溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了使用Python標準庫進行性能測試的方法,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
Profile 和 cProfile
在 Python 標準庫里面有兩個模塊可以用來做性能測試。
1. 一個是 Profile,它是一個純 Python 的實現,所以會慢一些,如果你需要對模塊進行拓展,那么這個模塊比較合適。
2. 第二個是 cProfile,從名字就可以看出這是一個 C 語言的實現版,官方推薦在大多數情況下使用。
這兩者的接口和數據的輸出格式是完全一樣的,你可以在這兩者之間自由的切換,所以下面我們僅以 cProfile 為例進行介紹。
使用 cProfile 進行性能測試
在 cProfile 中,進行性能測試十分簡單,只需調用 run 方法,并將需要測試的函數及參數傳遞給它即可,下面我們對fib(n) 進行性能測試。
import cProfile
def fib(n):
if n == 0:
return 0
if n == 1:
return 1
return fib(n-1) + fib(n-2)
if __name__ == '__main__':
cProfile.run('fib(30)')性能測試的結果如下圖
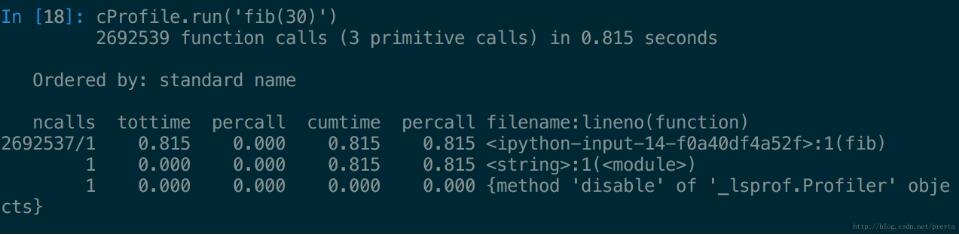
可以看到一共進行了 2692539 次函數調用,共耗時 0.815 秒。下面每一行對應于一個函數的調用情況,其中:
1. ncalls, 函數總共調用次數;
2. tottime, 這個函數調用總共花費時間;
3. percall, 每個調用的平均花費時間;
4. cumtime, 總共累計花費時間;
5. percall, 每個調用的平均累計時間;
6. filename:lineno(function), 對應函數信息。
所以從圖中可以明顯看到幾乎的耗時都在fib上,而且函數調用數過多,這主要是因為函數是遞歸調用的,并且會產生很多冗余分支,所以程序需要進行優化。有兩種方法進行改進,一是緩存fib(n)的信息,不需要每次都進行計算;二是將程序改為迭代式。
而對函數值進行緩存在 Python 3 里有一個簡單的裝飾器叫做lru_cache,可以自動的幫你緩存函數的值,而不需要自己手動存儲。
import functools @functools.lru_cache(maxsize=None) def fib(n): if n == 0: return 0 if n == 1: return 1 return fib(n-1) + fib(n-2)
運行結果如下:
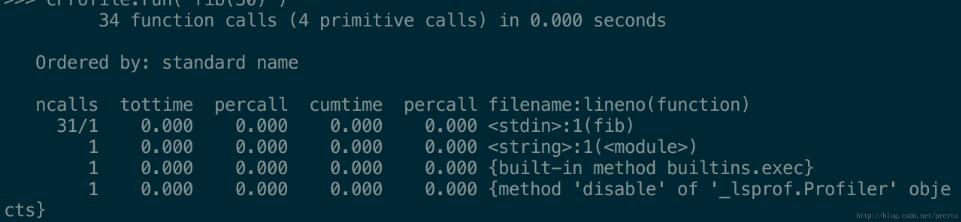
可以看到,fib 函數只調用了 31 次,幾乎所有額外的調用都命中了緩存,遠遠小于前面的調用次數,運行時間也得到了相當明顯的提升。同時使用下面的迭代版程序也運行得非常快,這里就不再展開。
def fib(n): prev, cur = 0, 1 if n == 0: return prev if n == 1: return cur count = 1 while count < n: count += 1 prev, cur = cur, prev + cur return cur
除了前面提到的 run 方法外,還有一個叫做 runctx 的方法,允許提供一些上下文參數。例如前面的 cProfile.run('fib(30)') 可以改為cProfile.runctx('fib', globals(), {'n':30})最后的運行結果是相同的。
最后,除了直接打印到命令行的方式,run 和 runctx 可以通過第二個參數傳遞文件名的方式將輸出結果寫入文件。
使用 pstats 對顯示進行控制
cProfile 雖然可以對程序進行簡單的性能測試,但是當程序過大,調用函數很多的時候,就需要一些對測試結果進行過濾和排序的工具了,而 pstats 就是這樣的一個工具。
# fib_profile.py
import cProfile
import pstats
for i in range(5):
cProfile.run('fib(1000)', 'fib_profile_{}'.format(i))
stats = pstats.Stats('fib_profile_0')
for i in range(1, 5):
stats.add('fib_profile_{}'.format(i))
stats.strip_dirs()
stats.sort_stats('cumulative')
stats.print_stats('fib')上面的程序首先寫入了多個測試結果,然后初始化了 stats,可以通過 stats 的 add 方法添加新的文件,pstats 會自動的將結果聚合起來;然后 strip_dirs 將會移除文件名前面的路徑,只保留文件名;sort_stats 是對輸出結果進行排序,也就是在前面所說的那幾行里進行選擇(具體的可參閱官方文檔);最后的 print_stats 對結果進行輸出,在這面可以對行進行過濾,比如上面的程序就只輸出了包含 fib 的行;實際輸出結果如下。
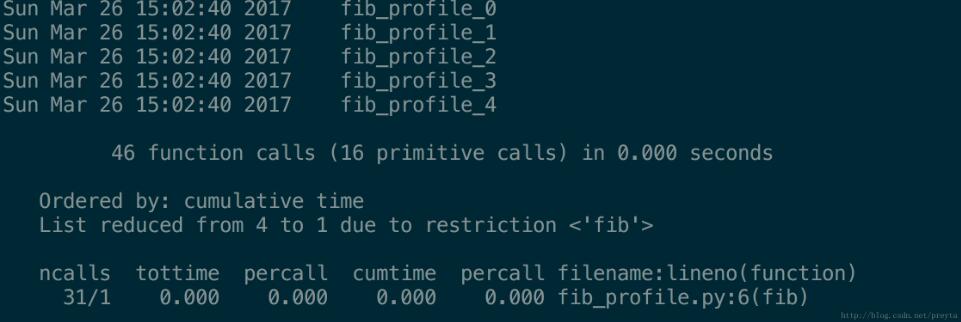
感謝你能夠認真閱讀完這篇文章,希望小編分享的“使用Python標準庫進行性能測試的方法”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





