沒有自己構建該領域的語料庫,如果構建了相關語料庫,替換默認語料庫,準確率會高很多。所以語料庫是非常關鍵的,如果要正式進行文本挖掘,建議要構建自己的語料庫。在沒有構建新的語料庫的情況下,這個83.9357%的準確率還是不錯了。
關于“Python實現購物評論文本情感分析操作”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





