溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關使用Node.js怎么實現進程管理,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
node提供了child_process模塊用來進行子進程的創建,該模塊一共有四個方法用來創建子進程。
const { spawn, exec, execFile, fork } = require('child_process')
spawn(command[, args][, options])
exec(command[, options][, callback])
execFile(file[, args][, options][, callback])
fork(modulePath[, args][, options])spawn
首先認識一下spawn方法,下面是Node文檔的官方實例。
const { spawn } = require('child_process');
const child = spawn('ls', ['-lh', '/home']);
child.on('close', (code) => {
console.log(`子進程退出碼:$[code]`);
});
const { stdin, stdout, stderr } = child
stdout.on('data', (data) => {
console.log(`stdout: ${data}`);
});
stderr.on('data', (data) => {
console.log(`stderr: ${data}`);
});通過spawn創建的子進程,繼承自EventEmitter,所以可以在上面進行事件(discount,error,close,message)的監聽。同時子進程具有三個輸入輸出流:stdin、stdout、stderr,通過這三個流,可以實時獲取子進程的輸入輸出和錯誤信息。
這個方法的最終實現基于libuv,這里不再展開討論,感興趣可以查看源碼。
// 調用libuv的api,初始化一個進程 int err = uv_spawn(env->event_loop(), &wrap->process_, &options);
exec/execFile
之所以把這兩個放到一起,是因為exec最后調用的就是execFile方法。唯一的區別是,exec中調用的normalizeExecArgs方法會將opts的shell屬性默認設置為true。
exports.exec = function exec(/* command , options, callback */) {
const opts = normalizeExecArgs.apply(null, arguments);
return exports.execFile(opts.file, opts.options, opts.callback);
};
function normalizeExecArgs(command, options, callback) {
options = { ...options };
options.shell = typeof options.shell === 'string' ? options.shell : true;
return { options };
}在execFile中,最終調用的是spawn方法。
exports.execFile = function execFile(file /* , args, options, callback */) {
let args = [];
let callback;
let options;
var child = spawn(file, args, {
// ... some options
});
return child;
}exec會將spawn的輸入輸出流轉換成String,默認使用UTF-8的編碼,然后傳遞給回調函數,使用回調方式在node中較為熟悉,比流更容易操作,所以我們能使用exec方法執行一些shell命令,然后在回調中獲取返回值。有點需要注意,這里的buffer是有最大緩存區的,如果超出會直接被kill掉,可用通過maxBuffer屬性進行配置(默認: 200*1024)。
const { exec } = require('child_process');
exec('ls -lh /home', (error, stdout, stderr) => {
console.log(`stdout: ${stdout}`);
console.log(`stderr: ${stderr}`);
});fork
fork最后也是調用spawn來創建子進程,但是fork是spawn的一種特殊情況,用于衍生新的 Node.js 進程,會產生一個新的V8實例,所以執行fork方法時需要指定一個js文件。
exports.fork = function fork(modulePath /* , args, options */) {
// ...
options.shell = false;
return spawn(options.execPath, args, options);
};通過fork創建子進程之后,父子進程直接會創建一個IPC(進程間通信)通道,方便父子進程直接通信,在js層使用 process.send(message) 和 process.on('message', msg => {}) 進行通信。而在底層,實現進程間通信的方式有很多,Node的進程間通信基于libuv實現,不同操作系統實現方式不一致。在*unix系統中采用Unix Domain Socket方式實現,Windows中使用命名管道的方式實現。
常見進程間通信方式:消息隊列、共享內存、pipe、信號量、套接字
下面是一個父子進程通信的實例。
parent.js
const path = require('path')
const { fork } = require('child_process')
const child = fork(path.join(__dirname, 'child.js'))
child.on('message', msg => {
console.log('message from child', msg)
});
child.send('hello child, I\'m master')child.js
process.on('message', msg => {
console.log('message from master:', msg)
});
let counter = 0
setInterval(() => {
process.send({
child: true,
counter: counter++
})
}, 1000);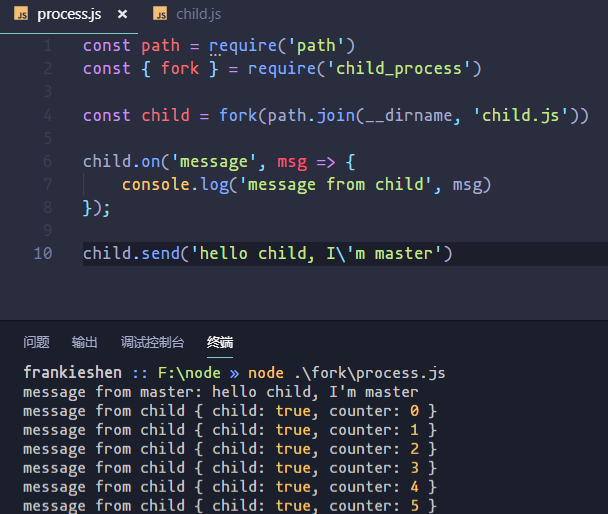
小結
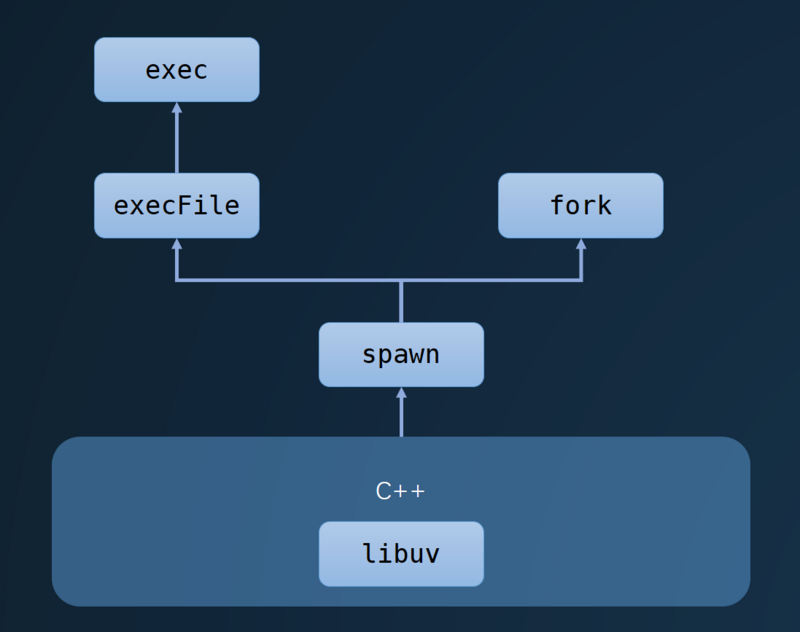
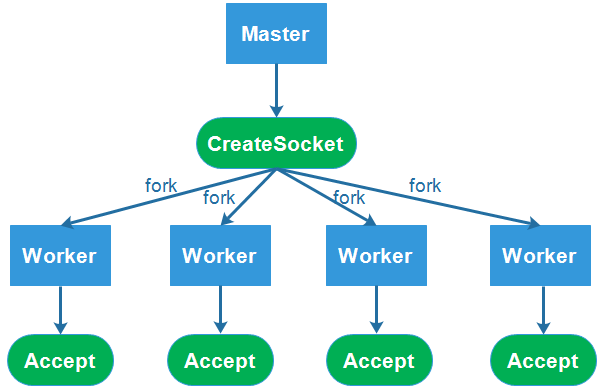
其實可以看到,這些方法都是對spawn方法的復用,然后spawn方法底層調用了libuv進行進程的管理,具體可以看下圖。
首先來看看,如果我們在child.js中啟動一個http服務會發生什么情況。
// master.js
const { fork } = require('child_process')
for (let i = 0; i < 2; i++) {
const child = fork('./child.js')
}
// child.js
const http = require('http')
http.createServer((req, res) => {
res.end('Hello World\n');
}).listen(8000)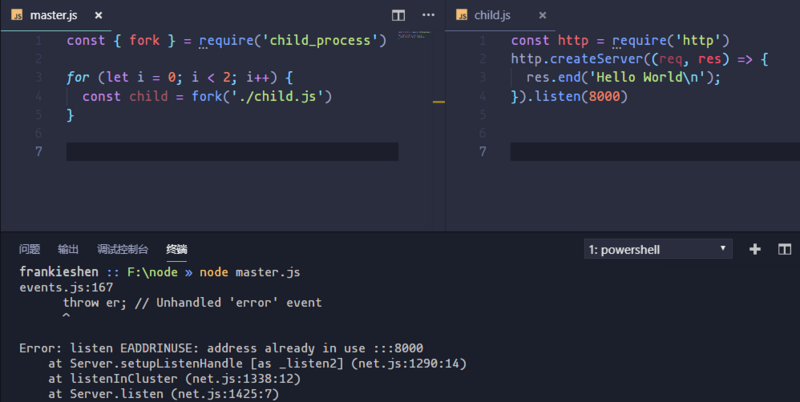
+--------------+ | | | master | | | +--------+--------------+- -- -- - | | | Error: listen EADDRINUSE | | | +----v----+ +-----v---+ | | | | | worker1 | | worker2 | | | | | +---------+ +---------+ :8000 :8000
我們fork了兩個子進程,因為兩個子進程同時對一個端口進行監聽,Node會直接拋出一個異常(Error: listen EADDRINUSE),如上圖所示。那么我們能不能使用代理模式,同時監聽多個端口,讓master進程監聽80端口收到請求時,再將請求分發給不同服務,而且master進程還能做適當的負載均衡。
+--------------+ | | | master | | :80 | +--------+--------------+---------+ | | | | | | | | +----v----+ +-----v---+ | | | | | worker1 | | worker2 | | | | | +---------+ +---------+ :8000 :8001
但是這么做又會帶來另一個問題,代理模式中十分消耗文件描述符(linux系統默認的最大文件描述符限制是1024),文件描述符在windows系統中稱為句柄(handle),習慣性的我們也可以稱linux中的文件描述符為句柄。當用戶進行訪問,首先連接到master進程,會消耗一個句柄,然后master進程再代理到worker進程又會消耗掉一個句柄,所以這種做法十分浪費系統資源。為了解決這個問題,Node的進程間通信可以發送句柄,節省系統資源。
句柄是一種特殊的智能指針 。當一個應用程序要引用其他系統(如數據庫、操作系統)所管理的內存塊或對象時,就要使用句柄。
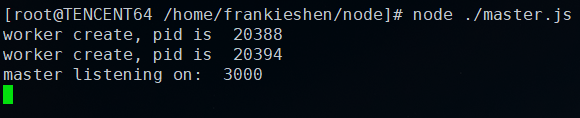
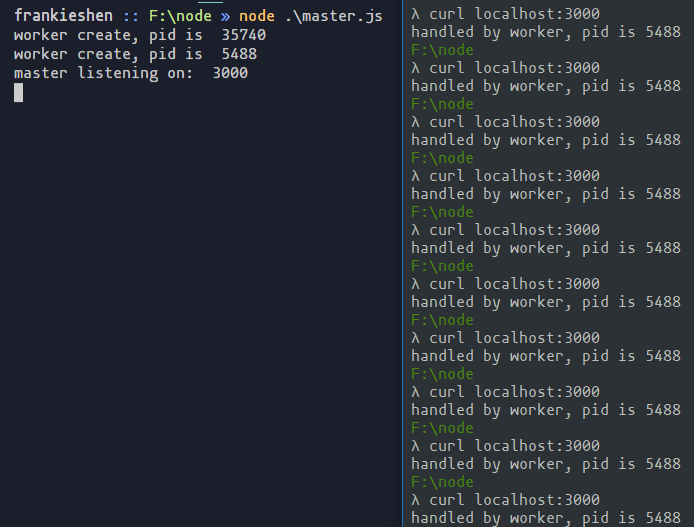
我們可以在master進程啟動一個tcp服務,然后通過IPC將服務的句柄發送給子進程,子進程再對服務的連接事件進行監聽,具體代碼如下:
// master.js
var { fork } = require('child_process')
var server = require('net').createServer()
server.on('connection', function(socket) {
socket.end('handled by master') // 響應來自master
})
server.listen(3000, function() {
console.log('master listening on: ', 3000)
})
for (var i = 0; i < 2; i++) {
var child = fork('./child.js')
child.send('server', server) // 發送句柄給worker
console.log('worker create, pid is ', child.pid)
}
// child.js
process.on('message', function (msg, handler) {
if (msg !== 'server') {
return
}
// 獲取到句柄后,進行請求的監聽
handler.on('connection', function(socket) {
socket.end('handled by worker, pid is ' + process.pid)
})
})
下面我們通過curl連續請求 5 次服務。
for varible1 in {1..5}
do
curl "localhost:3000"
done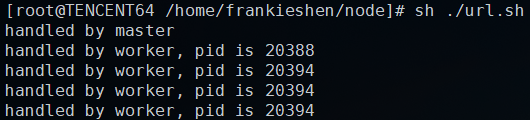
可以看到,響應請求的可以是父進程,也可以是不同子進程,多個進程對同一個服務響應的連接事件監聽,誰先搶占,就由誰進行響應。這里就會出現一個Linux網絡編程中很常見的事件,當多個進程同時監聽網絡的連接事件,當這個有新的連接到達時,這些進程被同時喚醒,這被稱為“驚群”。這樣導致的情況就是,一旦事件到達,每個進程同時去響應這一個事件,而最終只有一個進程能處理事件成功,其他的進程在處理該事件失敗后重新休眠,造成了系統資源的浪費。
ps:在windows系統上,永遠都是最后定義的子進程搶占到句柄,這可能和libuv的實現機制有關,具體原因往有大佬能夠指點。
出現這樣的問題肯定是大家都不愿意的嘛,這個時候我們就想起了nginx的好了,這里有篇文章講解了nginx是如何解決“驚群”的,利用nginx的反向代理可以有效地解決這個問題,畢竟nginx本來就很擅長這種問題。
http {
upstream node {
server 127.0.0.1:8000;
server 127.0.0.1:8001;
server 127.0.0.1:8002;
server 127.0.0.1:8003;
keepalive 64;
}
server {
listen 80;
server_name shenfq.com;
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Nginx-Proxy true;
proxy_set_header Connection "";
proxy_pass http://node; # 這里要和最上面upstream后的應用名一致,可以自定義
}
}
}小結
如果我們自己用Node原生來實現一個多進程模型,存在這樣或者那樣的問題,雖然最終我們借助了nginx達到了這個目的,但是使用nginx的話,我們需要另外維護一套nginx的配置,而且如果有一個Node服務掛了,nginx并不知道,還是會將請求轉發到那個端口。
除了用nginx做反向代理,node本身也提供了一個cluster模塊,用于多核CPU環境下多進程的負載均衡。cluster模塊創建子進程本質上是通過child_procee.fork,利用該模塊可以很容易的創建共享同一端口的子進程服務器。
上手指南
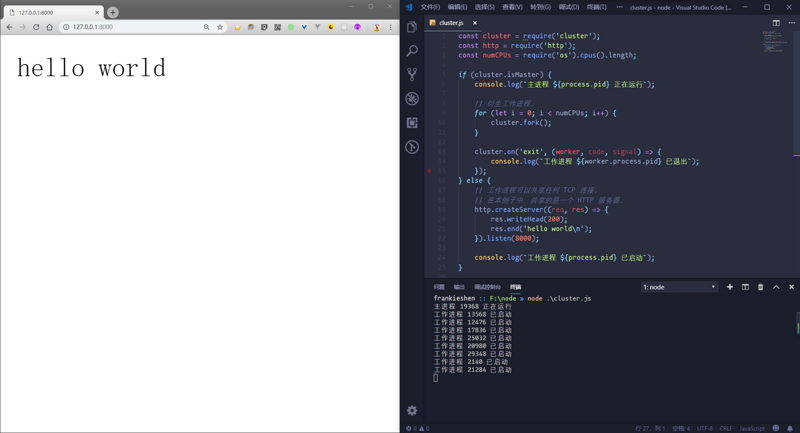
有了這個模塊,你會感覺實現Node的單機集群是多么容易的一件事情。下面看看官方實例,短短的十幾行代碼就實現了一個多進程的Node服務,且自帶負載均衡。
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) { // 判斷是否為主進程
console.log(`主進程 ${process.pid} 正在運行`);
// 衍生工作進程。
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`工作進程 ${worker.process.pid} 已退出`);
});
} else { // 子進程進行服務器創建
// 工作進程可以共享任何 TCP 連接。
// 在本例子中,共享的是一個 HTTP 服務器。
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`工作進程 ${process.pid} 已啟動`);
}
首先看代碼,通過isMaster來判斷是否為主進程,如果是主進程進行fork操作,子進程創建服務器。這里cluster進行fork操作時,執行的是當前文件。cluster.fork最終調用的child_process.fork,且第一個參數為process.argv.slice(2),在fork子進程之后,會對其internalMessage事件進行監聽,這個后面會提到,具體代碼如下:
const { fork } = require('child_process');
cluster.fork = function(env) {
cluster.setupMaster();
const id = ++ids;
const workerProcess = createWorkerProcess(id, env);
const worker = new Worker({
id: id,
process: workerProcess
});
// 監聽子進程的消息
worker.process.on('internalMessage', internal(worker, onmessage));
// ...
};
// 配置master進程
cluster.setupMaster = function(options) {
cluster.settings = {
args: process.argv.slice(2),
exec: process.argv[1],
execArgv: process.execArgv,
silent: false,
...cluster.settings,
...options
};
};
// 創建子進程
function createWorkerProcess(id, env) {
return fork(cluster.settings.exec, cluster.settings.args, {
// some options
});
}子進程端口監聽問題
這里會有一個問題,子進程全部都在監聽同一個端口,我們之前已經試驗過,服務監聽同一個端口會出現端口占用的問題,那么cluster模塊如何保證端口不沖突的呢? 查閱源碼發現,http模塊的createServer繼承自net模塊。
util.inherits(Server, net.Server);
而在net模塊中,listen方法會調用listenInCluster方法,listenInCluster判斷當前是否為master進程。
lib/net.js
Server.prototype.listen = function(...args) {
// ...
if (typeof options.port === 'number' || typeof options.port === 'string') {
// 如果listen方法只傳入了端口號,最后會走到這里
listenInCluster(this, null, options.port | 0, 4, backlog, undefined, options.exclusive);
return this;
}
// ...
};
function listenInCluster(server, address, port, addressType, backlog, fd, exclusive, flags) {
if (cluster === undefined) cluster = require('cluster');
if (cluster.isMaster) {
// 如果是主進程則啟動一個服務
// 但是主進程沒有調用過listen方法,所以沒有走這里一步
server._listen2(address, port, addressType, backlog, fd, flags);
return;
}
const serverQuery = {
address: address,
port: port,
addressType: addressType,
fd: fd,
flags,
};
// 子進程獲取主進程服務的句柄
cluster._getServer(server, serverQuery, listenOnMasterHandle);
function listenOnMasterHandle(err, handle) {
server._handle = handle; // 重寫handle,對listen方法進行了hack
server._listen2(address, port, addressType, backlog, fd, flags);
}
}看上面代碼可以知道,真正啟動服務的方法為server._listen2。在_listen2方法中,最終調用的是_handle下的listen方法。
function setupListenHandle(address, port, addressType, backlog, fd, flags) {
// ...
this._handle.onconnection = onconnection;
var err = this._handle.listen(backlog || 511);
// ...
}
Server.prototype._listen2 = setupListenHandle; // legacy alias那么cluster._getServer方法到底做了什么呢?
搜尋它的源碼,首先向master進程發送了一個消息,消息類型為queryServer。
// child.js
cluster._getServer = function(obj, options, cb) {
// ...
const message = {
act: 'queryServer',
index,
data: null,
...options
};
// 發送消息到master進程,消息類型為 queryServer
send(message, (reply, handle) => {
rr(reply, indexesKey, cb); // Round-robin.
});
// ...
};這里的rr方法,對前面提到的_handle.listen進行了hack,所有子進程的listen其實是不起作用的。
function rr(message, indexesKey, cb) {
if (message.errno)
return cb(message.errno, null);
var key = message.key;
function listen(backlog) { // listen方法直接返回0,不再進行端口監聽
return 0;
}
function close() {
send({ act: 'close', key });
}
function getsockname(out) {
return 0;
}
const handle = { close, listen, ref: noop, unref: noop };
handles.set(key, handle); // 根據key將工作進程的 handle 進行緩存
cb(0, handle);
}
// 這里的cb回調就是前面_getServer方法傳入的。 參考之前net模塊的listen方法
function listenOnMasterHandle(err, handle) {
server._handle = handle; // 重寫handle,對listen方法進行了hack
// 該方法調用后,會對handle綁定一個 onconnection 方法,最后會進行調用
server._listen2(address, port, addressType, backlog, fd, flags);
}主進程與子進程通信
那么到底在哪里對端口進行了監聽呢?
前面提到過,fork子進程的時候,對子進程進行了internalMessage事件的監聽。
worker.process.on('internalMessage', internal(worker, onmessage));子進程向master進程發送消息,一般使用process.send方法,會被監聽的message事件所接收。這里是因為發送的message指定了cmd: 'NODE_CLUSTER',只要cmd字段以NODE_開頭,這樣消息就會認為是內部通信,被internalMessage事件所接收。
// child.js
function send(message, cb) {
return sendHelper(process, message, null, cb);
}
// utils.js
function sendHelper(proc, message, handle, cb) {
if (!proc.connected)
return false;
// Mark message as internal. See INTERNAL_PREFIX in lib/child_process.js
message = { cmd: 'NODE_CLUSTER', ...message, seq };
if (typeof cb === 'function')
callbacks.set(seq, cb);
seq += 1;
return proc.send(message, handle);
}master進程接收到消息后,根據act的類型開始執行不同的方法,這里act為queryServer。queryServer方法會構造一個key,如果這個key(規則主要為地址+端口+文件描述符)之前不存在,則對RoundRobinHandle構造函數進行了實例化,RoundRobinHandle構造函數中啟動了一個TCP服務,并對之前指定的端口進行了監聽。
// master.js
const handles = new Map();
function onmessage(message, handle) {
const worker = this;
if (message.act === 'online')
online(worker);
else if (message.act === 'queryServer')
queryServer(worker, message);
// other act logic
}
function queryServer(worker, message) {
// ...
const key = `${message.address}:${message.port}:${message.addressType}:` +
`${message.fd}:${message.index}`;
var handle = handles.get(key);
// 如果之前沒有對該key進行實例化,則進行實例化
if (handle === undefined) {
let address = message.address;
// const RoundRobinHandle = require('internal/cluster/round_robin_handle');
var constructor = RoundRobinHandle;
handle = new constructor(key,
address,
message.port,
message.addressType,
message.fd,
message.flags);
handles.set(key, handle);
}
// ...
}
// internal/cluster/round_robin_handle
function RoundRobinHandle(key, address, port, addressType, fd, flags) {
this.server = net.createServer(assert.fail);
// 這里啟動一個TCP服務器
this.server.listen({ port, host });
// TCP服務器啟動時的事件
this.server.once('listening', () => {
this.handle = this.server._handle;
this.handle.onconnection = (err, handle) => this.distribute(err, handle);
});
// ...
}可以看到TCP服務啟動后,立馬對connection事件進行了監聽,會調用RoundRobinHandle的distribute方法。
// RoundRobinHandle
this.handle.onconnection = (err, handle) => this.distribute(err, handle);
// distribute 對工作進程進行分發
RoundRobinHandle.prototype.distribute = function(err, handle) {
this.handles.push(handle); // 存入TCP服務的句柄
const worker = this.free.shift(); // 取出第一個工作進程
if (worker)
this.handoff(worker); // 切換到工作進程
};
RoundRobinHandle.prototype.handoff = function(worker) {
const handle = this.handles.shift(); // 獲取TCP服務句柄
if (handle === undefined) {
this.free.push(worker); // 將該工作進程重新放入隊列中
return;
}
const message = { act: 'newconn', key: this.key };
// 向工作進程發送一個類型為 newconn 的消息以及TCP服務的句柄
sendHelper(worker.process, message, handle, (reply) => {
if (reply.accepted)
handle.close();
else
this.distribute(0, handle); // 工作進程不能正常運行,啟動下一個
this.handoff(worker);
});
};在子進程中也有對內部消息進行監聽,在cluster/child.js中,有個cluster._setupWorker方法,該方法會對內部消息監聽,該方法的在lib/internal/bootstrap/node.js中調用,這個文件是每次啟動node命令后,由C++模塊調用的。
鏈接
function startup() {
// ...
startExecution();
}
function startExecution() {
// ...
prepareUserCodeExecution();
}
function prepareUserCodeExecution() {
if (process.argv[1] && process.env.NODE_UNIQUE_ID) {
const cluster = NativeModule.require('cluster');
cluster._setupWorker();
delete process.env.NODE_UNIQUE_ID;
}
}
startup()下面看看_setupWorker方法做了什么。
cluster._setupWorker = function() {
// ...
process.on('internalMessage', internal(worker, onmessage));
function onmessage(message, handle) {
// 如果act為 newconn 調用onconnection方法
if (message.act === 'newconn')
onconnection(message, handle);
else if (message.act === 'disconnect')
_disconnect.call(worker, true);
}
};
function onconnection(message, handle) {
const key = message.key;
const server = handles.get(key);
const accepted = server !== undefined;
send({ ack: message.seq, accepted });
if (accepted)
server.onconnection(0, handle); // 調用net中的onconnection方法
}上述就是小編為大家分享的使用Node.js怎么實現進程管理了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





