溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Python如何實現圖片文字識別功能,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
OCR與Tesseract介紹
將圖片翻譯成文字一般被稱為光學文字識別(Optical Character Recognition,OCR)。可以實現OCR 的底層庫并不多,目前很多庫都是使用共同的幾個底層OCR 庫,或者是在上面進行定制。
Tesseract 是一個OCR 庫,目前由Google 贊助(Google 也是一家以OCR 和機器學習技術聞名于世的公司)。Tesseract 是目前公認最優秀、最精確的開源OCR 系統。
除
了極高的精確度,Tesseract 也具有很高的靈活性。它可以通過訓練識別出任何字體(只要這些字體的風格保持不變就可以),也可以識別出任何Unicode 字符。
Tesseract的安裝與使用
Tesseract的Windows安裝包下載地址為: http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe ,下載后雙擊直接安裝即可。安裝完后,需要將Tesseract添加到系統變量中。在CMD中輸入tesseract -v, 如顯示以下界面,則表示Tesseract安裝完成且添加到系統變量中。
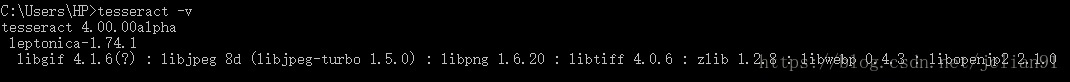
Linux 用戶可以通過apt-get 安裝:
$sudo apt-get tesseract-ocr
用Tesseract可以識別格式規范的文字,主要具有以下特點:
? 使用一個標準字體(不包含手寫體、草書,或者十分“花哨的”字體)
? 雖然被復印或拍照,字體還是很清晰,沒有多余的痕跡或污點
? 排列整齊,沒有歪歪斜斜的字
? 沒有超出圖片范圍,也沒有殘缺不全,或緊緊貼在圖片的邊緣
下面將給出幾個tesseract識別圖片中文字的例子。
首先是E://figures/other/poems.jpg, 輸入命令 tesseract E://figures/other/poems.jpg E://figures/other/poems.txt, 則會將poems.jpg中的識別文字寫入到poems.txt中,如下圖:



接著是稍微有點傾斜的文字圖片th.jpg,識別情況如下:

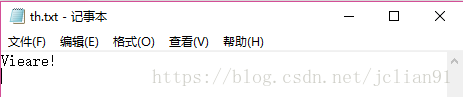
可以看到識別的情況不如剛才規范字體的好,但是也能識別圖片中的大部分字母。
最后是識別簡體中文,需要事先安裝簡體中文語言包,下載地址為: https://github.com/tesseract-ocr/tessdata/find/master/chi_sim.traineddata ,再講chi_sim.traineddata放在C:\Program Files (x86)\Tesseract-OCR\tessdata目錄下。我們以圖片timg.jpg為例:

輸入命令:
tesseract E://figures/other/timg.jpg E://figures/other/timg.txt -l chi_sim
識別結果如下:

只識別錯了一個字,識別率還是不錯的。
最后加一句,Tesseract對于彩色圖片的識別效果沒有黑白圖片的效果好。
pytesseract
pytesseract是Tesseract關于Python的接口,可以使用pip install pytesseract安裝。安裝完后,就可以使用Python調用Tesseract了,不過,你還需要一個Python的圖片處理模塊,可以安裝pillow.
輸入以下代碼,可以實現同上述Tesseract命令一樣的效果:
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe'
text = pytesseract.image_to_string(Image.open('E://figures/other/poems.jpg'))
print(text)運行結果如下:

以上是“Python如何實現圖片文字識別功能”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





