溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
k-近鄰算法是基本的機器學習算法,算法的原理非常簡單:
輸入樣本數據后,計算輸入樣本和參考樣本之間的距離,找出離輸入樣本距離最近的k個樣本,找出這k個樣本中出現頻率最高的類標簽作為輸入樣本的類標簽,很直觀也很簡單,就是和參考樣本集中的樣本做對比。下面講一講用python實現kNN算法的方法,這里主要用了python中常用的numpy模塊,采用的數據集是來自UCI的一個數據集,總共包含1055個樣本,每個樣本有41個real的屬性和一個類標簽,包含兩類(RB和NRB)。我選取800條樣本作為參考樣本,剩下的作為測試樣本。
下面是分類器的python代碼:
'''
kNNClassify(inputAttr, trainSetPath = '', lenOfInstance = 42, startAttr = 0, stopAttr = 40, posOfClass = 41, numOfRefSamples = 5)函數
參數:
inputAttr:輸入的屬性向量
trainSetPath:字符串,保存訓練樣本的路徑
lenOfInstance:樣本向量的維數
startAttr:屬性向量在整個樣本向量中的起始下標
stopAttr:屬性向量在整個樣本向量中的終止下標
posOfClass:類標簽的在整個樣本向量中的下標
numOfClSamples:選出來進行投票的樣本個數
返回值:
類標簽
'''
def kNNClassify(inputAttr, trainSetPath = '', lenOfInstance = 42, startAttr = 0, stopAttr = 40, posOfClass = 41, numOfRefSamples = 5):
fr = open(trainSetPath)
strOfLine = fr.readline()
arrayOfLine = numpy.array([0.] * lenOfInstance)
refSamples = numpy.array([[-1., 0.]] * numOfRefSamples)
#找出屬性中的最大值和最小值,用于歸一化
maxAttr, minAttr = kNNFunction.dataNorm(trainSetPath = trainSetPath, lenOfInstance = lenOfInstance)
maxAttr = maxAttr[(numpy.array(range(stopAttr - startAttr + 1))
+ numpy.array([startAttr] * (stopAttr - startAttr + 1)))]
minAttr = minAttr[(numpy.array(range(stopAttr - startAttr + 1))
+ numpy.array([startAttr] * (stopAttr - startAttr + 1)))]
attrRanges = maxAttr - minAttr
inputAttr = inputAttr[(numpy.array(range(stopAttr - startAttr + 1))
+ numpy.array([startAttr] * (stopAttr - startAttr + 1)))]
inputAttr = (inputAttr - minAttr) / attrRanges #歸一化
#將字符串轉換為向量并進行計算找出離輸入樣本距離最近的numOfRefSamples個參考樣本
while strOfLine != '' :
strOfLine = strOfLine.strip()
strOfLine = strOfLine.split(';')
abandonOrNot = False
for i in range(lenOfInstance) :
if strOfLine[i] == 'RB' :
arrayOfLine[i] = 1.0
elif strOfLine[i] == 'NRB' :
arrayOfLine[i] = 0.0
elif strOfLine[i] != '?' : #沒有發現缺失值
arrayOfLine[i] = float(strOfLine[i])
abandonOrNot = False
else : #發現缺失值
abandonOrNot = True
break
if abandonOrNot == True :
strOfLine = fr.readline()
continue
else :
attr = arrayOfLine[(numpy.array(range(stopAttr - startAttr + 1))
+ numpy.array([startAttr] * (stopAttr - startAttr + 1)))]
attr = (attr - minAttr) / attrRanges #歸一化
classLabel = arrayOfLine[posOfClass]
distance = (attr - inputAttr) ** 2
distance = distance.sum(axis = 0)
distance = distance ** 0.5
disAndLabel = numpy.array([distance, classLabel])
refSamples = kNNFunction.insertItem(refSamples, numOfRefSamples, disAndLabel)
strOfLine = fr.readline()
continue
#統計每個類標簽出現的次數
classCount = {}
for i in range(numOfRefSamples) :
voteLabel = refSamples[i][1]
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
sortedClassCount = sorted(classCount.iteritems(), key = operator.itemgetter(1), reverse = True)
return int(sortedClassCount[0][0])
實現步驟為:讀取一條樣本,轉換為向量,計算這條樣本與輸入樣本的距離,將樣本插入到refSamples數組中,當然這里的樣本只是一個包含兩個元素的數組(距離和類標簽),而refSamples數組用于保存離輸入樣本最近的numOfRefSamples個參考樣本。當所有樣本都讀完之后,就找出了離輸入樣本最近的numOfRefSamples個參考樣本。其中kNNFunction.insertItem函數實現的是將得到的新樣本插入到refSamples數組中,主要采用類似冒泡排序的方法,實現代碼如下:
'''
insertItem(refSamples, numOfRefSamples, disAndLabel)函數
功能:
在參考樣本集中插入新樣本,這里的樣本是一個包含兩個數值的list,第一個是距離,第二個是類標簽
在參考樣本集中按照距離從小到大排列
參數:
refSamples:參考樣本集
numOfRefSamples:參考樣本集中的樣本總數
disAndLabel:需要插入的樣本數
'''
def insertItem(refSamples, numOfRefSamples, disAndLabel):
if (disAndLabel[0] < refSamples[numOfRefSamples - 1][0]) or (refSamples[numOfRefSamples - 1][0] < 0) :
refSamples[numOfRefSamples - 1] = disAndLabel
for i in (numpy.array([numOfRefSamples - 2] * (numOfRefSamples - 1)) - numpy.array(range(numOfRefSamples -1))) :
if (refSamples[i][0] > refSamples[i + 1][0]) or (refSamples[i][0] < 0) :
tempSample = list(refSamples[i])
refSamples[i] = refSamples[i + 1]
refSamples[i + 1] = tempSample
else :
break
return refSamples
else :
return refSamples
另外,需要注意的一點是要對輸入樣本的各條屬性進行歸一化處理。畢竟不同的屬性的取值范圍不一樣,取值范圍大的屬性在計算距離的過程中所起到的作用自然就要大一些,所以有必要把所有屬性映射到0和1之間。這就需要計算每個屬性的最大值和最小值,方法就是遍歷整個參考樣本集,找出最大值和最小樣本,這里用dataNorm函數是實現:
'''
歸一化函數,返回歸一化向量
'''
def dataNorm(trainSetPath = '', lenOfInstance = 42):
fr = open(trainSetPath)
strOfLine = fr.readline() #從文件中讀取的一行字符串
arrayOfLine = numpy.array([0.] * lenOfInstance) #用來保存與字符串對應的數組
maxAttr = numpy.array(['NULL'] * lenOfInstance) #用來保存每條屬性的最大值
minAttr = numpy.array(['NULL'] * lenOfInstance) #用來保存每條屬性的最小值
while strOfLine != '' :
strOfLine = strOfLine.strip() #去掉字符串末尾的換行符
strOfLine = strOfLine.split(';') #將字符串按逗號分割成字符串數組
abandonOrNot = False
for i in range(lenOfInstance) :
if strOfLine[i] == 'RB' :
arrayOfLine[i] = 1.0
elif strOfLine[i] == 'NRB' :
arrayOfLine[i] = 0.0
elif strOfLine[i] != '?' : #沒有發現缺失值
arrayOfLine[i] = float(strOfLine[i])
abandonOrNot = False
else : #發現缺失值
abandonOrNot = True
break
if abandonOrNot == True : #存在缺失值,丟棄
strOfLine = fr.readline()
continue
else : #沒有缺失值,保留
if maxAttr[0] == 'NULL' or minAttr[0] == 'NULL' : #maxAttr和minAttr矩陣是空的
maxAttr = numpy.array(arrayOfLine)
minAttr = numpy.array(arrayOfLine)
strOfLine = fr.readline()
continue
for i in range(lenOfInstance) :
if maxAttr[i] < arrayOfLine[i] :
maxAttr[i] = float(arrayOfLine[i])
if minAttr[i] > arrayOfLine[i] :
minAttr[i] = float(arrayOfLine[i])
strOfLine = fr.readline()
continue
return maxAttr, minAttr
至此為止,分類器算是完成,接下去就是用剩下的測試集進行測試,計算分類的準確度,用kNNTest函數實現:
def kNNTest(testSetPath = '', trainSetPath = '', lenOfInstance = 42, startAttr = 0, stopAttr = 40, posOfClass = 41):
fr = open(testSetPath)
strOfLine = fr.readline()
arrayOfLine = numpy.array([0.] * lenOfInstance)
succeedClassify = 0.0
failedClassify = 0.0
while strOfLine != '' :
strOfLine = strOfLine.strip()
strOfLine = strOfLine.split(';')
abandonOrNot = False
for i in range(lenOfInstance) :
if strOfLine[i] == 'RB' :
arrayOfLine[i] = 1.0
elif strOfLine[i] == 'NRB' :
arrayOfLine[i] = 0.0
elif strOfLine[i] != '?' : #沒有發現缺失值
arrayOfLine[i] = float(strOfLine[i])
abandonOrNot = False
else : #發現缺失值
abandonOrNot = True
break
if abandonOrNot == True :
strOfLine = fr.readline()
continue
else :
inputAttr = numpy.array(arrayOfLine)
classLabel = kNNClassify(inputAttr, trainSetPath = trainSetPath, lenOfInstance = 42, startAttr = startAttr,
stopAttr = stopAttr, posOfClass = posOfClass)
if classLabel == arrayOfLine[posOfClass] :
succeedClassify = succeedClassify + 1.0
else :
failedClassify = failedClassify + 1.0
strOfLine = fr.readline()
accuracy = succeedClassify / (succeedClassify + failedClassify)
return accuracy
最后,進行測試:
accuracy = kNN.kNNTest(testSetPath = 'D:\\python_project\\test_data\\QSAR-biodegradation-Data-Set\\biodeg-test.csv',
trainSetPath = 'D:\\python_project\\test_data\\QSAR-biodegradation-Data-Set\\biodeg-train.csv',
startAttr = 0, stopAttr = 40)
print '分類準確率為:',accuracy
輸出結果為:
分類準確率為: 0.847058823529
可見用kNN這種分類器的對這個數據集的分類效果其實還是比較一般的,而且根據我的測試,分類函數kNNClassify中numOfRefSamples(其實就是k-近鄰中k)的取值對分類準確度也有明顯的影響,大概在k取5的時候,分類效果比較理想,并不是越大越好。下面談談我對這個問題的理解:
首先,kNN算法是一種簡單的分類算法,不需要任何訓練過程,在樣本數據的結構比較簡單邊界比較明顯的時候,它的分類效果是比較理想的,比如:
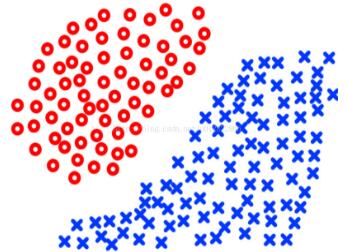
當k的取值比較大的時候,在某些復雜的邊界下會出現很差的分類效果,比如下面的情況下很多藍色的類會被分到紅色中,所以要用比較小的k才會有相對較好的分類效果:
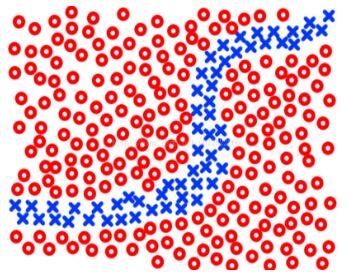
但是當k取得太小也會使分類效果變差,比如當不同類的樣本數據之間邊界不明顯,存在交叉的時候,比如:
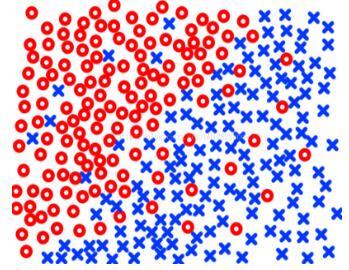
總的來說,kNN分類算法是一種比較原始直觀的分類算法,對某些簡單的情況有比較好的分類效果,并且不需要訓練模型。但是它的缺點是分類過程的運算復雜度很高,而且當樣本數據的結構比較復雜的時候,它的分類效果不理想。用kNN算法對本次實驗中的數據集的分類效果也比較一般,不過我試過其它更簡單一些的數據集,確實還是會有不錯的分類準確性的,這里就不贅述了。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





