溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下怎么使用python實現爬蟲抓取小說功能,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
具體如下:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from urllib import request
import re
import os,time
#訪問url,返回html頁面
def get_html(url):
req = request.Request(url)
req.add_header('User-Agent','Mozilla/5.0')
response = request.urlopen(url)
html = response.read()
return html
#從列表頁獲取小說書名和鏈接
def get_books(url):#根據列表頁,返回此頁的{書名:鏈接}的字典
html = get_html(url)
soup = BeautifulSoup(html,'lxml')
fixed_html = soup.prettify()
books = soup.find_all('div',attrs={'class':'bbox'})
book_dict = {}
for book in books:
book_name = book.h4.a.string
book_url = book.h4.a.get('href')
book_dict[book_name] = book_url
return book_dict
#根據書名鏈接,獲取具體的章節{名稱:鏈接} 的字典
def get_parts(url):
html = get_html(url)
soup = BeautifulSoup(html,'lxml')
fixed_html = soup.prettify()
part_urls = soup.find_all('a')
host = "http://www.xiaoshuotxt.org"
part_dict = {}
for p in part_urls:
p_url = str(p.get('href'))
if re.search(r'\d{5}.html',p_url) and ("xiaoshuotxt" not in p_url):
part_dict[p.string] = host + p_url
return part_dict
#根據章節的url獲取具體的章節內容
def get_txt(url):
html = get_html(url)
soup = BeautifulSoup(html,'lxml')
fixed_html = soup.prettify()
title = soup.h2.string #獲取文章標題
content = soup.find('div',attrs={'class':'zw'})
txt = BeautifulSoup.get_text(content) #正文內容
return txt
if __name__ == "__main__":
root_dir= r'e:\books'
#url = 'http://www.xiaoshuotxt.org/mingzhu/index_2.html' #第2頁的小說
url = "http://www.xiaoshuotxt.org/writer/58" #金庸的小說
books = get_books(url)
for book_name,book_url in books.items():
os.mkdir(os.path.join(root_dir,book_name))
part_dict = get_parts(book_url)
print(book_name,"共:",len(part_dict),"章節")
for part_name,part_url in part_dict.items():
print("正在保存:",part_name)
f1 = open(r'e:\books\%s\%s.txt'%(book_name,part_name),'w',encoding='utf-8')#以utf-8編碼創建文件
part_txt = get_txt(part_url)
f1.write(str(part_txt))
f1.close()
time.sleep(2)運行效果:
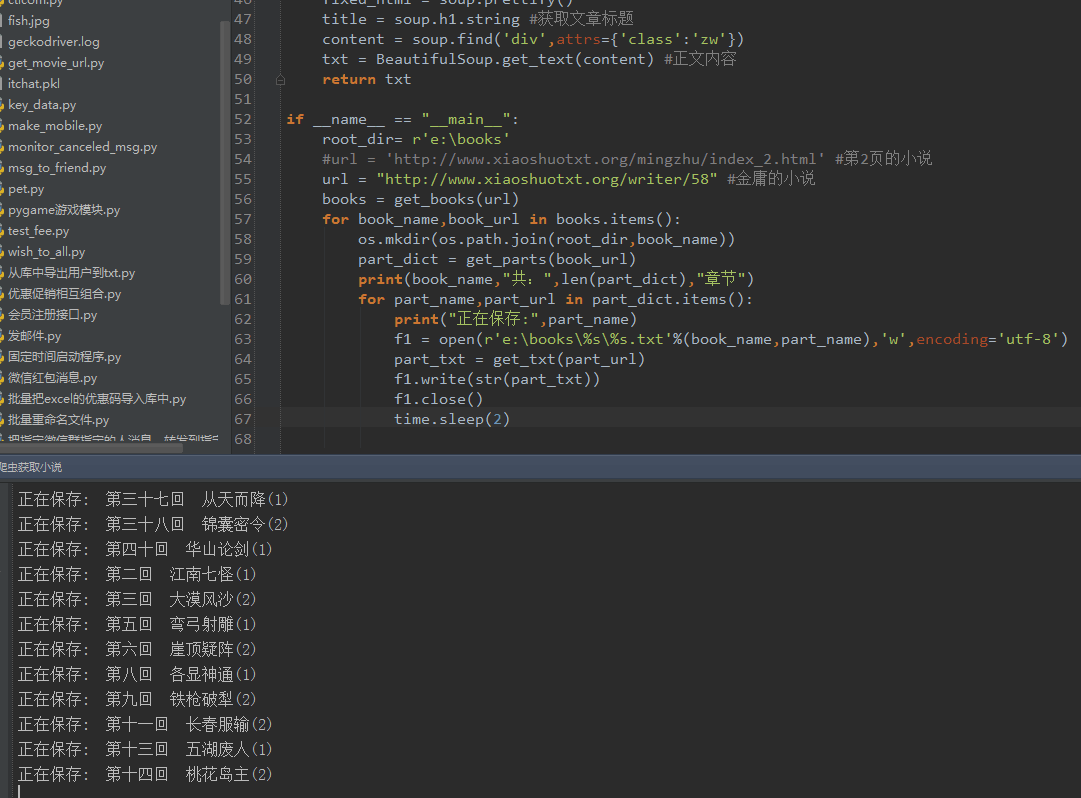
以上是“怎么使用python實現爬蟲抓取小說功能”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





