溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
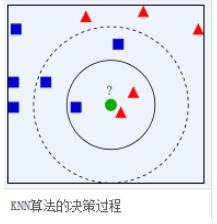
一、KNN算法簡介
鄰近算法,或者說K最近鄰(kNN,k-NearestNeighbor)分類算法是數據挖掘分類技術中最簡單的方法之一。所謂K最近鄰,就是k個最近的鄰居的意思,說的是每個樣本都可以用它最接近的k個鄰居來代表。
kNN算法的核心思想是如果一個樣本在特征空間中的k個最相鄰的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別,并具有這個類別上樣本的特性。該方法在確定分類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。 kNN方法在類別決策時,只與極少量的相鄰樣本有關。由于kNN方法主要靠周圍有限的鄰近的樣本,而不是靠判別類域的方法來確定所屬類別的,因此對于類域的交叉或重疊較多的待分樣本集來說,kNN方法較其他方法更為適合。
二、算法過程
1.讀取數據集
2.處理數據集數據 清洗,采用留出法hold-out拆分數據集:訓練集、測試集
3.實現KNN算法類:
1)遍歷訓練數據集,離差平方和計算各點之間的距離
2)對各點的距離數組進行排序,根據輸入的k值取對應的k個點
3)k個點中,統計每個點出現的次數,權重為距離的導數,得到最大的值,該值的索引就是我們計算出的判定類別
三、代碼實現及數據分析
import numpy as np
import pandas as pd
# 讀取鳶尾花數據集,header參數來指定標題的行。默認為0。如果沒有標題,則使用None。
data = pd.read_csv("你的目錄/Iris.csv",header=0)
# 顯示前n行記錄。默認n的值為5。
#data.head()
# 顯示末尾的n行記錄。默認n的值為5。
#data.tail()
# 隨機抽取樣本。默認抽取一條,我們可以通過參數進行指定抽取樣本的數量。
# data.sample(10)
# 將類別文本映射成為數值類型
data["Species"] = data["Species"].map({"Iris-virginica": 0, "Iris-setosa": 1, "Iris-versicolor": 2})
# 刪除不需要的Id列。
data.drop("Id", axis=1, inplace=True )
data.drop_duplicates(inplace=True)
## 查看各個類別的鳶尾花具有多少條記錄。
data["Species"].value_counts()
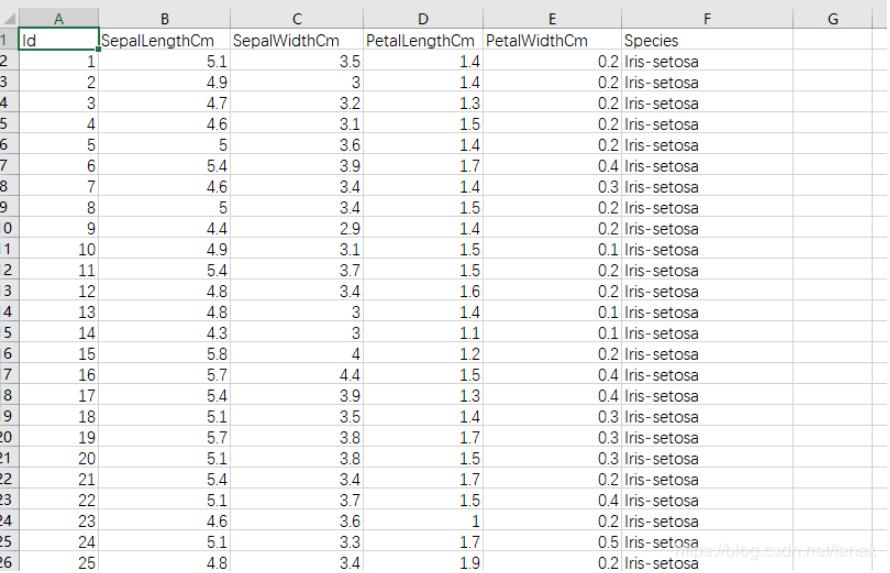
分析:首先讀取數據集,如下圖
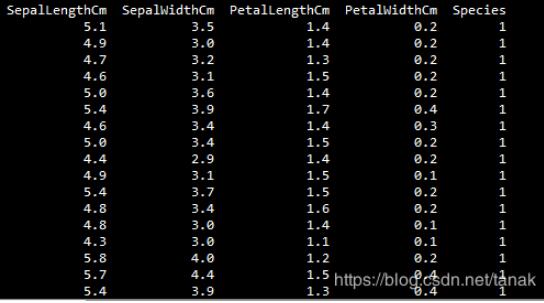
最后一列為數據集的分類名稱,但是在程序中,我們更傾向于使用如0、1、2數字來表示分類,所以對數據集進行處理,處理后的數據集如下:
然后采用留出法對數據集進行拆分,一部分用作訓練,一部分用作測試,如下圖:
#構建訓練集與測試集,用于對模型進行訓練與測試。 # 提取出每個類比的鳶尾花數據 t0 = data[data["Species"] == 0] t1 = data[data["Species"] == 1] t2 = data[data["Species"] == 2] # 對每個類別數據進行洗牌 random_state 每次以相同的方式洗牌 保證訓練集與測試集數據取樣方式相同 t0 = t0.sample(len(t0), random_state=0) t1 = t1.sample(len(t1), random_state=0) t2 = t2.sample(len(t2), random_state=0) # 構建訓練集與測試集。 train_X = pd.concat([t0.iloc[:40, :-1], t1.iloc[:40, :-1], t2.iloc[:40, :-1]] , axis=0)#截取前40行,除最后列外的列,因為最后一列是y train_y = pd.concat([t0.iloc[:40, -1], t1.iloc[:40, -1], t2.iloc[:40, -1]], axis=0) test_X = pd.concat([t0.iloc[40:, :-1], t1.iloc[40:, :-1], t2.iloc[40:, :-1]], axis=0) test_y = pd.concat([t0.iloc[40:, -1], t1.iloc[40:, -1], t2.iloc[40:, -1]], axis=0)
實現KNN算法類:
#定義KNN類,用于分類,類中定義兩個預測方法,分為考慮權重不考慮權重兩種情況 class KNN: ''' 使用Python語言實現K近鄰算法。(實現分類) ''' def __init__(self, k): '''初始化方法 Parameters ----- k:int 鄰居的個數 ''' self.k = k def fit(self,X,y): '''訓練方法 Parameters ---- X : 類數組類型,形狀為:[樣本數量, 特征數量] 待訓練的樣本特征(屬性) y : 類數組類型,形狀為: [樣本數量] 每個樣本的目標值(標簽)。 ''' #將X轉換成ndarray數組 self.X = np.asarray(X) self.y = np.asarray(y) def predict(self,X): """根據參數傳遞的樣本,對樣本數據進行預測。 Parameters ----- X : 類數組類型,形狀為:[樣本數量, 特征數量] 待訓練的樣本特征(屬性) Returns ----- result : 數組類型 預測的結果。 """ X = np.asarray(X) result = [] # 對ndarray數組進行遍歷,每次取數組中的一行。 for x in X: # 對于測試集中的每一個樣本,依次與訓練集中的所有樣本求距離。 dis = np.sqrt(np.sum((x - self.X) ** 2, axis=1)) ## 返回數組排序后,每個元素在原數組(排序之前的數組)中的索引。 index = dis.argsort() # 進行截斷,只取前k個元素。【取距離最近的k個元素的索引】 index = index[:self.k] # 返回數組中每個元素出現的次數。元素必須是非負的整數。【使用weights考慮權重,權重為距離的倒數。】 count = np.bincount(self.y[index], weights= 1 / dis[index]) # 返回ndarray數組中,值最大的元素對應的索引。該索引就是我們判定的類別。 # 最大元素索引,就是出現次數最多的元素。 result.append(count.argmax()) return np.asarray(result)
#創建KNN對象,進行訓練與測試。 knn = KNN(k=3) #進行訓練 knn.fit(train_X,train_y) #進行測試 result = knn.predict(test_X) # display(result) # display(test_y) display(np.sum(result == test_y)) display(np.sum(result == test_y)/ len(result))
得出計算結果:
26
0.9629629629629629
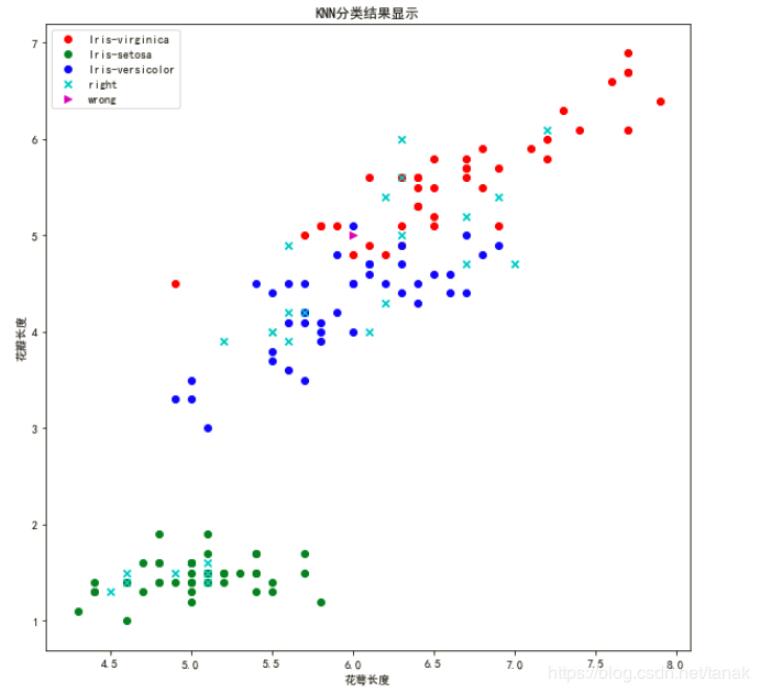
得出該模型計算的結果中,有26條記錄與測試集相等,準確率為96%
接下來繪制散點圖:
#導入可視化所必須的庫。
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
#繪制散點圖。為了能夠更方便的進行可視化,這里只選擇了兩個維度(分別是花萼長度與花瓣長度)。
# {"Iris-virginica": 0, "Iris-setosa": 1, "Iris-versicolor": 2})
# 設置畫布的大小
plt.figure(figsize=(10, 10))
# 繪制訓練集數據
plt.scatter(x=t0["SepalLengthCm"][:40], y=t0["PetalLengthCm"][:40], color="r", label="Iris-virginica")
plt.scatter(x=t1["SepalLengthCm"][:40], y=t1["PetalLengthCm"][:40], color="g", label="Iris-setosa")
plt.scatter(x=t2["SepalLengthCm"][:40], y=t2["PetalLengthCm"][:40], color="b", label="Iris-versicolor")
# 繪制測試集數據
right = test_X[result == test_y]
wrong = test_X[result != test_y]
plt.scatter(x=right["SepalLengthCm"], y=right["PetalLengthCm"], color="c", marker="x", label="right")
plt.scatter(x=wrong["SepalLengthCm"], y=wrong["PetalLengthCm"], color="m", marker=">", label="wrong")
plt.xlabel("花萼長度")
plt.ylabel("花瓣長度")
plt.title("KNN分類結果顯示")
plt.legend(loc="best")
plt.show()
程序運行結果如下:
四、思考與優化
①嘗試去改變鄰居的數量。
②在考慮權重的情況下,修改鄰居的數量。
③對比查看結果上的差異。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





